

앞에서 클러스터드 인덱스와 넌클러스터드 인덱스의 차이점에 대해서 설명했습니다.
잠시, 클러스터드와 넌클러스터드의 차이는 잠시 접어두고 인덱스를 이용해 데이터 찾는 과정을 살펴보겠습니다.
1. 인덱스 탐색
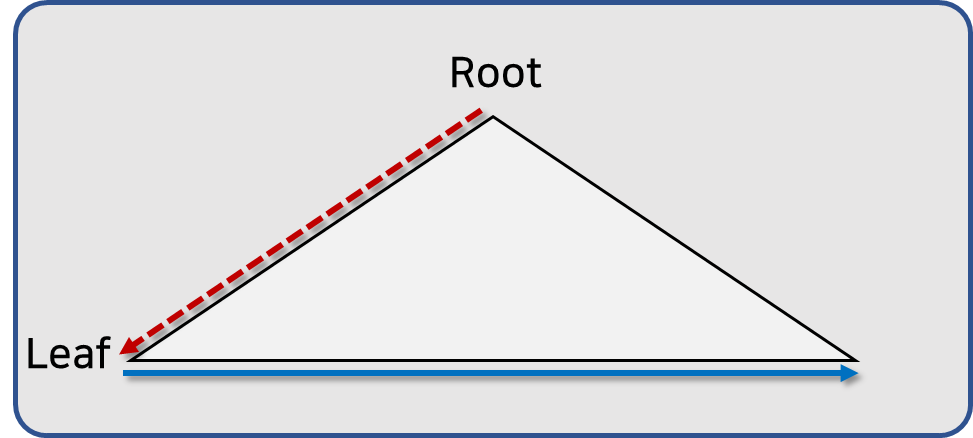
B Tree(B+Tree) 인덱스에서 조건에 맞는 값을 찾기 위해서는 두 단계의 과정으로 인덱스를 탐색합니다.
- 1 단계: 루트 노드에서 리프 노드로 내려가기(수직적 탐색)
- 2 단계: 리프 노드를 순차적으로 읽어 가기(수평적 탐색)
위의 과정을 그림으로 살펴보면 아래와 같습니다. 그림의 빨간색 화살표가 1 단계인 수직적 탐색이고, 파란색 화살표가 2 단계인 수평적 탐색입니다.
경우에 따라 2 단계는 생략될 수도 있습니다. 찾고자 하는 값이 한 건이거나, 극히 일부라면 2 단계 과정인 수평적 탐색은 생략될 수도 있습니다. (1 단계인 수직적 탐색으로 찾은 곳에 원하는 데이터가 모두 있다면, 수평적 탐색은 필요가 없는 경우죠.)

위 그림을 더 간략하게 그려보면 아래와 같습니다. 인덱스 동작 관련해서 자주 보게될 그림입니다.

방금 살펴본 설명과 그림이 바로, 우리가 흔이 말하는 '인덱스를 탔네'라고 말하는 것의 동작 방식입니다.
오라클의 실행 계획에서는 이와 같은 동작을 'INDEX RANGE SCAN'이라고 표현합니다.
반면에 MySQL에서는 실행 계획을 보는 방식과 상황에 따라 다양하게 표현이 됩니다. 관련해서는 다음 글에서 설명을 드릴 예정입니다.
위와 같은 인덱스 탐색 외에도, 인덱스 리프 노드를 차례대로 모두 읽어야 하는 경우가 있습니다. 해당 경우는 아래 그림과 같이 표시합니다. 오라클에서는 INDEX FULL SCAN이라고 동작하는 경우입니다.
오늘은 여기까지입니다. 감사합니다.
'SQL > MySQL' 카테고리의 다른 글
| [MySQL튜닝]힌트-조인순서 (0) | 2022.12.14 |
|---|---|
| [MySQL튜닝]넌클러스터드에서 클러스터드로 (0) | 2022.11.16 |
| [MySQL튜닝]MySQL의 인덱스 실행 계획 #2 (0) | 2022.11.15 |
| [MySQL튜닝]MySQL의 인덱스 실행 계획 #1 (0) | 2022.11.03 |
| [MySQL튜닝]Non Clustered vs. Clustered #2 (0) | 2022.10.26 |
| [MySQL튜닝]Non Clustered vs. Clustered #1 (0) | 2022.10.26 |
| [MySQL튜닝]B Tree 인덱스 (0) | 2022.10.24 |
| [MySQL튜닝]인덱스 왜 빨라? (0) | 2022.10.21 |