이번에는 주식을 어떤 요일에 사는게 좋은지, 과거 데이터를 간단히 집게해보도록 하겠습니다.
설명에 앞서 다음과 같은 사항을 기억해 주세요.
- 본 글은 주식 투자를 권장하거나, 어떤 종목을 추천하기 위한 글이 아닙니다.
- 본 글을 참고해 발생한 손실에 대해서는 누구도 책임지지 않습니다.
- 데이터의 정확성은 검토했지만, 다양한 이유로 일부 데이터가 부정확할수도 있으니 양해바랍니다.
년도별로 요일별 평균 수익률을 차트로 그려보면 다음과 같습니다.
각 요일에 종가(Close-Price)에 사서 다음날 시가(Open-Price)에 매도했다고 가정합니다.
월요일이 높은 년도도 있지만, 2011년에는 화요일이 월등합니다. 월요일은 마이너스이고요.
그리고 2015년에는 수요일이 높은 편으로 보입니다.
데이터를 더 갖다가 살펴볼 필요가 있어 보입니다. 예를 들어, 주식 시장의 전체 분위기가 좋으면 주초에 주로 오르고, 시장 분위기가 나쁘면, 주초가 별로인가.. 라는 추측이 듭니다. 나중에 지수 데이터를 연결해서 살펴봐야 할거 같네요.
위 차트를 년도 상관없이, 요일별로 평균을 구해보면 아래와 같습니다. 전체 평균을 봤을때는 화요일이 가장 좋네요.!
여기서는 각 요일별 종가에 매수한 후에, 다음날 시가에 바로 판 것을 가정했습니다.
이러한 집계 기준을 어떻게 정하는지에 따라 결과가 많이 달라질거 같습니다.
예를 들어, 월요일 종가가 아닌 시가에 샀다고 가정할 수도 있고, 사고 나서 일주일을 보유했다고 가정할 수도 있고요.
그리고 한국 시장이 아니라, 미국이나 중국이라면? 또 다른 결과가 나올까요? 나중에 기회가 되면 해봐야겠습니다.
이상입니다.!
역시 SQL로 간단히 구할 수 있습니다.
- 데이터 추출 기준: 2010년부터 2023년 8월까지의 한국 주식 시장의 주가 데이터
- 데이터 추출 방법: SQL
WITH W01 AS(
SELECT T1.STK_CD ,T1.DT
,T1.C_PRC B_PRC # BUY when Close price
,DAYOFWEEK(T1.DT) WK_NO
,CASE DAYOFWEEK(T1.DT)
WHEN 2 THEN 'MON'
WHEN 3 THEN 'TUE'
WHEN 4 THEN 'WED'
WHEN 5 THEN 'THU'
WHEN 6 THEN 'FRI' END WK
,LEAD(T1.O_PRC) OVER(PARTITION BY T1.STK_CD ORDER BY T1.DT ASC) S_PRC # SELL when next open Price
FROM HIST_DT T1
WHERE T1.DT >= '20100101'
AND T1.DT <= '20141231'
)
SELECT DATE_FORMAT(T1.DT,'%Y') YY
,T1.WK
,AVG(ROUND((T1.S_PRC - T1.B_PRC) / T1.B_PRC * 100, 2)) AVG_PROF
,COUNT(*) SAMP_CNT
FROM W01 T1
GROUP BY DATE_FORMAT(T1.DT,'%Y'), T1.WK
ORDER BY DATE_FORMAT(T1.DT,'%Y'), MAX(T1.WK_NO)
When is the time of day that working people are most interested in the stock market?
I think it's probably not during the morning hours when the stock market opens.
The stock market that opens after waiting overnight! You can't resist checking it out in the morning, can you?
When I check the stocks that are going up in the morning, my heart flutters. Oh, I should buy before they leave me behind!
When I look at the stocks that fall in the morning, I have a somewhat greedy thought. Oh! It fell, it's the price I've been waiting for. I should buy it!
Whether it's because the price dropped or went up, it seems like the "I have to buy it!" circuit in my brain is highly activated by morning.Not everyone may agree, but it is true that stock trading is most active in the morning when the stock market opens.
So, is it a good choice to buy stocks at the morning price, precisely the opening price (Open-Price)?
Let's find out through simple data aggregation.
Before explaining, I want to clarify that this is not an article recommending stock investment or suggesting any specific stock.
Please remember that no one is responsible for any losses incurred in the stocks invested in as a result of this article.
We have verified the accuracy of the data. However, please understand that there may be some inaccuracies due to errors that may have occurred during the data collection process or at the time of data collection.
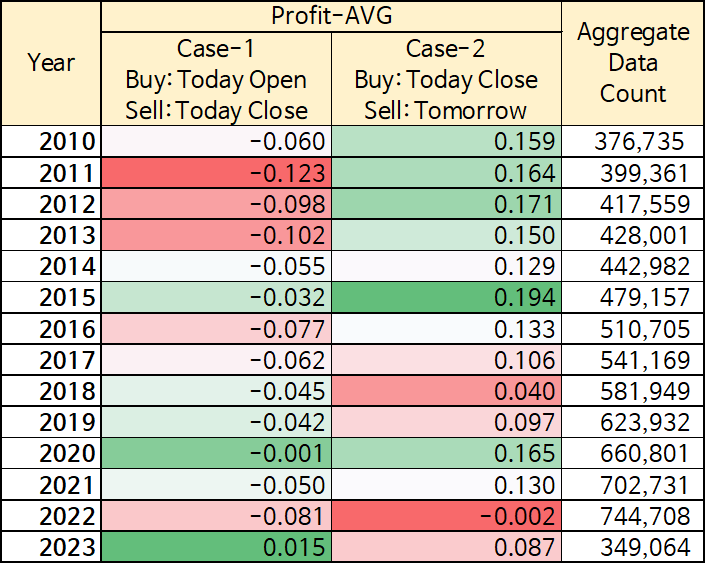
Let's use SQL to calculate the average profit rate for the following two trade cases:
Case 1: Buy at today's open price and sell at today's close price.
Case 2: Buy at today's close price and sell at tomorrow's open price.
Actually, we can't buy and sell stocks every day like in the example above, right? However, if we aggregate the data, we can find some useful information for our investment.
If we use the daily stock price data I have (Korea) and aggregate it by year, the following results are obtained:
Overall, it can be seen that Case2 [Buy at today's closing price and sell at tomorrow's opening price] has a much better average return rate than Case1. Buying at today's opening price and selling at today's closing price, like in Case1, results in mostly negative returns on average.
This test is completely meaningless for those who invest in value. If you approach investing from a perspective of investing in really good companies, it doesn't matter whether you buy in the morning or in the evening. However, I think this is useful information to refer to when buying stocks.
Conclusion! Buy at the closing price!
The above result can be easily implemented with the following SQL. Are you all studying SQL?
WITH W01 AS(
SELECT T1.STK_CD ,T1.DT ,T1.C_PRC ,T1.O_PRC
,LEAD(T1.O_PRC) OVER(PARTITION BY T1.STK_CD ORDER BY T1.DT ASC) AF_O
,LEAD(T1.C_PRC) OVER(PARTITION BY T1.STK_CD ORDER BY T1.DT ASC) AF_C
FROM HIST_DT T1
WHERE T1.DT >= '20210101'
AND T1.DT <= '20211231'
ORDER BY T1.DT DESC
)
,W02 AS(
SELECT T1.*
,ROUND((T1.C_PRC - T1.O_PRC) / T1.O_PRC * 100,1) `OPEN_CLOSE`
,ROUND((T1.AF_O - T1.C_PRC) / T1.C_PRC * 100,1) `CLOSE_OPEN`
FROM W01 T1
)
SELECT DATE_FORMAT(T1.DT,'%Y')
,AVG(`OPEN_CLOSE`) `CASE1_OPEN_CLOSE`
,AVG(`CLOSE_OPEN`) `CASE2_CLOSE_OPEN`
,COUNT(*) CNT
FROM W02 T1
GROUP BY DATE_FORMAT(T1.DT,'%Y');
실제, 위의 예처럼 매일매일 사고 팔수는 없겠죠? 그래도 데이터를 집계해보면, 우리가 투자에 참고할만한 정보가 나온답니다.
제가 보유한 일별 주가 데이터(한국)를 사용해 년별로 집계해보면 아래와 같은 결과가 나옵니다.
전체적으로 Case2[오늘 종가(Close Price) Buy - 내일 시가(Open Price) Sell]가 Case1보다 평균 수익률이 훨씬 좋은 것을 알 수 있습니다.Case1과 같이 오늘시가에 사서 오늘종가에 파는 경우는 평균적으로 마이너스 수익률인 경우가 대부분입니다.
가치투자를 하시는 분들께는 이런 테스트는 완전히 무의미합니다. 정말 좋은 기업에 투자 관점을 가지고 접근하시는 거라면 아침에 사든, 저녁에 사든 중요하지 않으니까요. 하지만, 자신이 주식을 살때 한 번쯤은 참고할 만한 정보라고 생각합니다.
결론! 종가에 사자!
위 결과는 아래의 SQL로 간단하게 구현할 수 있답니다. 다들, SQL 공부 하고 계시죠?
WITH W01 AS(
SELECT T1.STK_CD ,T1.DT ,T1.C_PRC ,T1.O_PRC
,LEAD(T1.O_PRC) OVER(PARTITION BY T1.STK_CD ORDER BY T1.DT ASC) AF_O
,LEAD(T1.C_PRC) OVER(PARTITION BY T1.STK_CD ORDER BY T1.DT ASC) AF_C
FROM HIST_DT T1
WHERE T1.DT >= '20210101'
AND T1.DT <= '20211231'
ORDER BY T1.DT DESC
)
,W02 AS(
SELECT T1.*
,ROUND((T1.C_PRC - T1.O_PRC) / T1.O_PRC * 100,1) `오늘시가_오늘종가`
,ROUND((T1.AF_O - T1.C_PRC) / T1.C_PRC * 100,1) `오늘종가_내일시가`
FROM W01 T1
)
SELECT DATE_FORMAT(T1.DT,'%Y')
,AVG(`오늘시가_오늘종가`) `CASE1_오늘시가_오늘종가`
,AVG(`오늘종가_내일시가`) `CASE2_오늘종가_내일시가`
,COUNT(*) CNT
FROM W02 T1
GROUP BY DATE_FORMAT(T1.DT,'%Y');
TwelveData에서는 다양한 국가(미국, 한국, 중국, 일본, 유럽 곳곳까지)의 종목 정보를 가져올 수 있어서 매우 좋은거 같습니다. 그리고, 파이썬 코딩도 비교적 간단합니다. (저만 알고 싶은 곳이지만, 과감히 올려봅니다.) 또한 TwelveData에서는 종목 정보 외에도 주가 정보를 가져올 수 있는데, 무료 정책으로 하루에 800번의 API호출이 가능합니다. 현재 저는 무료 정책을 사용중이며, 주요 종목의 주가를 일별로 추적하기에는 800번의 API 호출이면 충분한거 같습니다.(단, 1분에 8번 제한이 있습니다.)
종목 정보를 가져오는 파이썬 소스는 아래와 같습니다. 참고하셔서 각자 환경에 맞게 개발하시면 될거 같습니다.
감사합니다.
import requests
import pandas as pd
def GetStockListFromTwelveData(_country, _type):
url = "https://api.twelvedata.com/stocks"
response = requests.get(url)
js_txt = response.json()
df = pd.DataFrame(js_txt['data']) # dict에서 js_txt 키에 해당하는 값만 가져오기
# print(df.country.unique()) 국가 값 종류 확인
# print(df.type.unique()) Type 값 종류 확인
# print(df.columns) # 컬럼 정보 확인
df2 = df[(df.country == _country) & (df.type == _type)] # 특정조건 값 가져오기
return df2
# Contry
# ['Germany' 'China' 'South Korea' 'Hong Kong' 'Malaysia' 'Taiwan' 'India'
# 'United Kingdom' 'Italy' 'Mexico' 'Saudi Arabia' 'Poland' 'Japan''Sweden'
# 'Philippines' 'Thailand' 'Netherlands' 'Denmark' 'Spain''Hungary' 'South Africa'
# 'Brazil' 'Ireland' 'Canada' 'United States''Greece' 'Romania' 'Indonesia' 'Finland'
# 'Switzerland''United Arab Emirates' 'Kuwait' 'Argentina' 'Chile' 'Colombia'
# 'New Zealand' 'Belgium' 'Israel' 'Qatar' 'Russia' 'Botswana' ''
# 'Turkey''Portugal' 'Lithuania' 'Czech Republic' 'Estonia' 'Iceland' 'Latvia''Egypt']
# Type
# ['Common Stock' 'American Depositary Receipt' 'REIT' 'Unit'
# 'Global Depositary Receipt' 'Depositary Receipt' 'Preferred Stock'
# 'Limited Partnership' 'Structured Product' 'Right' 'Warrant' 'Trust'
# 'ETF' 'Mutual Fund']
pd.set_option('display.max_columns',None) # df 출력시 모든 컬럼 출력하도록 처리
pd.set_option('display.width',1000) # df 출력시, 한 로우가 따로 출력되지 않도록 충분한 길이 설정
df = GetStockListFromTwelveData('United States','Common Stock')
# Columns:
print(df)
정말 많은 사람들에게 힘든 주식 시장 같습니다. 이럴때일수록 공부를 열심히 하자라는 생각으로 다양한 책들을 살펴보고 있습니다. 지금까지 개인적으로 중장기 보유의 '투자' 관점에서 주식을 많이 접근했었는데요, 요즘에는 '매매'(트레이딩) 관점으로 공부를 좀 해보고 있습니다.
특정 종목 Z를 단순 보유한 경우와 추세추종으로 트레이딩한 경우의 수익을 비교해 봤습니다.(종목을 밝히지 않는 이유는, 속상하신 분도 있을 수 있으니 T.T)
이 글의 차트 보는 법에 대해 먼저, 정리드리면 - 검은색 점선: 해당 종목을 단순 보유할 경우 수익 변화입니다.(최초 천원어치 만큼 매수했다고 가정합니다.) - 보라색 선: 트레이딩에 따른 수익 변화(최초 천원으로 계속 매매한 경우 수익 변화입니다.) - 빨간 세로선: 트레이딩시 매수(Buy) 신호입니다. - 파란 세로선: 트레이딩시 매도(Sell) 신호입니다. - 여기서, 트레이딩은 제가 개인적으로 만든 추세추종 규칙입니다.
1. 2019~2019.12.31 - 단순 보유: 58% VS. 트레이딩 수익률: 7% - 이 결과를 보면, 트레이딩 로직이 한참 문제가 있거나, 역시 단순 보유가 답일 수 있습니다.
2. 2019~202012.31 - 단순 보유: 220% VS. 트레이딩 수익률: 91% - 역시나, 트레이딩 로직이 한참 문제가 있거나, 역시 단순 보유가 답일 수 있습니다.
3. 2019 ~ 2022.9.30(현재) - 2019 ~ 2021.12.30은 생략했습니다. - 단순 보유: 63% VS. 트레이딩 수익률: 91% - 트레이딩 로직이 추세추종이기 때문에, 추세가 꺽인 시점에서는 더 이상 매수 신호가 나오지 않습니다.
지금까지의 차트를 살펴보면, 어떤 기간에는 단순 보유가, 그리고 지금과 같은 하락장에는 규칙적인 추체추종이 오히려 수익을 보존해주는 것을 알 수 있습니다. (물론, 위 차트는 특정 종목 하나이므로, 모든 종목에 해당한다 할 수는 없겠죠.)
위 결과만 보면, 단순 보유하다가 하락기 시작에 판다면 가장 좋은 성과를 얻을 수 있습니다. 하지만 그 시점에 과연 팔 수 있었을지는 아무도 모릅니다. 보통 내려가는 종목 보면, '휙 내리고 > 희망 고문 > 휙 내리고 > 희망 고문'의 반복이기 때문에 매도가 쉽게 나오지 못합니다.
혹시라도, 단순 보유 전략을 2021년부터 시작했다면 어떻게 될까요? 4. 2021 ~ 2022.9.30(현재) - 단순 보유: -33% VS. 트레이딩 수익률: 5% - 트레이딩의 수익이 좋지는 못합니다. 하지만, 2021부터 지금까지 보유했다면, 정말 힘든 상황이죠.
특정 시점과, 특정 종목 하나로 일반화하기는 어렵지만, 규칙적인 트레이딩이 대박은 아니더라도 중박은 유지할 수 있으며, 수익을 유지할 수 있는 방법인가라고 생각이 들기도 합니다. 물론 종목 선정과 기본적인 매매 규칙을 잘 만들고 지켜야만 이 마저도 수익을 얻을 수 있겠죠.
어쨋든! 트레이딩을 위해서는 더더욱 파이썬과 SQL 능력, 데이터를 분석하는 능력을 갈고 닦을 필요가 있다는 생각이 듭니다. 이상입니다.^^
메모리 품목 수출 데이터와, SK 하이닉스의 월별 주가(월별 시작가격을 사용합니다.)를 섞어서 차트로 그려보면 아래와 같습니다.
그림을 살펴보면, 메모리 수출 금액과 SK하이닉스의 주가 움직임이 거의 유사해 보입니다. 구간별로 나누어서 정리해보면 아래와 같습니다.
2008년 11월부터 2017년 11월까지는 메모리(디램) 수출의 흐름과 SK하이닉스의 주가 움직임이 거의 유사한 것을 알 수 있습니다. 하지만, 2017년 12월부터는 메모리 수출이 최대치를 찍었지만, 주가는 그만큼 오르지 못했습니다. 아마도. 미중무역전쟁 때문 아닐까 싶습니다. 수출 역시, 미중무역전쟁으로 서둘러 메모리 수출이 된건 아닐까 하는 개인적으로 생각을 해봅니다.
2018년 11월부터 2020년 9월까지는 수출과 반대로 주가는 오르기도 했습니다. 일본과 우리나라 사이에 반도체 소재 관련 이슈때문이었나 생각도 듭니다.
결론적으로... 과거에는 메모리 수출과 SK하이닉스는 거의 비례해서 움직였지만, 2017년부터는 그렇지 못한거 같습니다. 다시 메모리 수출과 SK하이닉스 주가가 비례해서 움직일지는 더 지켜봐야 알 수 있을거 같습니다.
그러므로, 메모리 수출에 따라, SK하이닉스 투자를 결정하기에는 좀 어려워보입니다.
추가로, SK하이닉스 보유기간에 따른 수익률을 분석해봤습니다. 원리나 로직은 이전 글을 참고해주세요.
SK하이닉스를 6개월 보유한 경우 월별 수익률 차트입니다. 수익률이 좋은 경우도 있지만, 수익률이 좋지 못한 경우도 제법 있습니다.
보유 기간을 늘려서 분석해봤습니다. 아래는 12개월 보유한 경우입니다. 6개월 보유한 경우보다는, 12개월 보유한 경우가 수익률이 좀 더 안정적인 것으로 보입니다. 하지만, 지금 매수 하기에는 여전히 불안한 시점으로 보입니다.
이처럼 SK하이닉스를 분석해봤지만, 단기간 가격이 많이 빠지긴 했지만, 매수하기 좋은 시점은 아닌거 같습니다. 다시 말씀드리지만, 개인적인 생각이니, 각자 투자에 참고하시는 정도로만 읽어주시기 바랍니다. 이상입니다.
이처럼, 데이터를 분석하는 과정을 공부해보고 싶으신 분은 아래의 '평생 필요한 데이터 분석'의 교육 과정을 추천합니다. 교육을 통해 SQL을 배운다면, 위 내용을 좀 더 보강할 수도 있고, 자신만의 스타일로 분석을 할 수 있습니다. SQL을 완전히 자신의 것으로 만들 수 있는 교육이니 관심 가져보시기 바랍니다. 감사합니다.~!
설명에 앞서, 절대 어떤 종목을 추천하기 위한 글이 아니며, 본 글로 인해 투자한 종목의 손실에 대해서는 절대 누구도 책임지지 않는다는 것을 기억해주시기 바랍니다.
데이터의 정확성 역시 일차적으로는 검토했지만, 데이터 수집 시점이나 과정에서 발생한 실수로 부정확할수도 있으니 양해바랍니다.
방법은 아래와 같습니다.
1. 2010년1월의 시가(시작가격)로 매수, 6개월 보유 후, 2010년 7월의 시가로 매도
2. 2010년 2월의 시가로 매수, 6개월 보유, 2010년 8월 시가로 매도
3. LG생활건강의 모든 월별 주가에 대해 위와 같이 처리
위와 같은 로직으로 각 월별로 6개월 보유후 매도했을 때의 등락률(수익률)을 구해서 차트를 그려봅니다. 위에서 설명한 결과를 만다는 SQL은 아래와 같습니다.(아래는 오라클 기준의 SQL입니다. MySQL도 크게 다르지 않습니다.)
SELECT T1.STK_CD ,T1.STK_NM
,REGEXP_REPLACE(T_SELL.YM,'(.{4})(.{2})','\1-\2') 매도월
,T_SELL.O_PRC 매도가격
,ROUND((T_SELL.O_PRC - T_BUY.O_PRC) / T_BUY.O_PRC * 100,2) 등락률
,REGEXP_REPLACE(T_BUY.YM,'(.{4})(.{2})','\1-\2') 매수월
,T_BUY.O_PRC BUY_PRC -- 시가 사용
FROM ORA_STK_USER.M_STK T1
,ORA_STK_USER.FT_STK_YM T_SELL
,ORA_STK_USER.FT_STK_YM T_BUY
WHERE T1.STK_CD = T_SELL.STK_CD
AND T1.STK_NM = 'LG생활건강'
AND T_BUY.STK_CD = T1.STK_CD
AND T_BUY.YM = TO_CHAR(ADD_MONTHS(TO_DATE(T_SELL.YM||'01','YYYYMMDD'),-6),'YYYYMM')
ORDER BY T_SELL.YM ASC
위 SQL을 통해 아래와 같은 결과를 얻을 수 있습니다. 첫 번째 결과 데이터를 보면, 2010년에 1월에 매수해서 2010년 7월에 매도했을 경우, 등락률(수익률)이 20.27%입니다. 두 번째 결과 데이터는 2010년 2월에 매수해서 2010년 8월에 매도한 경우로 등락률이 30.68%입니다.
위 결과를 통해서는, 딱히 투자를 어떻게 해야 할까 방향을 잡기도 쉽지 않습니다. 데이터 분석과 활용을 위해서는 테이블 형태의 데이터를 차트화할 필요가 있습니다. 위 결과를 엑셀로 내려받아 차트를 만들어 보면 아래와 같습니다.
그림에서, 녹색바는 6개월 보유후 매도했을 때의 등락률(수익률)입니다. 파란색 선은 해당월의 시작가격입니다.
그림을 보시면, LG생건의 경우, 6개월 보유했을때, 손실나는 경우보다 수익나는 경우가 전반적으로 더 많습니다.
또한, 과거 최대 손실이 -30과 -50 사이입니다. 그러므로 6개월전 대비 -30~-50 사이로 주가가 내려간 시점이라면 매수할만 하지 않을까 생각해 볼 수 있습니다. (더이상 손실 나는 케이스는 잘 없었으니까요.)
그래서, 저역시, 올해 22년 3월 경에 자신있게 매수했더랍니다. 하지만. 역시!!! 보기 좋게 더 미끄러지고 말았습니다. (그림을 보면서 더 생각해보면, 더 기다렸다가, 6개워 등락률이 차차 올라가 다시 0보다 커지기 시작하는 시점에 매수하면 좀더 안정적이지 않았을까 싶습니다.)
항상 그런 거은 아니지만, LG생건의 경우 중국에 따라 주가 움직임의 영향이 큰 것으로 보입니다. 많은 분들도 기본적으로 그렇게 알고 있으리라 생각합니다.
현재, LG 생건에게 호재는 실외마스크 해제와 가격이 너무 많이 빠졌다, 그리고 해외 여행이 시작되었다. 정도입니다.
반면에, 악재를 생각해보면, 금리인상, 러시아 전쟁, 인플레이션, 양적완화 축소, 상하이 봉쇄, 중국 아시안게임 연기가 있습니다. 호재를 능가할만한 악재들이지 않나 싶습니다.
주식 투자라는게 참 어렵습니다. 지난 통계나 가격을 살펴보면, 분명히 사야할 시점 같지만, 다양한 경제 현황을 살펴보면 사면 안되는 시점이기도 합니다. 결국 어찌해야 할지는 본인이 장고끝에 결정을 내려야 한다고 봅니다.
위와 같은 보유개월별, 수익률 변화는 결정을 내리는데 참고 정보로 사용할만하지 않을까 싶습니다.
이상입니다.
이처럼, 데이터를 분석하는 과정을 공부해보고 싶으신 분은 아래의 '평생 필요한 데이터 분석'의 교육 과정을 추천합니다. 교육을 통해 SQL을 배운다면, 위 내용을 좀 더 보강할 수도 있고, 자신만의 스타일로 분석을 할 수 있습니다. SQL을 완전히 자신의 것으로 만들 수 있는 교육이니 관심 가져보시기 바랍니다.
설명에 앞서, 절대 어떤 종목을 추천하기 위한 글이 아니며, 본 글로 인해 투자한 종목의 손실에 대해서는 절대 누구도 책임지지 않는다는 것을 기억해주시기 바랍니다.
데이터의 정확성 역시 일차적으로는 검토했지만, 데이터 수집 시점이나 과정에서 발생한 실수로 부정확할수도 있으니 양해바랍니다.
여기서는 실제 금리인상의 추세와 주가의 추세를 연결짓지 않고, 구글트렌드를 활용해, '금리인상' 키워드에 대한 트레드와 주요 주가의 추세를 연결해서 분석해보려고 합니다. (구글 트렌드는 투자에서도 여러모로 쓸모가 있답니다.)
먼저 구글 트렌드에 접속해 '금리인상'에 대해 검색을 합니다. 최대한 오랜 기간의 데이터를 검색합니다.
2022년5월5일(어린이날에 글을 올리고 있군요.!) 기준으로 아래와 같이 결과가 나옵니다.
살펴보니, 2010년 중반과, 2015년 말에 금리인상에 대한 키워드가 위로 튄 것을 알 수 있습니다. 그리고, 현재, 2022년 역시, 강력하게 금리인상에 대한 관심도가 강력하게 치솟고 있습니다.
금리인상 관심도가 증가했다는 것은, 금리인상을 실제 했다는 뜻이겠죠. 위의 데이터를 엑셀로 다운받아 봅니다.
다운해보면, 가장 높은 관심도가 100이 되고, 나머지는 100에 비례한 비율로 수치가 만들어져 있습니다. 이제 엑셀로 다운받은 '금리인상' 관심도와 주가를 엮어서 분석해볼 차례입니다. 내부적으로는 모든 종목을 해볼 수도 있겠지만, 여기서는 아래 종목들만 추려서 분석해보려고 합니다.
우리나라 대표 종목인 삼성전자
우리나라 금융 대표 종목인 KB금융
우리나라 빅테크 대표 종목인 네이버
우리나라 지수 대표 ETF인 KODEX 200
위 종목들의 월별 주가를 아래 SQL로 다운 받을 수 있습니다.(제가 별도 관리하고 있는 월별주가 데이터입니다.)
쿼리에 대한 설명은 복잡하므로 생략합니다.^^ 주가를 실제 가격이 아닌 최대 가격에 비례한 비율로 데이터를 처리한다는 점만 주의하면 될거 같습니다.
WITH R01 AS(
SELECT T1.YM
,MAX(CASE WHEN T2.STK_NM = 'KODEX 200' THEN T1.O_PRC END) PRC_KODEX
,MAX(CASE WHEN T2.STK_NM = '삼성전자' THEN T1.O_PRC END) PRC_SAM
,MAX(CASE WHEN T2.STK_NM = 'KB금융' THEN T1.O_PRC END) PRC_KB
,MAX(CASE WHEN T2.STK_NM = 'NAVER' THEN T1.O_PRC END) PRC_NAVER
,MAX(MAX(CASE WHEN T2.STK_NM = 'KODEX 200' THEN T1.O_PRC END)) OVER() PRC_KODEX_MAX
,MAX(MAX(CASE WHEN T2.STK_NM = '삼성전자' THEN T1.O_PRC END)) OVER() PRC_SAM_MAX
,MAX(MAX(CASE WHEN T2.STK_NM = 'KB금융' THEN T1.O_PRC END)) OVER() PRC_KB_MAX
,MAX(MAX(CASE WHEN T2.STK_NM = 'NAVER' THEN T1.O_PRC END)) OVER() PRC_NAVER_MAX
FROM ORA_STK_USER.FT_STK_YM T1
,ORA_STK_USER.M_STK T2
WHERE T1.STK_CD = T2.STK_CD
AND T2.STK_NM IN ('KODEX 200','삼성전자','KB금융','NAVER')
GROUP BY T1.YM
ORDER BY T1.YM
)
SELECT T1.YM
,NVL(ROUND(T1.PRC_KODEX/T1.PRC_KODEX_MAX * 100,1),0) KODEX
,NVL(ROUND(T1.PRC_SAM/T1.PRC_SAM_MAX * 100,1),0) SAM
,NVL(ROUND(T1.PRC_KB/T1.PRC_KB_MAX * 100,1),0) KB
,NVL(ROUND(T1.PRC_NAVER/T1.PRC_NAVER_MAX * 100,1),0) NAVER
FROM R01 T1
WHERE T1.YM >= '200401'
ORDER BY T1.YM;
위 결과와, 구글트렌드에서 다운받은 금리인하 트렌드 엑셀과 연결해서 차트를 그려보면 아래와 같습니다.
금리인상 트렌드는 굵은 파란색 선입니다. 2004년부터 2022년까지의 관심 트렌드와 주요 주가가 월별로 나타나 있습니다.
살펴보면, 금리인상 관심 트렌드가 튄 시점 이후로, 삼성전자, KB금융, KODEX 200(삼성전자 영향이 크겠죠.) 모두 상승 흐름인 것으로 보입니다. 반면에 우리나라 빅테크 기업인 NAVER는 주가가 흐르거나, 딱히 오르지 않는것도 알 수 있습니다.
이를 통해,
"금리인상과 금융주가 상관관계가 있다. 삼성전자와 같은 우량주도 괜찮다. NAVER와 같은 테크 기업은 좋지 않을 수 있다." 라고 생각할 수 있습니다. 하지만, 이와 같은 과거 데이터 분석이 항상 미래에도 똑같을 것이라고 장담할 수는 없습니다. 저희는 단지, 위 내용을 참고해 자신만의 투자 전략을 세워야 한다고 생각합니다.
앞으로 펼쳐질 미래에는 정반대로 갈 수도 있으니, 이에 대한 시나리오도 세우고 투자를 해야 한다고 생각합니다.
이처럼, 데이터를 분석하는 과정을 공부해보고 싶으신 분은 아래의 '평생 필요한 데이터 분석'의 교육 과정을 추천합니다. 교육을 통해 SQL을 배운다면, 위 내용을 좀 더 보강할 수도 있고, 자신만의 스타일로 분석을 할 수 있습니다. 좀 비싼 교육이긴 하지만, SQL을 완전히 자신의 것으로 만들 수 있는 교육이니 관심 가져보시기 바랍니다.
M_YM_01에는 아래와 같이 CONNECT BY를 사용해 2019년 1월부터 2021년 12월까지의 데이터를 입력합니다.
INSERT INTO M_YM_01(YM)
SELECT TO_CHAR(ADD_MONTHS(TO_DATE('20190101','YYYYMMDD'),ROWNUM-1),'YYYYMM') YM
FROM DUAL T1
CONNECT BY TO_CHAR(ADD_MONTHS(TO_DATE('20190101','YYYYMMDD'),ROWNUM-1),'YYYYMM') <= '202112'
COMMIT;
데이터 입력을 완료했으면, 우선은 아래 SQL을 사용해 T_SALE_YM_01의 데이터를 2019년 12월부터 2020년 2월까지 조회해봅니다.
SELECT TSAL.SALE_YM
,TSAL.ITEM_ID
,TSAL.SALE_QTY
FROM T_SALE_YM_01 TSAL
WHERE TSAL.SALE_YM BETWEEN '201912' AND '202002'
ORDER BY TSAL.SALE_YM ,TSAL.ITEM_ID;
[결과]
SALE_YM ITEM_ID SALE_QTY
------- ----------- ---------
202001 G1B 18
202001 M9B 100
202001 M9R 45
202001 W3B 30
202002 G1B 15
202002 M9B 50
202002 M9R 25
202002 W3B 19
결과를 보면 2019년 12월 데이터가 존재하지 않습니다. T_SALE_YM_01에는 2020년 데이터만 존재하기 때문입니다. 판매가 없는 2019년 12월 데이터도 0으로 보여주고 싶다면, 아래와 같이 M_YM_01과의 아우터 조인을 고려해야 합니다.
SELECT T1.YM
,TSAL.ITEM_ID
,TSAL.SALE_QTY
FROM M_YM_01 T1
,T_SALE_YM_01 TSAL
WHERE T1.YM BETWEEN '201912' AND '202002'
AND TSAL.SALE_YM(+) = T1.YM
ORDER BY T1.YM ,TSAL.ITEM_ID;
[결과]
YM ITEM_ID SALE_QTY
------ ------------- ---------
201912 <null> <null>
202001 G1B 18
202001 M9B 100
202001 M9R 45
202001 W3B 30
202002 G1B 15
202002 M9B 50
202002 M9R 25
202002 W3B 19
결과를 보면, 2019년 12월 데이터가 조회되긴 했지만 ITEM_ID와 SALE_QTY가 NULL 값으로 한 건만 조회가 되었습니다. ITEM_ID 값을 T_SALE_YM_01에서 가져와야 하는데, 2019년 12월에 데이터가 없기 때문에 조회되지 않습니다. 그러므로, M_YM_01과 M_ITEM_01을 카테시안 조인으로 연월, 아이템별 데이터 집합을 생성한 후에 아우터 조인을 처리해야 합니다. 연월, 아이템별 데이터 집합을 만드는 카테시안 조인 SQL을 살펴보면 아래와 같습니다.
SELECT T1.YM
,T2.ITEM_ID
FROM M_YM_01 T1
,M_ITEM_01 T2
WHERE T1.YM BETWEEN '201912' AND '202002'
ORDER BY T1.YM ,T2.ITEM_ID;
[결과]
YM ITEM_ID
------ -------------
201912 G1B
201912 M9B
201912 M9R
201912 W3B
202001 G1B
202001 M9B
202001 M9R
202001 W3B
202002 G1B
202002 M9B
202002 M9R
202002 W3B
결과를 보며, 2019년 12월도 아이템별 데이터가 만들어진 것을 알 수 있습니다. SQL을 살펴보면 두 테이블을 연결하는 조인 조건이 없습니다. 이처럼 카테시안 조인을 위해서는 두 테이블을 연결하는 조인 조건을 주지 않습니다. 일반적으로 ANSI 구문을 사용할 때는, 카테시안 조인 처리를 위해 아래와 같이 CROSS JOIN을 사용합니다.
SELECT T1.YM
,T2.ITEM_ID
FROM M_YM_01 T1
CROSS JOIN M_ITEM_01 T2
WHERE T1.YM BETWEEN '201912' AND '202002'
ORDER BY T1.YM ,T2.ITEM_ID;
마지막으로 2019년 12월부터 2020년 2월까지 연월별, 아이템별 판매 데이터를 조회하기 위해서는 아래와 같이 SQL을 사용하면 됩니다. 카테시안 조인으로 만들어낸 연월별, 아이템별 데이터 집합에 아우터 조인을 사용해 실적 데이터를 연결해주면 됩니다.
SELECT T0.*
,NVL(T1.SALE_QTY,0) SALE_QTY
FROM (
SELECT T1.YM
,T2.ITEM_ID
FROM M_YM_01 T1
,M_ITEM_01 T2
WHERE T1.YM BETWEEN '201912' AND '202002'
ORDER BY T1.YM ,T2.ITEM_ID
) T0
,T_SALE_YM_01 T1
WHERE T1.SALE_YM(+) = T0.YM
AND T1.ITEM_ID(+) = T0.ITEM_ID
ORDER BY T0.YM ,T0.ITEM_ID;
[결과]
YM ITEM_ID SALE_QTY
------ ------------ ---------
201912 G1B 0
201912 M9B 0
201912 M9R 0
201912 W3B 0
202001 G1B 18
202001 M9B 100
202001 M9R 45
202001 W3B 30
202002 G1B 15
202002 M9B 50
202002 M9R 25
202002 W3B 19
오늘은 여기까지입니다. 존재하지 않는 실적 데이터를 결과에 포함하기 위해서는 이처럼 카테시안 조인으로 분석 마스터가 될 수 있는 차원을 만들수 있어야 합니다.
위와 같이 데이터를 마음대로 분석해볼 수 있는 SQL을 공부하고 싶다면 아래 책을 참고해주세요~!
자기 자신과 조인하는 것을 셀프 조인(Self Join)이라고 합니다. INNER JOIN이나 OUTER JOIN처럼 조인 문법이나 방법으로 존재하는 것이 아니라, 조인 대상에 따라 셀프 조인을 특정해서 부릅니다. 다시 말해, 'TAB1 JOIN TAB1'과 같이 TAB1끼리 조인하는 것을 셀프 조인이라고 합니다.
앞에서 만든 T_SALE_YM_01 테이블을 사용한 예제를 살펴보겠습니다. 아래 예제는 T_SALE_YM_01을 조회하면서, 3개월전 판매 수량을 가져오고, 현재와 3개월전 판매 수량을 비교해 판매가 얼만큼 증감했는지 조회하는 SQL입니다.
SELECT T1.ITEM_ID
,T1.SALE_YM ,T1.SALE_QTY
,T2.SALE_YM BF3_YM ,T2.SALE_QTY BF3_QTY
,ROUND(T1.SALE_QTY / T2.SALE_QTY * 100,2) BF3_NW_SALE_RT
FROM T_SALE_YM_01 T1
LEFT OUTER JOIN T_SALE_YM_01 T2
ON (T2.ITEM_ID = T1.ITEM_ID
AND T2.SALE_YM = TO_CHAR(ADD_MONTHS(TO_DATE(T1.SALE_YM||'01','YYYYMMDD'),-3),'YYYYMM'))
WHERE T1.ITEM_ID = 'M9B'
ORDER BY T1.SALE_YM;
위 SQL을 살펴보면, FROM 절의 LEFT OUTER JOIN을 중심으로 왼쪽과 오른쪽에 모두 T_SALE_YM_01 테이블을 사용하고 있습니다. 그러므로 셀프 조인이 됩니다. 위 SQL은 ANSI 기준 문법으로 작성했는데요, 아래와 같이 (+)만 추가하면 손쉽게 오라클 기준의 아우터 조인으로 변경할 수 있습니다.
SELECT T1.ITEM_ID
,T1.SALE_YM ,T1.SALE_QTY
,T2.SALE_YM BF3_YM ,T2.SALE_QTY BF3_QTY
,ROUND(T1.SALE_QTY / T2.SALE_QTY * 100,2) BF3_NW_SALE_RT
FROM T_SALE_YM_01 T1
,T_SALE_YM_01 T2
WHERE T1.ITEM_ID = 'M9B'
AND T2.ITEM_ID(+) = T1.ITEM_ID
AND T2.SALE_YM(+) = TO_CHAR(ADD_MONTHS(TO_DATE(T1.SALE_YM||'01','YYYYMMDD'),-3),'YYYYMM')
ORDER BY T1.SALE_YM;
T1의 값들에 3개월 전 판매수량(T2)이 연결된 것을 알 수 있습니다. 이때, 2020년 1월의 3개월전인 2019년 데이터는 T_SALE_YM에 존재하지 않으므로 NULL로서 결과가 나온 것을 확인할 수 있습니다.
이처럼 자기 자신과 이루어지는 조인을 흔히 셀프 조인이라고 부릅니다.
위 SQL은 아래와 같이 LEAD 분석함수로도 해결 할 수 있습니다.
SELECT T1.ITEM_ID
,T1.SALE_YM ,T1.SALE_QTY
,LEAD(T1.SALE_YM,3) OVER(ORDER BY T1.SALE_YM DESC) BF3_YM
,LEAD(T1.SALE_QTY,3) OVER(ORDER BY T1.SALE_YM DESC) BF3_QTY
,ROUND(T1.SALE_QTY / LEAD(T1.SALE_QTY,3) OVER(ORDER BY T1.SALE_YM DESC) * 100,2) BF3_NW_SALE_RT
FROM T_SALE_YM_01 T1
WHERE T1.ITEM_ID = 'M9B'
ORDER BY T1.SALE_YM;
위 SQL의 결과 역시, 셀프 조인을 사용한 SQL과 완전히 같습니다. 하지만, 분석함수의 치명적인 문제는 조회 결과만이 분석대상으로 포함되므로, 아래와 같이 특정 월 데이터를 조회하면 원하는 결과를 얻을 수 없습니다.
SELECT T1.ITEM_ID
,T1.SALE_YM ,T1.SALE_QTY
,LEAD(T1.SALE_YM,3) OVER(ORDER BY T1.SALE_YM DESC) BF3_YM
,LEAD(T1.SALE_QTY,3) OVER(ORDER BY T1.SALE_YM DESC) BF3_QTY
,ROUND(T1.SALE_QTY / LEAD(T1.SALE_QTY,3) OVER(ORDER BY T1.SALE_YM DESC) * 100,2) BF3_NW_SALE_RT
FROM T_SALE_YM_01 T1
WHERE T1.ITEM_ID = 'M9B'
AND T1.SALE_YM = '202012'
ORDER BY T1.SALE_YM;
ITEM_ID SALE_YM SALE_QTY BF3_YM BF3_QTY BF3_NW_SALE_RT
----------- ------- --------- ------ --------- --------------
M9B 202012 20 <null> <null> <null>
결과를 보면, 2020년 12월의 3개월전 데이터인 2020년 9월 데이터가 NULL로 채워진 것을 알 수 있습니다. 'SQL BOOSTER'나 '평생 필요한 데이터 분석' 책에서 설명한 것처럼, 분석함수는 기본적으로 조회된 결과에 대해서만 분석을 수행합니다. 그러므로 2020년 9월 데이터는 위 SQL에서 조회된 결과가 아니기 때문에 분석함수의 분석 대상이 될 수 없습니다. 위와 같은 경우는 불가피하게 앞에서 설명한 셀프 조인 방식으로 처리하는 것이 좋습니다.
이상입니다. 오늘은 정말 짧게 살펴봤습니다. ^^ 다음 글을 설명하기 위해 간단히 셀프 조인을 설명드렸습니다.
감사합니다.
위와 같이 데이터를 마음대로 분석해볼 수 있는 SQL을 공부하고 싶다면 아래 책을 참고해주세요~!
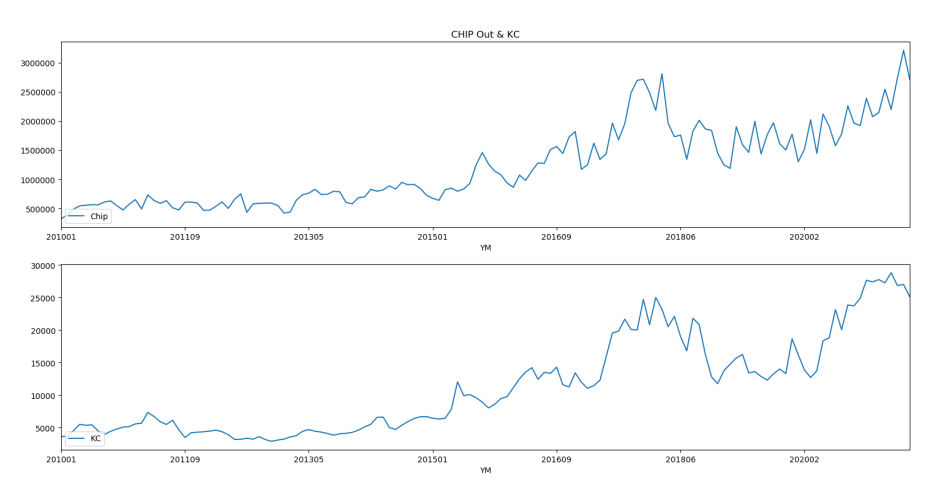
'복합구조칩 집적회로'(Chip, 수출품목코드(HS Code) = 8542323000)의 수출금액과 두 종목의 월별 주가간에 상관 관계가 높은 것을 알 수 있었습니다. 수학적인 학문이 짧은 관계로 상관 관계를 정확히 설명드릴 수 없지만, 복합구조칩의 수출과 SK하이닉스, 삼성전자의 주가는 비슷한 추세로 움직인다 정도로 해석하면 될거 같습니다.
이번에는 역으로 전체 종목을 대상으로 월별 주가와 복합구조칩 수출 금액의 상관 관계를 조사해봅니다. 이를 통해, 상관 관계가 가장 높은 종목을 찾아낼 수 있습니다.
아래와 같은 SQL 한 문장만 실행하면 됩니다. (아래 SQL은 오라클 기준으로 제가 별도 관리하는 데이터입니다.) 오라클은 상관관계를 구할 수 있는 CORR 집계 함수를 기본적으로 제공합니다. (MySQL을 사용한다면, 파이썬의 도움을 받아 CORR을 계산해야 합니다.)
SELECT T2.HS_NM ,T3.STK_CD ,MAX(T3.STK_NM) STK_NM
,CORR(T2.OUT_AMT, T3.C_PRC) COR
,COUNT(*) CNT
FROM (
SELECT T1.YM
,T1.HS_NM
,T1.OUT_AMT
FROM ORA_STK_USER.TRADE_YM T1
WHERE T1.HS_NM IN ('디램','복합구조칩 집적회로','플래시 메모리')
) T2
,(
SELECT B.YM
,A.STK_CD
,A.STK_NM
,B.C_PRC
FROM ORA_STK_USER.M_STK A
,ORA_STK_USER.FT_STK_YM B
WHERE A.STK_CD = B.STK_CD
--AND A.STK_NM = 'SK하이닉스'
) T3
WHERE T2.YM = T3.YM
GROUP BY T2.HS_NM ,T3.STK_CD
HAVING CORR(T2.OUT_AMT, T3.C_PRC) IS NOT NULL AND COUNT(*)>=100
ORDER BY COR DESC;
위 SQL로 아래와 같은 결과를 얻을 수 있습니다. 복합구조칩 수출과 상관 관계가 높은 종목 세 개가 모두 반도체 관련 종목입니다.
상관 관계가 가장 높은 케이씨와 복합구조칩 수출 금액을 차트로 살펴보면 아래와 같습니다. 차트의 그림이 거의 유사한 것을 알 수 있습니다.
여기서 제가 생각하는 투자 전략은, 특정 종목의 주가를 예측하지 않고 특정 품목의 수출 전망을 예측하는 겁니다. 특정 품목의 수출 전망은 산업 현황과 같은 신문 기사를 통해 얻을 수 있겠죠. 그리고 해당 품목의 수출과 상관관계가 높은 종목에 투자를 하는 겁니다. 잘될지 어떨지는 알 수 없겠죠. 그래도주가를 예측하는 것보다는 좀 더 쉽고 안전한 투자 방법이 아닐까 싶습니다.
다시 정리하면, 여러 신문 기사를 통해 수출 전망을 예측한다. 수출이 좋을거 같은 품목의 과거 데이터를 무역 통계 사이트에서 얻어낸다. 무역 통계와 과거 월별 주가를 비교해 가장 상관 관계가 높은 종목을 찾아낸다. (여기서 수출 전망 예측도 이동평균선과 같은 추세선을 이용해 기술적 분석을 고려해 볼 수도 있습니다.)
이를 위해서는 데이터를 이해하고, SQL을 활용할 수 있어야 하겠죠.
위와 같이 주식 데이터를 마음대로 분석해볼 수 있는 SQL을 공부하고 싶다면 아래 책을 참고해주세요~!
데이터를 업로드 했으면, 아래와 같은 SQL로 삼성전자와 SK하이닉스의 2010년부터의 월별 종가를 구할 수 있습니다.
SELECT B.YM
,MAX(CASE WHEN A.STK_NM = '삼성전자' THEN B.C_PRC END) Samsung
,MAX(CASE WHEN A.STK_NM = 'SK하이닉스' THEN B.C_PRC END) Hynix
FROM DB_DTECH.STOCK_KRX A
INNER JOIN DB_DTECH.HIST_YM B
ON (B.STK_CD = A.STK_CD)
WHERE A.STK_NM IN ('삼성전자','SK하이닉스')
GROUP BY B.YM
ORDER BY B.YM
[결과]
YM Samsung Hynix
======== =========== ============
201001 15680.000 22750.000
201002 14880.000 21000.000
201003 16360.000 26700.000
... 생략 ...
지난 글에서는 월별 메모리품목별 수출금액 데이터를 구했습니다. 아래 그림을 보면, 좌측은 월별 메모리품목별 수출금액을 구하는 SQL과 결과입니다.(지난 글에서 설명한 SQL입니다.) 우측은 월별 삼성전자와 하이닉스의 주가(월말 종가)를 구하는 SQL과 결과입니다.
위 그림에서 좌측과 우측의 결과를 합쳐서 하나로 보여주기 위해서는 조인을 사용해야 합니다. 두 결과 모두 월별 데이터 집계이기 때문에 월(YM) 컬러을 사용해 조인을 처리하면 됩니다. 아래와 같이 SQL을 구현할 수 있습니다.
SELECT T2.YM
,T2.DRAM ,T2.CHIP ,T2.FLASH
,T3.Samsung ,T3.Hynix
FROM (
SELECT T1.YM
,MAX(CASE WHEN T1.HS_NM = '디램' THEN T1.OUT_AMT END) DRAM
,MAX(CASE WHEN T1.HS_NM = '복합구조칩 집적회로' THEN T1.OUT_AMT END) CHIP
,MAX(CASE WHEN T1.HS_NM = '플래시 메모리' THEN T1.OUT_AMT END) FLASH
FROM DB_DTECH.TRADE_YM T1
WHERE T1.HS_NM IN ('디램','복합구조칩 집적회로','플래시 메모리')
GROUP BY T1.YM
ORDER BY T1.YM
) T2 INNER JOIN (
SELECT B.YM
,MAX(CASE WHEN A.STK_NM = '삼성전자' THEN B.C_PRC END) Samsung
,MAX(CASE WHEN A.STK_NM = 'SK하이닉스' THEN B.C_PRC END) Hynix
FROM DB_DTECH.STOCK_KRX A
INNER JOIN DB_DTECH.HIST_YM B
ON (B.STK_CD = A.STK_CD)
WHERE A.STK_NM IN ('삼성전자','SK하이닉스')
GROUP BY B.YM
ORDER BY B.YM
) T3 ON (T2.YM = T3.YM)
ORDER BY T2.YM
[결과]
YM DRAM CHIP FLASH Samsung Hynix
======== ============= ============= ============ =========== ============
201001 807931.000 322032.000 205735.000 15680.000 22750.000
201002 768520.000 388025.000 206517.000 14880.000 21000.000
201003 937606.000 487808.000 242982.000 16360.000 26700.000
201004 976082.000 543395.000 253916.000 16980.000 28400.000
... 생략 ...
위에서 HIST_YM, STOCK_KRX, TRADE_YM 은 모두 테이블입니다. 하지만, TRADE_YM을 GROUP BY 처리한 FROM절의 T2는 테이블이라기 보다는 데이터 결과 집합입니다. 마찬가지로 HIST_YM을 GROUP BY 처리한 T3 역시 데이터 결과 집합니다. 이처럼 조인은 테이블과 테이블이 아닌 데이터 결과 집합과 데이터 결과 집합 사이에 이루어질 수 있습니다. 더 나아가서 테이블 역시 데이터 결과 집합이라고 인식하셔도 됩니다.
항상 조인을 할 때는 두 데이터 집합 간의 연결 고리를 잘 찾아야 합니다. 두 데이터 집합 모두 월별로 집계되었기 때문에 월을 이용해 두 데이터 결과 집합을 연결하면 됩니다.
이번에는 위 SQL을 그대로 파이썬에 붙여서 차트를 그려보겠습니다. 삼성전자와 하이닉스 주가는 subplot으로 별도로 그려지도록 처리합니다.
import pymysql
import pandas as pd
import matplotlib.pyplot as plt
# MySQL 연결 처리
myMyConn = pymysql.connect(user='root', password='1qaz2wsx', host='localhost', port=3306, charset='utf8',
database='DB_SQLSTK')
myMyCursor = myMyConn.cursor()
sql = """
SELECT T2.YM
,T2.DRAM ,T2.CHIP ,T2.FLASH
,T3.Samsung ,T3.Hynix
FROM (
SELECT T1.YM
,MAX(CASE WHEN T1.HS_NM = '디램' THEN T1.OUT_AMT END) DRAM
,MAX(CASE WHEN T1.HS_NM = '복합구조칩 집적회로' THEN T1.OUT_AMT END) CHIP
,MAX(CASE WHEN T1.HS_NM = '플래시 메모리' THEN T1.OUT_AMT END) FLASH
FROM DB_DTECH.TRADE_YM T1
WHERE T1.HS_NM IN ('디램','복합구조칩 집적회로','플래시 메모리')
GROUP BY T1.YM
ORDER BY T1.YM
) T2 INNER JOIN (
SELECT B.YM
,MAX(CASE WHEN A.STK_NM = '삼성전자' THEN B.C_PRC END) Samsung
,MAX(CASE WHEN A.STK_NM = 'SK하이닉스' THEN B.C_PRC END) Hynix
FROM DB_DTECH.STOCK_KRX A
INNER JOIN DB_DTECH.HIST_YM B
ON (B.STK_CD = A.STK_CD)
WHERE A.STK_NM IN ('삼성전자','SK하이닉스')
GROUP BY B.YM
ORDER BY B.YM
) T3 ON (T2.YM = T3.YM)
ORDER BY T2.YM
"""
# DataFrame에 SQL 결과 저장
df = pd.read_sql(sql, myMyConn)
# 결과 출력
print(df)
# 차트로 처리할 항목을 Series에 별도로 담는다.
dram = df['DRAM']
chip = df['CHIP']
flash = df['FLASH']
samsung = df['Samsung']
hynix = df['Hynix']
dram.index = df['YM']
samsung.index = df['YM']
hynix.index = df['YM']
plt.figure(figsize=(11, 9))
plt.subplot(311)
dram.plot(label='DRAM', title="Memory Out & Samsung & SK Hynix")
chip.plot(label='Chip')
flash.plot(label='Flash memory')
plt.legend(loc='lower left')
plt.subplot(312)
samsung.plot(label='Samsung')
plt.legend(loc='lower left')
plt.subplot(313)
hynix.plot(label='Hynix')
plt.legend(loc='lower left')
plt.show()
print(df.corr())
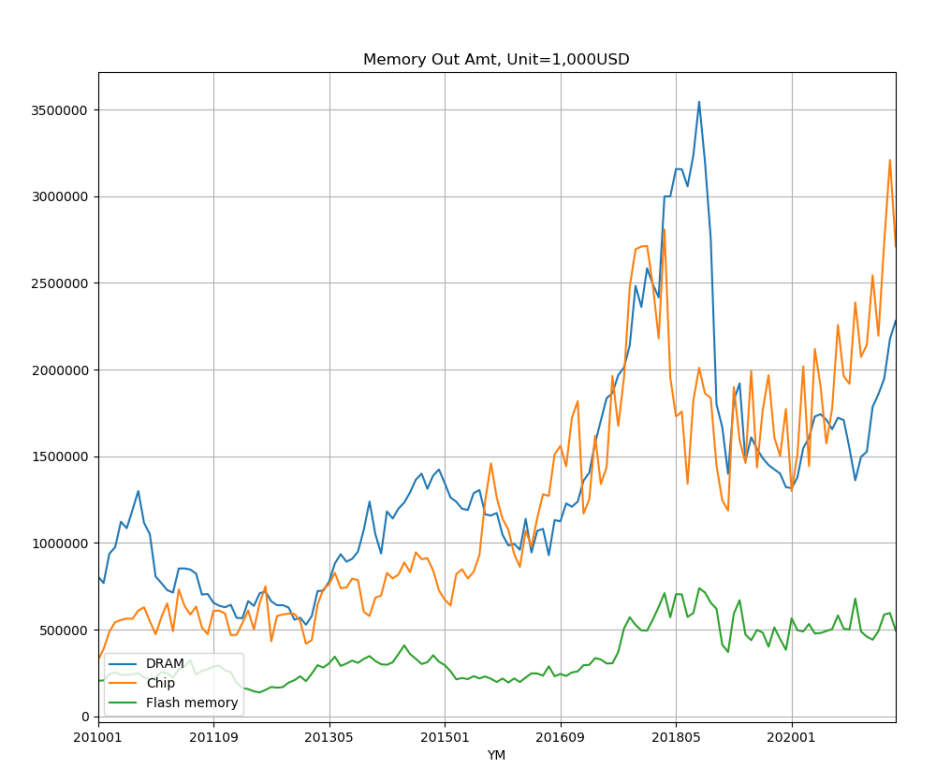
위의 파이썬 코드를 실행하면 아래와 같은 차트가 만들어집니다.
차트만 보고서는 수출금액이 삼성전자나 SK하이닉스의 주가에 영향을 주는지 정확히 알아 볼 수가 없습니다. 대충 보기에는 메모리 품목 중에 Chip 부분의 수출금액과 삼성전자와 SK하이닉스의 주가 움직임이 유사한 느낌은 듭니다.
차트가 유사하다는 것은 위 파이썬 코드 중에, 마지막 줄의 df.corr을 통해 확인할 수 있습니다.
df는 파이썬 모듈중에 pandas.dataframe입니다. dataframe의 corr을 수행하면, dataframe에 입력된 데이터들의 상관계수를 구할 수있습니다. 저도 수학적으로는 잘 모르지만, 상관계수가 1에 가까우면 두 계열의 수치 간에 정비례한 상관 관계가 있다고 합니다.
결과를 보면 ,Chip과 삼성의 상관계수가 0.866이고 Chip과 하이닉스의 상관계수가 0.85로 높은것을 알 수 있습니다. 그리고 삼성과 하이닉스의 상관관계는 무려 0.95나 됩니다.
이처럼 높은 상관계수를 사용하면 수익을 얻을 수 있는 투자 전략을 만들 수 있지 않을까 생각이 듭니다. 하지만 그렇게 쉽지가 않답니다. 수출 데이터는 매월 15일에 지난달 데이터가 집계가 됩니다. 그러므로 우리가 수출 데이터를 접하기 전에 주가는 올라 버렸을 가능성이 있습니다. 더욱이, 제품의 수출 전에는 '계약'이라는 단계가 필요합니다. '만약에 거대 '계약'이 있다면, 수출까지 발생하기 전에 주가는 이미 다 오르지 않을까 싶습니다. 또한 주가라는 것은 어느 한 요소만으로 결정되지는 않습니다. 그럼에도 불구하고, 조금 더 고민해볼 필요는 있을거 같습니다. 투자 전략을 못 얻더라도 SQL 실력과 데이터를 바라보는 눈을 얻을 수 있으니까요.
오늘은 여기까지입니다. 감사합니다.
위와 같이 주식 데이터를 마음대로 분석해볼 수 있는 SQL을 공부하고 싶다면 아래 책을 참고해주세요~!
메모리 품목 관련해서 다양한 품목이 있는데, 그 중에 수출금액이 가장큰 품목 세 개만 조회해보겠습니다. 아래와 같이 SQL을 실행합니다.
MySQL에서 Top-N을 추출하기 위해 가장 쉽게 사용할 수 있는 것이 바로 LIMIT입니다. 아래와 같습니다.
SELECT HS_NM
,ROUND(SUM(OUT_AMT)) SUM_OUT_AMT
,MIN(YM) MIN_YM
,MAX(YM) MAX_YM
,ROUND(AVG(OUT_AMT)) AVG_OUT_AMT
FROM DB_DTECH.TRADE_YM
GROUP BY HS_NM
ORDER BY 2 DESC
LIMIT 3;
[결과]
HS_NM SUM_OUT_AMT MIN_YM MAX_YM AVG_OUT_AMT
============================== ============= ======== ======== =============
디램 189563001 201001 202107 1363763
복합구조칩 집적회로 170826060 201001 202107 1228964
플래시 메모리 49402623 201001 202107 355415
위 SQL을 통해 메모리 관련 세부 품목 중에, 디램, 복합구조칩 집적회로, 플래시 메모리가 가장 수출이 많은것을 알 수 있습니다. 디램의 경우, 2010년 1월부터 2021년 7월까지 총 189,563,001 천USD 수출을 했고, 월평균 1,363,763 천USD 만큼 수출했습니다. 현재 환율로 계산하면 월평균 1.5조원 정도 되는거 같습니다. 어마어마한 금액이네요.
이번에는 위에서 찾은 세 개 품목에 대해 월별 수출금액을 구해봅니다. 품목명을 컬럼으로 처리하기 위해 아래와 같이 GROUP BY와 CASE를 사용합니다. 분석 SQL에서 PIVOT을 구혆려면 GROUP BY 와 MAX 또는 SUM이 필수죠.
SELECT T1.YM
,MAX(CASE WHEN T1.HS_NM = '디램' THEN T1.OUT_AMT END) DRAM
,MAX(CASE WHEN T1.HS_NM = '복합구조칩 집적회로' THEN T1.OUT_AMT END) CHIP
,MAX(CASE WHEN T1.HS_NM = '플래시 메모리' THEN T1.OUT_AMT END) FLASH
FROM DB_DTECH.TRADE_YM T1
WHERE T1.HS_NM IN ('디램','복합구조칩 집적회로','플래시 메모리')
GROUP BY T1.YM
ORDER BY T1.YM
[결과]
YM DRAM CHIP FLASH
======== ============= ============= ============
201001 807931.000 322032.000 205735.000
201002 768520.000 388025.000 206517.000
201003 937606.000 487808.000 242982.000
... 생략 ...
끝으로, 위의 SQL을 파이썬에서 실행해 결과를 차트로 그려보는겁니다. 간단합니다.
import pymysql
import pandas as pd
import matplotlib.pyplot as plt
# MySQL 연결 처리
myMyConn = pymysql.connect(user='root', password='1qaz2wsx', host='localhost', port=3306,charset='utf8', database='DB_SQLSTK')
myMyCursor = myMyConn.cursor()
# 실행할 SQL 생성
sql = """
SELECT T1.YM
,SUM(CASE WHEN T1.HS_NM = '디램' THEN T1.OUT_AMT END) DRAM
,SUM(CASE WHEN T1.HS_NM = '복합구조칩 집적회로' THEN T1.OUT_AMT END) CHIP
,SUM(CASE WHEN T1.HS_NM = '플래시 메모리' THEN T1.OUT_AMT END) FLASH
FROM DB_DTECH.TRADE_YM T1
WHERE T1.HS_NM IN ('디램','복합구조칩 집적회로','플래시 메모리')
GROUP BY T1.YM
ORDER BY T1.YM
"""
# DataFrame에 SQL 결과 저장
df = pd.read_sql(sql, myMyConn)
# 결과 출력
print(df)
# 차트로 처리할 항목을 Series에 별도로 담는다.
dram = df['DRAM']
chip = df['CHIP']
flash = df['FLASH']
dram.index = df['YM']
plt.figure(figsize=(11,9))
dram.plot(label='DRAM', title= "Memory Out Amt, Unit=1,000USD")
chip.plot(label='Chip')
flash.plot(label='Flash memory')
plt.legend(loc='lower left')
plt.grid(True)
plt.show()
아래와 같이 세부 품목별 수출금액을 차트로 볼 수 있습니다.
오늘은 여기까지입니다.~!
감사합니다.
위와 같이 주식 데이터를 마음대로 분석해볼 수 있는 SQL을 공부하고 싶다면 아래 책을 참고해주세요~!
업로드가 완료되면 아래와 같이 간단히 조회를 해봅니다. 메모리 세부 품목별로 수출금액을 조회합니다.
SELECT HS_NM, SUM(OUT_AMT) OUT_AMT
FROM DB_DTECH.TRADE_YM
GROUP BY HS_NM
ORDER BY 2 DESC;
[결과]
HS_NM OUT_AMT
=========================================================================== ===============
디램 189563001.000
복합구조칩 집적회로 170826060.000
플래시 메모리 49402623.000
제8517호의 기기에 전용되거나 주로 사용되는 것 42578781.000
기타 2167554.000
에스램 313599.000
제8425호ㆍ제8426호ㆍ제8428호ㆍ제8429호ㆍ제8430호ㆍ제8443.99호ㆍ8470호ㆍ제 30226.000
제9031호의 기기에 전용되거나 주로 사용되는 것(반도체 제조용으로 한정한다) 133.000
제9032호의 기기에 전용되거나 주로 사용되는 것(항공기용으로 한정한다) 36.000
제9301호ㆍ제9306호의 물품에 전용되거나 주로 사용되는 것 10.000
제8528.42호ㆍ제8528.52호ㆍ제8528.62호ㆍ제8531.20호의 기기에 전용되거나 주 2.000
오늘은 여기까지입니다.~! 이어서는 수출 정보를 사용해 간다난 차트도 그려보고 주가 정보와 연계해서 분석하는 과정도 설명할 예정입니다.
감사합니다.
위와 같이 데이터를 마음대로 분석해볼 수 있는 SQL을 공부하고 싶다면 아래 책을 참고해주세요~!
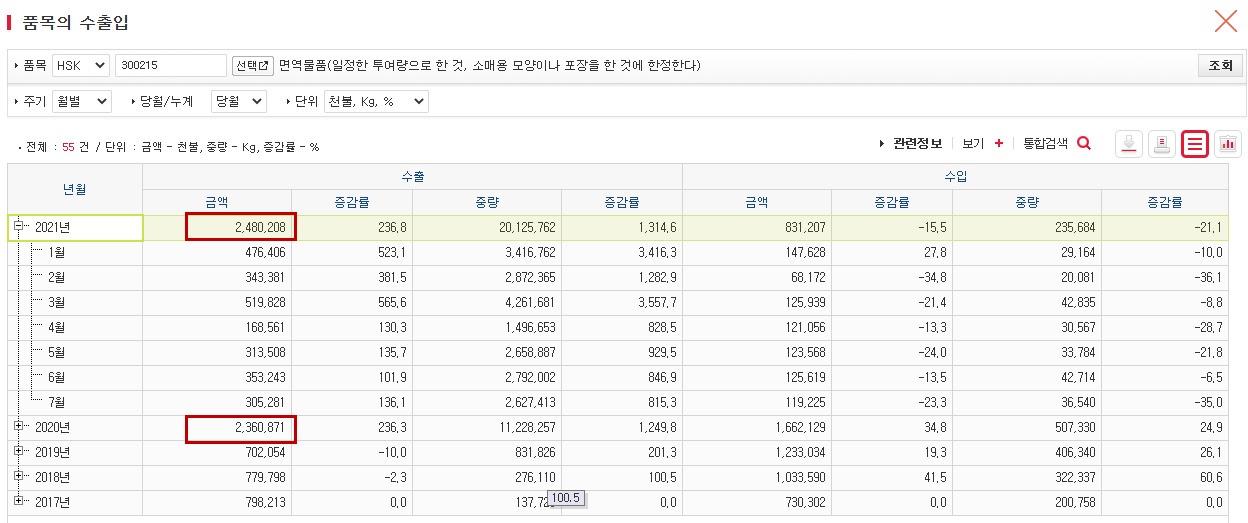
- '수출증감률'을 보면 됩니다. 전년 동월대비 현재 얼마나 증가했는지를 알 수 있습니다.
- 많은 품목들이 있지만, 개인적으로 증감율이 136%인 '300215'코드가 눈에 뜁니다.
(각자 원하는 품목을 보시면 되겠죠.)
- 해당 품목 코드를 클릭합니다.
5. 위에서 품목코드를 클릭하면, 아래와 같이 품목별 기간별 상세한 수출내역이 나옵니다.
- 300215 품목의 경우, 2021년이 7개월밖에 안지났는데 벌써 작년만큼 수출을 한 것을 알 수 있습니다.
- 올해말까지라면 작년보다 더 많이 수출하겠죠.
6. 300215는 대체 무엇일까요? (개인적인 궁금증입니다.)
설명에는 "면역물품, 일정한 투여량으로 한 것, 소매용 모양이나 포장을 한 것에 한정한다."라고 되어 있습니다. 이 설명만 봐서는 알 수 없습니다.
300215를 좀 더 알아보기 위해, 지자체 수출입 메뉴로 들어갑니다.
7. 지자체 수출입 확인
- 아래와 같이, 지역구분은 '기초자치별'로, HSK에 300215를 넣고 조회를 합니다.
- 결과를 보면 충북 청주시가 압도적으로 수출한 것을 알 수 있습니다.
- 충북 청주시에 있는 면역물품 수출 업체는 과연 어디일까요???!!!!!!! 아시는 분은 댓글 부탁드립니다.^^ 미리 감사합니다.
설명은 여기까지입니다. 제 개인적인 질문도 있지만, 이처럼 무역 통계를 활용하시면, 자신이 투자할 종목을 선정하는데 큰 도움이 될거 같습니다.
이처럼, 데이터를 분석하는 과정을 공부해보고 싶으신 분은 아래의 '평생 필요한 데이터 분석'의 교육 과정을 추천합니다. 교육을 통해 SQL을 배운다면, 위 내용을 좀 더 보강할 수도 있고, 자신만의 스타일로 분석을 할 수 있습니다. SQL을 완전히 자신의 것으로 만들 수 있는 교육이니 관심 가져보시기 바랍니다. 감사합니다.~!
아마도 모르는 분들이 거의 없지 않을까 생각합니다. 많은 사람들이 아는만큼, 효과가 있다고 보기는 어려운 매매 신호입니다. 주식을 오래 해보신 분들은 아시겠지만, 골든크로스라는 아주 기초적인 기술만 가지고 매매를 했다가는 거의 실패하고 맙니다.
효과가 없다면서, 여기서 골든크로스를 언급하는 이유는 좀 더 다르게 확률적으로 접근해보기 위해서입니다.
본격적인 설명에 앞서, 절대 어떤 종목을 추천하기 위한 글이 아니며, 본 글로 인해 투자한 종목의 손실에 대해서는 절대 누구도 책임지지 않는다는 것을 기억해주시기 바랍니다.
데이터의 정확성 역시 일차적으로는 검토했지만, 데이터 수집 시점이나 과정에서 발생한 실수로 부정확할수도 있으니 양해바랍니다.
골든크로스는 단기이평선과 중장기이평선을 사용해 단기이평선이 중장기이평선을 아래에서 위로 치고 올라가는 형태를 뜻합니다. 이때 단기이평선과 중장기이평선의 일수는 각자가 선호하는 값을 사용합니다.
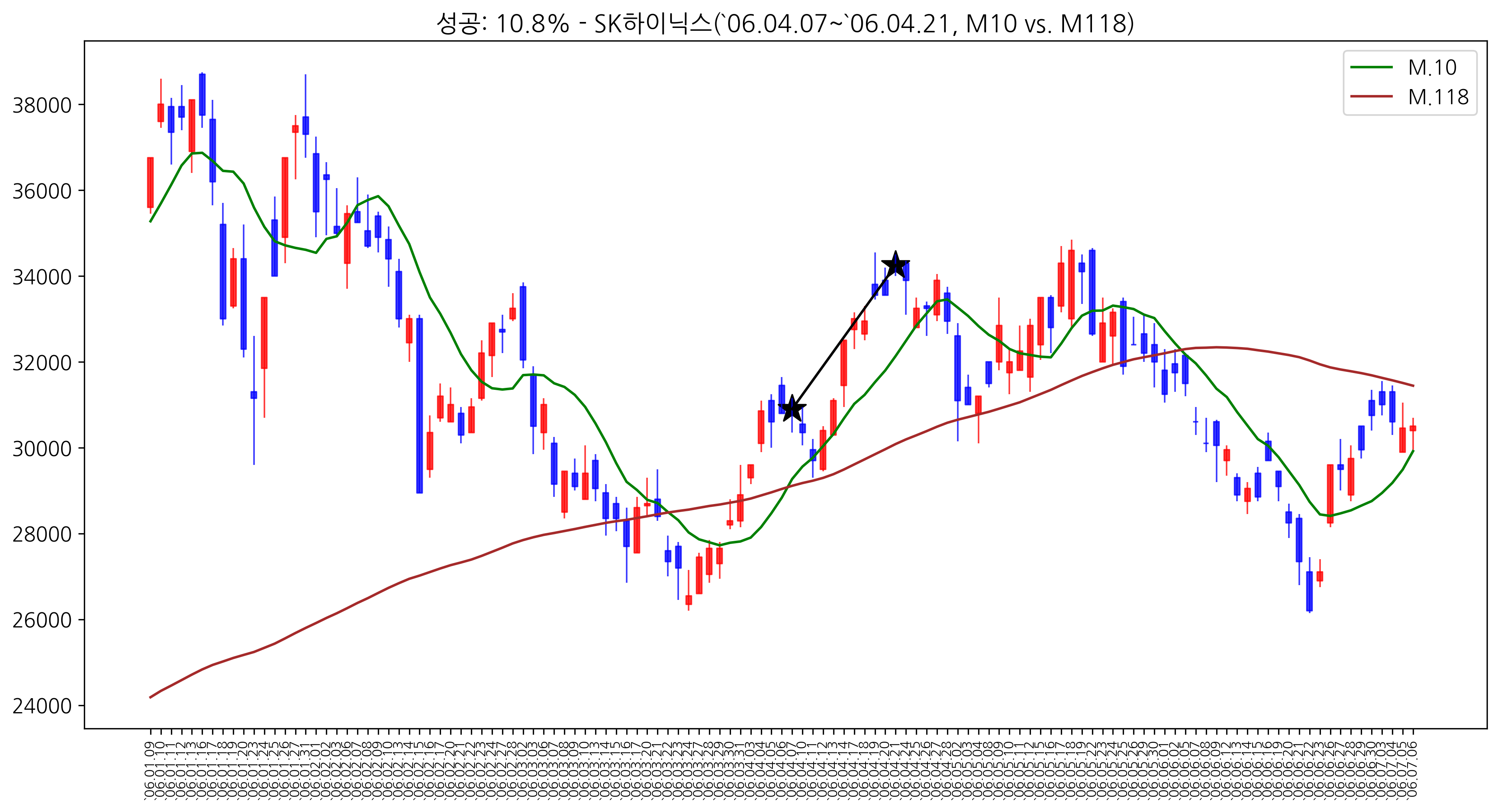
여기서는, 데이터 분석을 통해 특정 종목에 대해 가장 좋은 단기이평선과 중장기이평선의 일수를 찾아봤습니다. 오늘은 SK하이닉스에 대해 계산을 해봤습니다.
결과를 살펴보면 아래와 같습니다.
사진 설명을 입력하세요.
항목별로 설명해보면 아래와 같습니다.
1. 단기이평선 : 단기이평선 일수
2. 중장기이평선: 중장기이평선 일수
3. 골든크로스돌파횟수: 2000년부터 지금(2021.08.26)까지 골든크로스 돌파가 일어난 횟수
: 1번과 2번의 단기이평선과 중장기이평선을 사용한 골든크로스 돌파 횟수
4. 승리횟수: 골든크로스 돌파 후, 10일후 3% 이상 상승한 경우 승리로 카운트
5. 승리확률: 승리횟수 / 골든크로스돌파횟수
6. 평균등락률: 10일후의 평균 등락률
결과를 살펴보면, 10일선과 118일선 간에 골든크로스 돌파가 2000년부터 지금까지 33번 발생했으며 그중에 23번은 10일후에 3% 이상 상승했습니다. 확률로 계산해보면 69.7%가 됩니다.
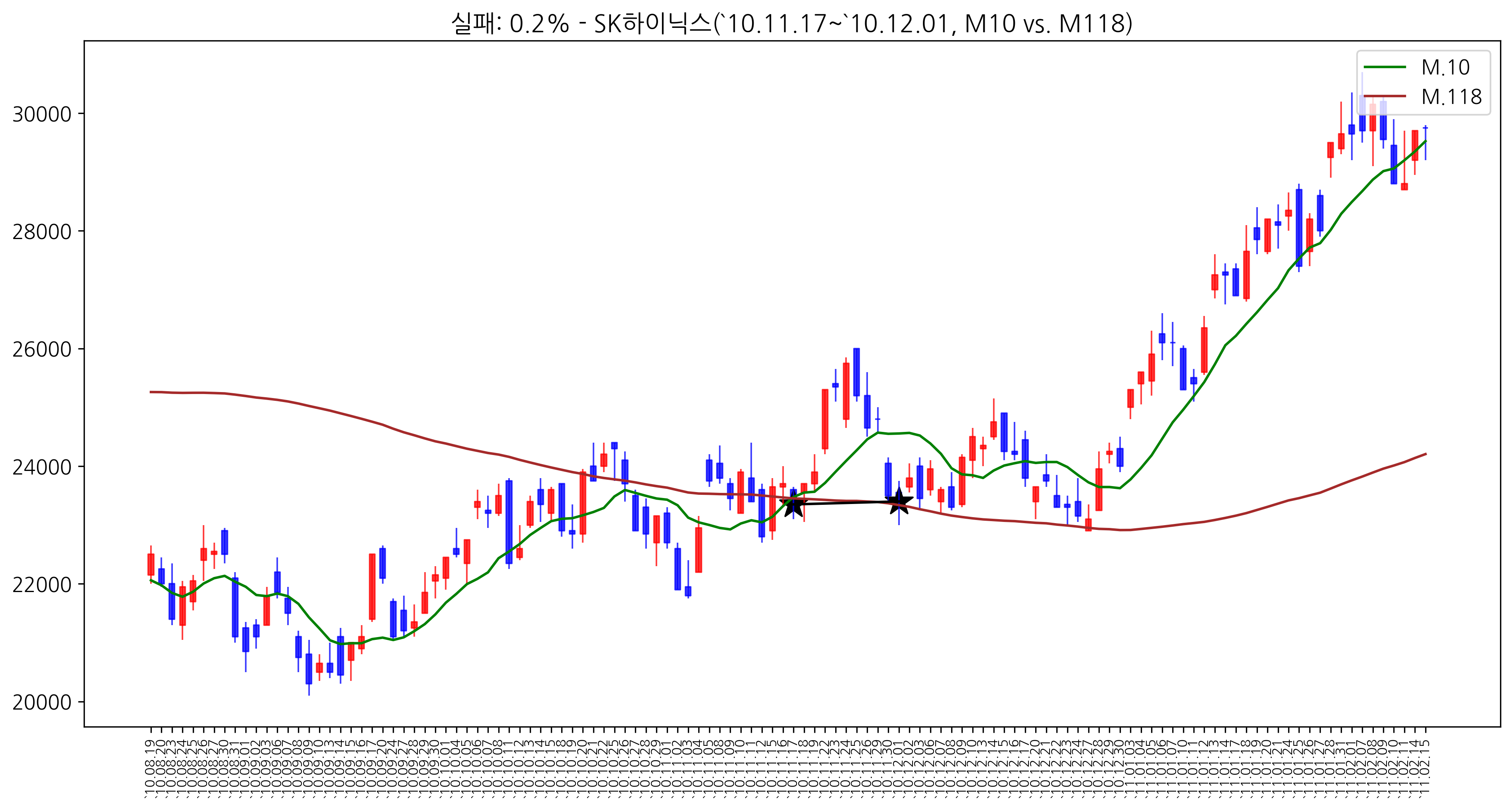
이번에는 SK하이닉스를 대상으로 가장 나쁜 경우를 살펴보겠습니다. 아래와 같습니다.
결과를 보면, 26일선과 89일선을 사용해 골든크로스 매매를 하면, 35번 중에 단지 6번만 10일후에 3%이상 상승한 것을 알 수 있습니다.
이를 통해서, SK하이닉스 매매는 10일선과 118일선을 사용해서 참고하는 것이 좀더 좋을 수 있겠다라고 생각할 수 있습니다.
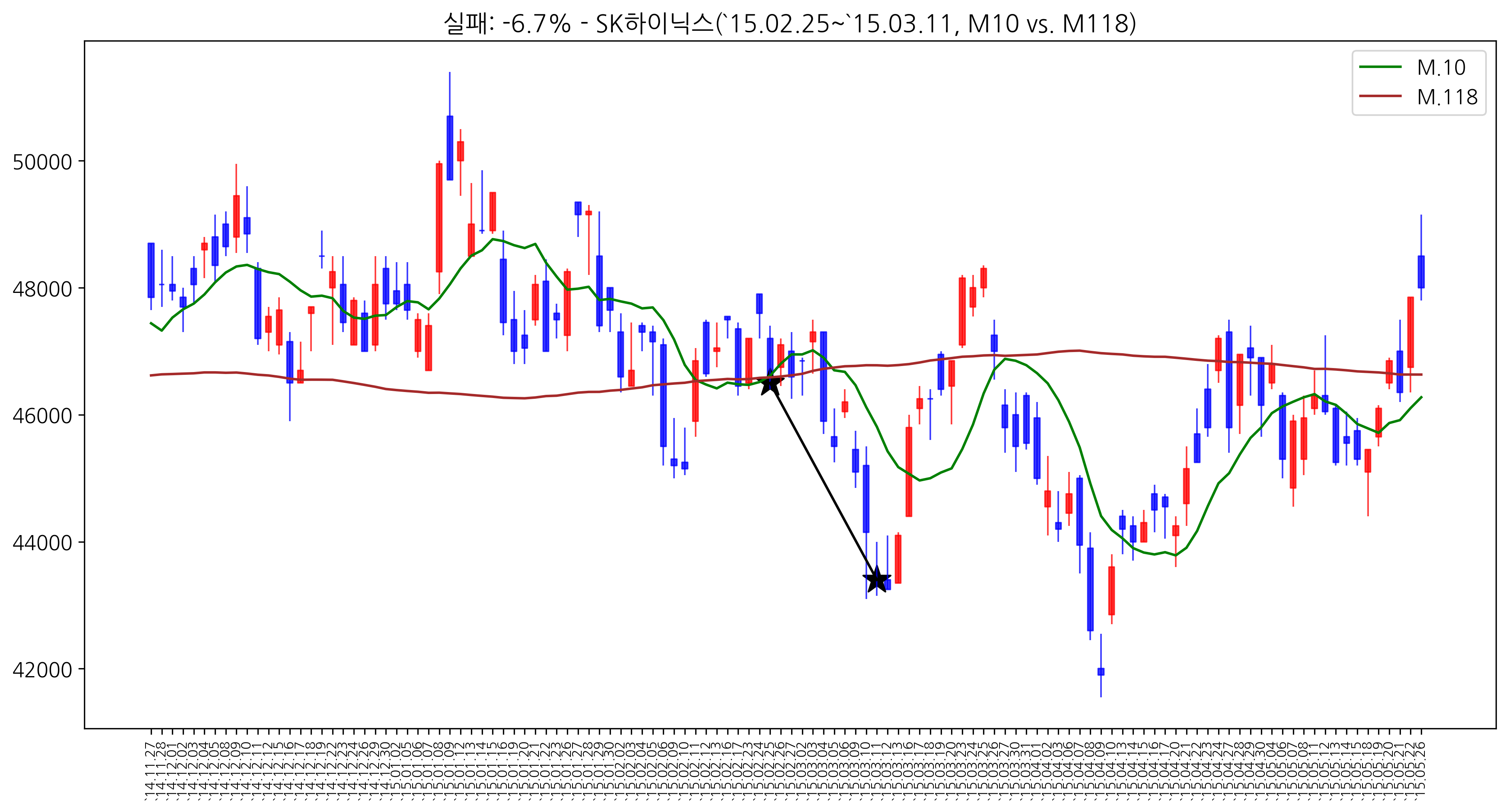
그러면, 실제로도 그런지 차트를 훑어볼 필요가 있습니다. 2000년 이후로 지금까지 10일선과 118일선의 골든크로스가 발생한 차트를 다 올려보면 아래와 같습니다. 33개 차트라 좀 많습니다.(글 마지막에 일괄 붙여 드립니다.)
여기서 중요한건!!! 골든크로스를 무조건 믿어서는 안된다는 겁니다.
우선 기본적 분석을 통해 종목을 잘 선정하고, 해당 종목의 미래 현황도 충분히 검토한 후에.. 매매 시점에 이러한 부분을 참고한다면 좀 더 도움이 되리라고 생각합니다. 또한, 아래 차트들을 보시면 아시겠지만, 해당 매매신호를 사용해도 크게 손실을 보는 경우가 있습니다.
SK하이닉스는 가장 좋은 승리확률이 69.7%로 그나마 높은 편입니다. 삼성전자의 경우는 56%가 가장 좋은 케이스입니다. 또 한가지, 기준을 어떻게 정하느냐에 따라 결과는 매우 다양해집니다. 예를 들어 승리조건을 10일후가 아니라 3일후, 20일후 이와 같이 변경하면 전혀 다른 결과가 나올 수 있습니다.
주식이 항상 확률대로 움직이지 않는다는걸 너무나 잘 아실겁니다. 좋은 기업을 고른후에 확률을 약간 가미한다면 남보다 조금 좋은 결과가 있지 않을까 개인적으로 생각합니다.
끝으로 제가 이 글을 올리는 이유는, 데이터 분석이라는 것이 주식에 한정되는 것이 아니고, 자신의 업무와 자신의 일에 큰 도움을 주므로, 여러분들도 관심을 가지고 공부해보셨으면 하는 마음에서 입니다.
위의 링크된 글을 따라하면 MySQL DB에 HIST_YM 테이블을 생성하고 21년 6월까지의 월별 주가 데이터가 만들어집니다. 우리는 21년 8월까지의 월별주가가 필요하기 때문에 HIST_YM을 TRUNCATE 한 후에, 본 글에 첨부된 데이터로 다시 업로드를 해주세요.
데이터를 올렸다면 분석은 간단합니다. 아래와 같은 SQL을 사용하도록 하겠습니다.
1. 반기별 영업이익 증가 Top과 주가 흐름
SELECT T1.*
,T_2003.C_PRC `종가(20년3월)`
,T_2101.C_PRC `종가(21년1월)`
,T_2108.C_PRC `종가(21년8월25일)`
,(SELECT MAX(A.H_PRC) FROM DB_DTECH.HIST_YM A WHERE A.STK_CD = T1.STK_CD AND A.YM LIKE '2020%') `고가(20년)`
,(SELECT MIN(A.L_PRC) FROM DB_DTECH.HIST_YM A WHERE A.STK_CD = T1.STK_CD AND A.YM LIKE '2020%') `저가(20년)`
,(SELECT MAX(A.H_PRC) FROM DB_DTECH.HIST_YM A WHERE A.STK_CD = T1.STK_CD AND A.YM LIKE '2021%') `고가(21년)`
,(SELECT MIN(A.L_PRC) FROM DB_DTECH.HIST_YM A WHERE A.STK_CD = T1.STK_CD AND A.YM LIKE '2021%') `저가(21년)`
FROM (
SELECT T1.회사명
,REPLACE(REPLACE(T1.종목코드,'[',''),']','') STK_CD
,'1-반기별 영업이익증가액 Top' 구분
,ROUND(T1.당기_반기_누적/1e8,1) 당년반기
,ROUND(T1.전기_반기_누적/1e8,1) 전년반기
,ROUND(ROUND(T1.당기_반기_누적/1e8,1) - ROUND(T1.전기_반기_누적/1e8,1),1) 구분값
,ROW_NUMBER() OVER(ORDER BY ROUND(ROUND(T1.당기_반기_누적/1e8,1) - ROUND(T1.전기_반기_누적/1e8,1),1) DESC) 구분별순위
FROM DB_DTECH.UP_손익계산서_20211H T1
WHERE T1.항목코드 = 'dart_OperatingIncomeLoss'
AND T1.당기_반기_누적 > 0
AND T1.통화 = 'KRW'
UNION ALL
SELECT T1.회사명
,REPLACE(REPLACE(T1.종목코드,'[',''),']','') STK_CD
,'2-반기별 영업이익증가율 Top' 구분
,ROUND(T1.당기_반기_누적/1e8,1) 당년반기
,ROUND(T1.전기_반기_누적/1e8,1) 전년반기
,ROUND(ROUND(T1.당기_반기_누적/1e8,1) / ROUND(T1.전기_반기_누적/1e8,1),1) 구분값
,ROW_NUMBER() OVER(ORDER BY ROUND(ROUND(T1.당기_반기_누적/1e8,1) / ROUND(T1.전기_반기_누적/1e8,1),1) DESC) 구분별순위
FROM DB_DTECH.UP_손익계산서_20211H T1
WHERE T1.항목코드 = 'dart_OperatingIncomeLoss'
AND T1.당기_반기_누적 > 0
AND T1.전기_반기_누적 > 0
AND T1.통화 = 'KRW'
UNION ALL
SELECT T1.회사명
,REPLACE(REPLACE(T1.종목코드,'[',''),']','') STK_CD
,'3-반기별 영업이익증가율 Top(500억이상만)' 구분
,ROUND(T1.당기_반기_누적/1e8,1) 당년반기
,ROUND(T1.전기_반기_누적/1e8,1) 전년반기
,ROUND(ROUND(T1.당기_반기_누적/1e8,1) / ROUND(T1.전기_반기_누적/1e8,1),1) 구분값
,ROW_NUMBER() OVER(ORDER BY ROUND(ROUND(T1.당기_반기_누적/1e8,1) / ROUND(T1.전기_반기_누적/1e8,1),1) DESC) 구분별순위
FROM DB_DTECH.UP_손익계산서_20211H T1
WHERE T1.항목코드 = 'dart_OperatingIncomeLoss'
AND T1.당기_반기_누적/1e8 > 500
AND T1.전기_반기_누적 > 0
AND T1.통화 = 'KRW'
) T1
LEFT OUTER JOIN DB_DTECH.HIST_YM T_2003 ON (T_2003.STK_CD = T1.STK_CD AND T_2003.YM = '202003')
LEFT OUTER JOIN DB_DTECH.HIST_YM T_2101 ON (T_2101.STK_CD = T1.STK_CD AND T_2101.YM = '202101')
LEFT OUTER JOIN DB_DTECH.HIST_YM T_2108 ON (T_2108.STK_CD = T1.STK_CD AND T_2108.YM = '202108')
WHERE T1.구분별순위 <= 10
ORDER BY T1.구분, T1.구분별순위;
결과는 아래와 같습니다.
2. 분기별 영업이익 증가 Top과 주가 흐름
WITH RES01 AS(
SELECT T1.회사명
,REPLACE(REPLACE(T1.종목코드,'[',''),']','') STK_CD
,ROUND(T1.당기_반기_3개월/1e8,1) `2분기`
,ROUND((T1.당기_반기_누적 - T1.당기_반기_3개월)/1e8,1) `1분기`
FROM DB_DTECH.UP_손익계산서_20211H T1
WHERE T1.항목코드 = 'dart_OperatingIncomeLoss'
AND T1.통화 = 'KRW'
)
SELECT T1.*
,T_2003.C_PRC `종가(20년3월)`
,T_2101.C_PRC `종가(21년1월)`
,T_2108.C_PRC `종가(21년8월25일)`
,(SELECT MAX(A.H_PRC) FROM DB_DTECH.HIST_YM A WHERE A.STK_CD = T1.STK_CD AND A.YM LIKE '2020%') `고가(20년)`
,(SELECT MIN(A.L_PRC) FROM DB_DTECH.HIST_YM A WHERE A.STK_CD = T1.STK_CD AND A.YM LIKE '2020%') `저가(20년)`
,(SELECT MAX(A.H_PRC) FROM DB_DTECH.HIST_YM A WHERE A.STK_CD = T1.STK_CD AND A.YM LIKE '2021%') `고가(21년)`
,(SELECT MIN(A.L_PRC) FROM DB_DTECH.HIST_YM A WHERE A.STK_CD = T1.STK_CD AND A.YM LIKE '2021%') `저가(21년)`
FROM (
SELECT T1.회사명
,T1.STK_CD
,'4-분기별 영업이익증가액 Top' 구분
,T1.`2분기`
,T1.`1분기`
,ROUND(T1.`2분기` - T1.`1분기`,1) 구분값
,ROW_NUMBER() OVER(ORDER BY ROUND(T1.`2분기` - T1.`1분기`,1) DESC) 구분별순위
FROM RES01 T1
WHERE T1.`2분기` > 0
UNION ALL
SELECT T1.회사명
,T1.STK_CD
,'5-분기별 영업이익증가율 Top' 구분
,T1.`2분기`
,T1.`1분기`
,ROUND(T1.`2분기`/T1.`1분기`,1) 구분값
,ROW_NUMBER() OVER(ORDER BY ROUND(T1.`2분기`/T1.`1분기`,1) DESC) 구분별순위
FROM RES01 T1
WHERE T1.`2분기` > 0
AND T1.`1분기` > 0
UNION ALL
SELECT T1.회사명
,T1.STK_CD
,'6-분기별 영업이익증가율 Top(500억이상만)' 구분
,T1.`2분기`
,T1.`1분기`
,ROUND(T1.`2분기`/T1.`1분기`,1) 구분값
,ROW_NUMBER() OVER(ORDER BY ROUND(T1.`2분기`/T1.`1분기`,1) DESC) 구분별순위
FROM RES01 T1
WHERE T1.`2분기` > 500
AND T1.`1분기` > 0
) T1
LEFT OUTER JOIN DB_DTECH.HIST_YM T_2003 ON (T_2003.STK_CD = T1.STK_CD AND T_2003.YM = '202003')
LEFT OUTER JOIN DB_DTECH.HIST_YM T_2101 ON (T_2101.STK_CD = T1.STK_CD AND T_2101.YM = '202101')
LEFT OUTER JOIN DB_DTECH.HIST_YM T_2108 ON (T_2108.STK_CD = T1.STK_CD AND T_2108.YM = '202108')
WHERE T1.구분별순위 <= 10
ORDER BY T1.구분, T1.구분별순위
;
업로드용 임시 테이블이므로 PK를 설정하지 않았습니다. (실제 분석을 위해서는 위의 데이터를 정규화된 테이블로 구조화해야 합니다. 이는 좀 더 많은 공수가 추가되므로 오늘은 다루지 않습니다. 언제가 다룰 예정입니다.)
위 테이블에 데이터를 올리는 과정은 위에 링크 드린 이전 글들을 참고해주세요. 저 같은 경우 DBeaver를 사용했습니다. 아래와 같이 Mapping을 잘 해야 에러 없이 데이터를 올릴 수 있습니다. 데이터 Import 과정에서 컬럼의 Mapping 값이 Existing 이 되도록 해야 합니다. 새로 컬럼을 추가할 경우 길이 문제로 업로드가 잘 안될 수도 있습니다. (만약에 업로드 실패 후 다시 올려야 한다면, 위에서 만들었던 테이브를 DROP후 다시 만들고 시도해주세요.)
데이터를 모두 업로드했다면, 이젠 손쉽게 데이터를 분석할 수 있습니다.
본격적인 설명에 앞서, 절대 어떤 종목을 추천하기 위한 글이 아니며, 본 글로 인해 투자한 종목의 손실에 대해서는 절대 누구도 책임지지 않는다는 것을 기억해주시기 바랍니다.
데이터의 정확성 역시 일차적으로는 검토했지만, 데이터 수집 시점이나 과정에서 발생한 실수로 부정확할수도 있으니 양해바랍니다.
오늘은 등락률 컬럼을 추가해 미리 계산해 넣으려고 합니다. 이 과정중에서 말씀드리고 싶은 내용은 다음과 같습니다.
- 미리 계산된 컬럼을 추가할 때 주의할 점
- 테이블 구조 변경시 항상 ERD를 먼저 변경할 것
등락률은 주가 분석에 빈번하게 사용됩니다. 분석에 자주 사용되는 정보를 분석함수를 사용해서 처리해야 한다면 SQL이 길어지고 복잡해집니다. 그러므로 데이터가 변할 가능성이 지극히 적고, 자주 사용된다면 컬럼을 추가해 미리 값을 계산해서 놓는 것이, SQL 작성에도 유리하며 성능상에서도 큰 이득이 있습니다.
이처럼 컬럼을 추가해 미리 값을 계산해 놓을때는 아래와 같은 사항이 중요합니다.
1. 데이터가 변할 가능성이 지극히 적어야 한다.
2. 데이터가 변경되면 미리 계산된 값도 같이 처리해야 한다는 점을 데이터 관리자가 잘 알고 있어야 한다.
무엇보다도 2번의 사항이 중요합니다. 데이터 변경이 발생했는데, 미리 계산된 값을 변경하지 않는다면 이는 데이터 불일치로 인해 사용자로 하여금 시스템의 불신을 만들 수 있게 됩니다. 실제 현장에서도 미리 계산된 값을 컬럼으로 추가해야 한다면 이 부분에 주의를 기울이시기 바랍니다.
등락률 컬럼을 추가하는 일은 어렵지 않습니다. 테이블에 ALTER문만 사용하면 됩니다. 하지만, 여기서 프로세스상 중요한 것은 반드시 ERD를 먼저 수정하는 것입니다. 현장에서 오래 일하다 보면, 다양한 이유로 ERD 변경 없이 테이블을 직접 변경하는 경우가 생깁니다. (귀찮거나, 바쁘거나, 또는... 귀찮거나.. 귀찮아서... 귀찮아서...) 이처럼 작업을 진행하다 보면 ERD와 실제 테이블간에 차이점이 생기기 시작하고 나중에 손대기 복잡해질 수 있습니다.
또한, ERD를 먼저 열어서 변경하다 보면, 혹시나 비슷한 작업을 한 적이 있는지도 알 수 있으며, 변경할 작업이 다른 테이블에 영향을 주는지도 살펴볼 수 있습니다. 반드시 ERD를 먼저 변경하는 습관을 갖고 테이블 작업을 진행하시기 바랍니다.
위의 그림과 같이 등락률을 테이블의 마지막 컬럼에 추가한 후에, 다음과 같이 ALTER문을 이용해 PRICE_DT에 컬럼을 추가합니다.
ALTER TABLE DB_DTECH.PRICE_DT ADD CHG_RT DECIMAL(18,3) NULL COMMENT '등락률';
여기서 한 가지 더, 컬럼을 추가한 후에 컬럼의 순서를 변경하는 경우가 종종 있습니다. 불가능한 것은 아니지만, 데이터가 많아지면 데이터베이스에 큰 무리를 주는 작업입니다. 그러므로 나중에 추가되는 컬럼은 가능하면 순서를 위로 올리지 않고 마지막 컬럼으로 그대로 두는 것이 좋습니다.
마지막으로 추가한 CHG_RT 컬럼에 등락률을 업데이트합니다. 저번글에서 LEAD를 사용해 등락률을 구한 로직을 응용하면 됩니다. 아래와 같습니다.
UPDATE DB_DTECH.PRICE_DT A
INNER JOIN (
SELECT T3.STK_CD
,T3.DT
,ROUND((T3.CLSE_PRC - T3.BFOR_CLSE_PRC) / T3.BFOR_CLSE_PRC * 100,2) CHG_RT # 등락률
FROM (
SELECT T1.STK_CD ,T1.STK_NM ,T2.DT ,T2.CLSE_PRC
,LEAD(T2.CLSE_PRC,1) OVER(ORDER BY T2.DT DESC) BFOR_CLSE_PRC
FROM DB_DTECH.STOCK_KRX T1
INNER JOIN DB_DTECH.PRICE_DT T2
ON (T2.STK_CD = T1.STK_CD)
WHERE T1.STK_NM = '삼성전자'
ORDER BY T2.DT ASC
) T3
) B
ON (A.STK_CD = B.STK_CD
AND A.DT = B.DT)
SET A.CHG_RT = B.CHG_RT;
오늘은 삼성전자 주가를 이용해 분석함수 중에 하나인 LEAD와 LAG를 간단히 살펴보겠습니다.
'평생 필요한 데이터 분석'에서는 분석함수를 매우 길게 설명하지만 LEAD와 LAG에 대한 설명은 없습니다. 책에서는 RANK와 같은 순위 분석함수를 통해 분석대상에 대해 집중 설명합니다. 분석대상을 잘 이해한다면 다른 분석함수를 응용하는 것은 어렵지 않기 때문입니다.
LEAD와 LAG는 조회 결과 중에 몇 건 이전의 값 또는 몇 건 이후의 값을 가져오는 역할을 합니다. 이전 또는 이후의 값을 가져오므로 이전과 이후를 판단할 수 있는 ORDER BY를 OVER절에 적어주어야 합니다.
그런데.!!! 그런데!!! MySQL의 경우는 OVER절에 ORDER BY를 생략해도 LEAD와 LAG가 정상 동작합니다. 오라클에서는 반드시 OVER절에 ORDER BY를 적어주어야 합니다. 가능하면 OVER절의 ORDER BY를 적어주는 것이 좋습니다. LEAD와 LAG를 통해 가져오는 값을 명확히 알 수 있기 때문입니다.
LEAD와 LAG를 익히기 위해서는 아래 내용을 먼저 외웁니다. - LEAD: 다음값 - LAG: 이전값
다시 한번, LEAD는 다음값, LAG는 이전값입니다. 그런데 다음이나 이전이라는 것은 어떤 기준으로 정렬된 데이터에서만 판단 가능합니다. 정렬된 데이터에서 다음값은 다음(아래)에 출력된 값이고, 이전값은 이전(위쪽)에 출력된 값을 뜻합니다. 저는 보통 'LEAD = 다음값'만 외워서 사용합니다. LEAD와 ORDER BY만 적절히 조합하면 LAG와 같은 결과를 만들수 있기 때문입니다.
먼저, LEAD의 개념을 잡기 위해 아래 SQL을 실행해봅니다.
[SQL-1]
SELECT T1.STK_CD ,T1.STK_NM ,T2.DT ,T2.CLSE_PRC
,LEAD(T2.DT,1) OVER(ORDER BY T2.DT ASC) NEXT_DT
FROM DB_DTECH.STOCK_KRX T1
INNER JOIN DB_DTECH.PRICE_DT T2
ON (T2.STK_CD = T1.STK_CD)
WHERE T1.STK_NM = '삼성전자'
AND T2.DT <= STR_TO_DATE('20210813','%Y%m%d')
AND T2.DT >= STR_TO_DATE('20210807','%Y%m%d')
ORDER BY T2.DT ASC;
[결과]
STK_CD STK_NM DT CLSE_PRC NEXT_DT
======== ============== ============ =========== ============
005930 삼성전자 2021-08-09 81500.000 2021-08-10
005930 삼성전자 2021-08-10 80200.000 2021-08-11
005930 삼성전자 2021-08-11 78500.000 2021-08-12
005930 삼성전자 2021-08-12 77000.000 2021-08-13
005930 삼성전자 2021-08-13 74400.000 NULL
위 SQL의 이해를 돕기 위해 결과를 그려보면 아래 [그림-1]과 같습니다.
[그림-1]
[그림-1]에서 1번 부분에 해당하는 좌측의 결과는 분석함수인 LEAD를 제외한 SQL의 결과입니다. 이처럼 분석함수가 사용될때는, 분석함수를 제회한 결과가 먼저 만들어지고, 이에 대해 분석함수가 처리된다고 이해하는 것이 중요합니다.
2번 부분은 분석함수가 처리된 컬럼입니다. LEAD를 사용했으므로 다음값을 가져옵니다. '다음값'이라는 것은 LEAD의 OVER절 안의 ORDER BY에 따라 결정됩니다. 다시 한번 !! "LEAD의 다음값은 OVER절 안의 ORDER BY에 따라 결정된다." 외워놓으시면 됩니다. LEAD(T2.DT,1)을 사용했으므로 실제 가져와서 보여주는 값는 다음 데이터의 DT값이 됩니다. 그러므로 다음 데이터의 DT 값이 NEXT_DT에 표시가 되는 것입니다. 이때, LEAD(T2.DT,2)를 사용했다면 다음, 다음 값이 출력이 되었을 것입니다. LEAD(T2.DT, 3)이라면 아시겠죠? 세 건 다음 값인, 다음, 다음, 다음 값이 출력이 됩니다. [그림-1]에서 마지막 로우의 DT는 '2021-08-13'입니다. 조회된 데이터 중에 '2021-08-13'보다 큰 데이터가 없으므로 LEAD의 결과는 NULL이 됩니다.
[SQL-1]에서는 LEAD를 사용해 다음 일자(DT) 값을 가져왔습니다. 이번에는 LEAD를 사용해 이전 일자 값도 가져와 보도록 하겠습니다. 아래 [SQL-2]의 BFOR_DT에 해당하는 부분입니다.
[SQL-2]
SELECT T1.STK_CD ,T1.STK_NM ,T2.DT ,T2.CLSE_PRC
,LEAD(T2.DT,1) OVER(ORDER BY T2.DT ASC) NEXT_DT
,LEAD(T2.DT,1) OVER(ORDER BY T2.DT DESC) BFOR_DT
FROM DB_DTECH.STOCK_KRX T1
INNER JOIN DB_DTECH.PRICE_DT T2
ON (T2.STK_CD = T1.STK_CD)
WHERE T1.STK_NM = '삼성전자'
AND T2.DT <= STR_TO_DATE('20210813','%Y%m%d')
AND T2.DT >= STR_TO_DATE('20210807','%Y%m%d')
ORDER BY T2.DT ASC;
[결과]
STK_CD STK_NM DT CLSE_PRC NEXT_DT BFOR_DT
======== ============== ============ =========== ============ ============
005930 삼성전자 2021-08-09 81500.000 2021-08-10 NULL
005930 삼성전자 2021-08-10 80200.000 2021-08-11 2021-08-09
005930 삼성전자 2021-08-11 78500.000 2021-08-12 2021-08-10
005930 삼성전자 2021-08-12 77000.000 2021-08-13 2021-08-11
005930 삼성전자 2021-08-13 74400.000 NULL 2021-08-12
위 SQL에서, NEXT_DT와 BFOR_DT 모두 LEAD를 사용하고 있지만, OVER절의 ORDER BY를 다르게 사용하므로 나오는 결괏값이 다른 것을 알 수 있습니다. NEXT_DT는 DT를 ASC(오름차순)했으므로 현재 로우보다 DT값이 큰 값이 다음값이 됩니다. 반면에 BFOR_DT는 DT를 DESC(내림차순) 했으므로 현재 로우보다 DT값이 작은 값이 다음값이 됩니다. 이처럼 LEAD는 조회 결과의 정렬 순서에 따라 다음값이 판단되는 것이 아니라, OVER절의 ORDER BY에 따라 판단된다는 점을 잘 기억하시기 바랍니다.
이번에는 LAG를 사용해 [SQL-2]의 LEAD와 완전히 같은 결과를 만들어보겠습니다. 아래 [SQL-3]과 같이 OVER절의 ORDER BY만 역으로 사용하면 됩니다.
LEAD와 LAG에 대해서는 이해했을 것이라 생각합니다. 이제 LEAD를 이용해 삼성전자의 일별 등락률을 구해보도록 하겠습니다. 일별 등락률의 계산 공식은 아래와 같습니다. - 일별 등락률 = (오늘 종가 - 어제 종가) / 어제 종가 * 100 일별 등락률을 구하기 위해서는 조회된 일별 주가에 어제 종가도 같이 추가를 해야 합니다. 아래와 같이 LEAD를 사용하면 간단히 처리할 수 있겠죠.
[SQL-4]
SELECT T1.STK_CD ,T1.STK_NM ,T2.DT ,T2.CLSE_PRC
,LEAD(T2.CLSE_PRC,1) OVER(ORDER BY T2.DT DESC) BFOR_CLSE_PRC
FROM DB_DTECH.STOCK_KRX T1
INNER JOIN DB_DTECH.PRICE_DT T2
ON (T2.STK_CD = T1.STK_CD)
WHERE T1.STK_NM = '삼성전자'
AND T2.DT <= STR_TO_DATE('20210813','%Y%m%d')
AND T2.DT >= STR_TO_DATE('20210807','%Y%m%d')
ORDER BY T2.DT ASC;
[결과]
STK_CD STK_NM DT CLSE_PRC BFOR_CLSE_PRC
======== ============== ============ =========== ===============
005930 삼성전자 2021-08-09 81500.000 NULL
005930 삼성전자 2021-08-10 80200.000 81500.000
005930 삼성전자 2021-08-11 78500.000 80200.000
005930 삼성전자 2021-08-12 77000.000 78500.000
005930 삼성전자 2021-08-13 74400.000 77000.000
LEAD를 사용해 조회된 데이터 로우별로 어제 종가(BFOR_CLSE_PRC)를 가져온 것을 알 수 있습니다. 이제 이 값을 사용해 등락률을 계산하면 됩니다. 바로 계산하면 SQL이 좀 지저분해지므로, [SQL-4]의 결과를 인라인 뷰로 처리합니다.
오늘은 파이썬을 이용해 주가 이력 데이터를 가져와서 쌓는 방법을 살펴보겠습니다. 종목마스터와 주가 이력 데이터만으로 우리는 많은 SQL 연습과 데이터 분석을 해볼 수 있습니다.
여기서는 파이썬과 야후 파이낸스를 이용해 주가 데이터를 가져옵니다. 해당 기능을 사용하기 pip를 사용해 yfinance와 pandas-datareader 모듈이 설치되어 있어야 합니다. 설치 방법은 anaconda prompt나 파이썬 prompt 창에서 pip install을 사용하면 됩니다. (아나콘다를 사용하시는 경우 이무 설치되어 있을수도 있습니다.)
야후 파이낸스에서 삼성전자의 주가를 가져오는 파이썬 코드는 아래와 같이 매우 간단합니다. 실제 야후파이낵스에서 주가를 가져와 데이터를 담는 과정은 pdr.get_data_yahoo 단 하나의 모듈만 호출하면 됩니다.
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()
stk_hist = pdr.get_data_yahoo('005930.KS',start='2000-01-01')
print(stk_hist)
stk_hist.to_excel('005930.xlsx',sheet_name = '005930')
삼성전자의 종목코드는 005930입니다. 야후에서 삼성전자의 주가를 가져오기 위해서는 위와 같이 005930 뒤에 .KS를 추가해서 넘겨야 합니다. 위 코드의 마지막 줄은 가져온 삼성전자 주가를 엑셀 파일로 저장하는 것입니다. 이처럼 파이썬의 pandas를 사용하면 데이터를 엑셀로 저장하는 것도 단 한줄이면 해결됩니다. 참 쉽죠?
저희는 가져온 데이터를 DB에 담아야 하니까요. 먼저 주가 데이터를 담을 테이블 구조를 설계해봅니다. 아래와 같이 설계를 하도록 하겠습니다. (평생 필요한 데이터 분석에서 동일한 기능을 하는 테이블의 이름은 HISTORY_DT입니다. 혼선이 없도록 여기서는 PRICE_DT라는 테이블 명을 사용했습니다.)
테이블을 만들었으면, 다시 파이썬으로 돌아와서 가져온 종목 리스트를 저장하도록 코딩할 차례입니다. 우선은 코스닥 종목 리스트만 DB에 저장하도록 하겠습니다. 앞에서 작성한 # [PyCode-1] 에 이어서 아래 코드를 작성합니다. 가져온 코스닥 종목 리스트를 한 건씩 읽으면서 STOCK_KRX 테이블에 한 건씩 INSERT 처리하고 있습니다.
위의 코드를 실행한 후에, 다시 DBeaver와 같은 툴로 MySQL에 접속해 테이블을 조회해보면 저장된 종목 데이터를 확인할 수 있습니다.
# [SQL-2]
SELECT *
FROM DB_DTECH.STOCK_KRX;
지금까지, 종목 리스트를 KRX에서 어떻게 가져오는지, 저장은 어떻게 처리하는지 살펴봤습니다. 지금까지의 코드를 정리해서 아래와 같은 최종 파이썬 코드를 작성합니다. 데이터 저장하는 과정을 모듈(함수)화 해서 코스피와 코스닥을 같이 처리할 수 있도록 했습니다. 그리고, 기존에 데이터가 존재하면 업데이트하도록 INSERT ON DUPLICATE 구문을 사용했습니다. (INSERT ON DUPLICATE는 한 테이블에 Key가 여러개 일 때는 사용하면 안되는 구문이라는 걸 참고해주세요.)
오늘은 파이썬을 이용해 MySQL 에 접속을 해서 데이터를 가져와보고, 간단하게 차트도 하나 그려보겠습니다. 아무래도, 요즘에 신입 취업을 위해서는 파이썬도 거의 필수가 되어가는 느낌입니다. 부지런히 준비할 필요가 있습니다.~!
파이썬의 장점 중에 하나는 많은 모듈들이 제공되고 있고, 모듈만 잘 활용하면 정말 손쉽게 기능을 구현할 수 있다는 점입니다. DB연결 및 차트 그리는 과정도 마찬가지입니다. 여기서는 파이썬을 이용해 '평생 필요한 데이터 분석'의 DB_SQLSTK 데이터베이스에 접속을 합니다.
저 같은 경우는 Anaconda와 PyCharm을 설치해서 사용하고 있습니다. Anaconda는 파이썬의 주요 모듈을 모아놓은 패키지라고 생각하시면 됩니다. 파이썬 대신에 Anaconda를 설치하시면 됩니다. PyCharm은 파이썬 코딩을 할 수 있는 툴이라고 생각하시면 됩니다.
Anaconda의 경우 32비트와 64비트 버젼이 있습니다. 만약에 나중에 증권사 API를 통해 주식 데이터를 모으는 작업도 진행할 예정이라면 32비트를 설치하는 것이 좋습니다. 반면에 머신러닝등의 작업을 할 예정이라면 64bit 버젼을 설치해야 합니다. 64비트를 설치한 후에 가상환경을 만들어 32비트 모듈도 별도 처리할 수 있다고 하니 참고바랍니다.(저는 그렇게 해본적은 없고 그냥 32비트를 사용중입니다.)
그러면, 본격적으로 MySQL에 접속해서 간단한 차트까지 그려보겠습니다. 가장 먼저 할일은 필요한 모듈을 import하는 것입니다. 아래와 같습니다.
import pymysql #mysql 연결및 실행을 위한 모듈
import pandas as pd
import matplotlib.pyplot as plt #차트 처리를 위한 모듈
이번에는 파이썬에서 MySQL에 접속해보도록 하겠습니다. 아래와 같습니다.
# MySQL 연결 처리
myMyConn = pymysql.connect(user='root', password='1qaz2wsx', host='localhost', port=3306,charset='utf8', database='DB_SQLSTK')
myMyCursor = myMyConn.cursor()
MySQL에 실행할 SQL을 만들어봅니다. 앞에서 설명했듯이, 평생필요한 데이터 분석의 DB_SQLSTK의 테이블을 조회합니다. 아래와 같습니다.
# 실행할 SQL 생성
sql = """
SELECT T1.STK_CD ,T1.STK_NM
,T2.DT
,T2.C_PRC
,T2.O_PRC
,T2.H_PRC
,T2.L_PRC
,T2.VOL
FROM DB_SQLSTK.STOCK T1
INNER JOIN DB_SQLSTK.HISTORY_DT T2
ON (T2.STK_CD = T1.STK_CD)
WHERE T1.STK_NM = '삼성전자'
"""
SQL을 실행하고, 결과를 바로 DataFrame에 저장합니다. DataFrame(DF)를 Print해보면 테이블 형태로 데이터가 저장된 것을 알 수 있습니다.
# DataFrame에 SQL 결과 저장
df = pd.read_sql(sql, myMyConn)
# 결과 출력
print(df)
여기까지, MySQL에 접속해서 SQL까지 실행해봤습니다.
마지막으로, 가져온 데이터에서 C_PRC(종가)만 Series 객체에 담은 후에 차트로 그려보도록 하겠습니다. 아래와 같습니다.
# 차트로 처리할 항목을 Series에 별도로 담는다.
c_prc = df['C_PRC']
c_prc.index = df['DT']
plt.figure(figsize=(11,9))
c_prc.plot(label='Close Price', title= "Samsung Close Price")
plt.legend(loc='lower left')
plt.grid(True)
plt.show()
아래와 같은 삼성전자의 종가 차트를 손쉽게 만들어 낼 수 있습니다.
전체 소스는 아래와 같습니다.
import pymysql
import pandas as pd
import matplotlib.pyplot as plt
# MySQL 연결 처리
myMyConn = pymysql.connect(user='root', password='1qaz2wsx', host='localhost', port=3306,charset='utf8', database='DB_SQLSTK')
myMyCursor = myMyConn.cursor()
# 실행할 SQL 생성
sql = """
SELECT T1.STK_CD ,T1.STK_NM
,T2.DT
,T2.C_PRC
,T2.O_PRC
,T2.H_PRC
,T2.L_PRC
,T2.VOL
FROM DB_SQLSTK.STOCK T1
INNER JOIN DB_SQLSTK.HISTORY_DT T2
ON (T2.STK_CD = T1.STK_CD)
WHERE T1.STK_NM = '삼성전자'
"""
# DataFrame에 SQL 결과 저장
df = pd.read_sql(sql, myMyConn)
# 결과 출력
print(df)
# 차트로 처리할 항목을 Series에 별도로 담는다.
c_prc = df['C_PRC']
c_prc.index = df['DT']
plt.figure(figsize=(11,9))
c_prc.plot(label='Close Price', title= "Samsung Close Price")
plt.legend(loc='lower left')
plt.grid(True)
plt.show()
오늘은 여기까지입니다. 감사합니다.!
데이터를 분석하는 과정을 공부해보고 싶으신 분은 아래의 '평생 필요한 데이터 분석'의 교육 과정을 추천합니다. 교육을 통해 SQL을 배운다면, 위 내용을 좀 더 보강할 수도 있고, 자신만의 스타일로 분석을 할 수 있습니다. SQL을 완전히 자신의 것으로 만들 수 있는 교육이니 관심 가져보시기 바랍니다. 감사합니다.~!
본격적인 설명에 앞서, 절대 어떤 종목을 추천하기 위한 글이 아니며, 본 글로 인해 투자한 종목의 손실에 대해서는 절대 누구도 책임지지 않는다는 것을 기억해주시기 바랍니다.
데이터의 정확성 역시 일차적으로는 검토했지만, 데이터 수집 시점이나 과정에서 발생한 실수로 부정확할수도 있으니 양해바랍니다.
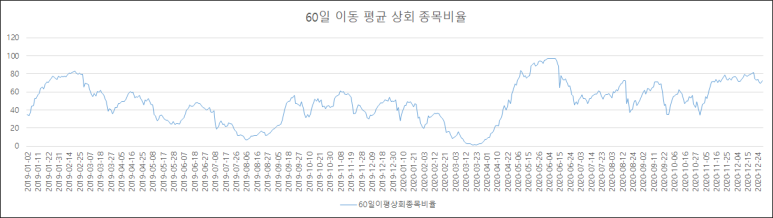
1. 60일 이동평균 상회 종목 비율 구하기
'주식시장에서 살아남는 심리투자의 법칙'에서는 50일 이동평균을 상회하는 종목수의 비율을 이용해 시장의 방향 전환을 예측할 수 있다고 설명합니다. 여기서는 60일 이동평균을 사용합니다.
'평생 필요한 데이터 분석'의 데이터베이스를 사용해 [그림-1]과 같은 차트를 만들어 냅니다.
[그림-1]
[그림-1]의 차트 데이터를 뽑아내는 로직은 아래와 같습니다.
- 코스피에 상장된 일반주만 사용합니다.(우선주, ETF, ETN등 제외)
- 2019년1월부터 2020년12월까지의 일별 주가 데이터를 사용합니다.
- 일별로 종가가 60일 이동평균을 상회하는 종목수를 카운트해서 전체 종목대비 비율을 구합니다.
- 60일 이동평균 상회 종목 비율이므로 0부터 100사이를 왔다 갔다 합니다.
위의 로직에 합당한 데이터는 '평생 필요한 데이터 분석'의 데이터와 아래 [SQL-1]을 사용해 얻을 수 있습니다. 아래 SQL로 얻은 데이터를 엑셀을 사용해 [그림-1]과 같은 차트를 만들면 됩니다.
-- [SQL-1] SQL 평생 필요한 데이터 분석 DB 사용(코스피, 일반주만)
SELECT T1.DT
,COUNT(*) 종목수
,SUM(CASE WHEN T1.C_PRC >= T1.M60_PRC THEN 1 ELSE 0 END) 60일이평상회종목수
,ROUND(SUM(CASE WHEN T1.C_PRC >= T1.M60_PRC THEN 1 ELSE 0 END)
/ COUNT(*) * 100,1) 60일이평상회종목비율
FROM DB_SQLSTK.HISTORY_DT T1
INNER JOIN DB_SQLSTK.STOCK T2
ON (T2.STK_CD = T1.STK_CD)
WHERE T2.STK_TP_NM IS NULL
AND T2.EX_CD = 'KP'
GROUP BY T1.DT
ORDER BY T1.DT;
앞에서 구한 차트에 KOSPI 지수를 매핑해서 차트를 그려봅니다. KOSPI 지수는 키움의 영웅문을 이용해 얻었습니다. [그림-1]에 KOSPI 지수를 입혀보면 아래 [그림-2]와 같습니다.
[그림-2]
[그림-2]를 보면 코로나 저점인 2020년 3월에, 60일 상회 종목비율이 5% 이하까지 내려갔습니다. 주가 최저점은 1457.65포인트였고, 해당 시점에 60일 상회 종목 비율은 1.4%입니다.
코로나 이전, 2019년 8월 초에도 60일 상회 종목 비율이 6.9%까지 내려갔습니다. 해당 시점에 주가는 하락세이긴 했지만, 코로나 시점처럼 폭락은 아니었습니다.
[그림-2]를 보면, 전반적으로 60일 상회 종목 비율이 깊이 내려갔다가, 상승하면 코스피 지수가 상승 추세로 전환하는 것으로 보입니다.
3. 과거 데이터 털어보기 - 바닥은 5% 이하?
위와 같이 2년치 데이터만 살펴봐서는 '바닥'을 찾는 방법이 잘 보이지 않습니다. 제가 가지고 있는 2002년 이후의 모든 주가 데이터와 KOSPI 지수를 합쳐서 차트를 그려봤습니다. [그림-3]과 같습니다.
[그림-3]
[그림-3]을 보면, 2008년 금융 위기때도, 60일 상회 종목 비율이 거의 0에 가깝게 떨어진 것을 볼 수 있습니다.
60일 상회 종목 비율이 5% 이하인 시점만 필터해서 조회해보면 아래 [결과-1]과 같습니다.
[결과-1]
2008년 금융위기때 저점은 968이었고, 코로나때 저점은 1457이었습니다. (일별 종가 기준)
시장에 큰 충격이 왔을때, 지수가 몇이 저점일지를 맞추는 것은 어렵습니다.
각자 생각이 다를겁니다. 코로나때 지수 지점이 1600이라고 예측한 사람은 1600에 들어갔다가 1500이 깨지자 못 버티고 손절했을겁니다. 1400이라고 생각한 사람은 기회를 놓쳤을겁니다. 2008년 지수를 경험한 사람은 1000이하를 기다리다 실패했을겁니다. 물론, 신나게 잘 잡아서 성공한 사람도 많을겁니다.
이처럼 지수를 통해 바닥을 확인하기는 만만치가 않습니다. 하지만 [그림-3]을 통해서는, 60일 이동평균을 상회하는 종목이 5% 이하로 내려가면 충격에 의한 하락의 거의 저점에 도달하는 것을 볼 수 있습니다. 사례가 2008년, 2020년 두 번밖에 없기 때문에 앞으로도 그럴 것이라고 확언할 수 없습니다.
어쨋든, 지수 저점을 맞추는 것보다, 지수를 구성하는 종목의 전체 흐름을 통해 바닥을 확인해볼 수도 있다는 것을 알 수 있습니다.
앞에서 참고한 '주식시장에서 살아남는 심리투자의 법칙'에서는 상회 비율이 방향 전환해 상승으로 나아갈때, 주식 매수에 들어가는 것이 좋다고 합니다. 즉, 바닥을 확인하고 올라가는 시점에 주식을 매수하라는 거죠. 저 역시 이 말이 맞다고 생각합니다. 바닥 밑에 지하 있고, 지하 밑에 지옥이 있기도 하니까요.
오늘은 알렉산더 엘더의 "주식시장에서 살아남는 심리 투자 법칙"이란 책을 읽다가 투자 아이디어가 생각나서, 시뮬레이션 해본 결과를 올려봅니다.
본격적인 설명에 앞서, 절대 어떤 종목을 추천하기 위한 글이 아니며, 본 글로 인해 투자한 종목의 손실에 대해서는 절대 누구도 책임지지 않는다는 것을 기억해주시기 바랍니다.
데이터의 정확성 역시 일차적으로는 검토했지만, 데이터 수집 시점이나 과정에서 발생한 실수로 부정확할수도 있으니 양해바랍니다.
"주식시장에서 살아남는 심리 투자 법칙"의 35장에서는 "50일 이동평균 상회종목"을 설명합니다.
간단히, 이야기 하면, 주식 시장에 종목들 중에 50일 이동평균을 상회하는 종목의 비율을 따라 전체 시장이 반전 될지를 어느 정도 예측할 수 있다는 내용입니다.
책에서는, 50일 이동평균을 상회하는 종목의 비율이 "대개 75퍼센트 근처에 도달하면 다시 내려오고 25퍼센트 근처에 도달하면 다시 올라간다. 나는 차트에 75퍼센트, 25퍼센트에 해당하는 지점에 두 개의 기준선을 긋고 이 수준에 도달했다가 방향을 바꾸는 시장을 찾는다" 라고 설명되어 있습니다.
그리고, "50일 이동평균 상회 종목 비율이 특정 수준에 도달할 때가 아니라 특정 수준 근처에서 방향을 선회할 때 매매 신호가 켜진다. 상단 기준선 가까이 가거나 상단 기준선을 돌파한 후 기준선 아래로 떨어지면 천장이 완성됐다는 신호다. 하단 기준선 가까이 가거나 하단 기준선을 돌파한 후 상승 전환하면 바닥이 완성됐다는 신호다."
뒤에는 더 중요한 말들이 있습니다. 주식 투자에 관심이 많다면 한번쯤 읽어볼 만한 책이라고 생각합니다.
여기서는 책에서 설명한 내용을 이용해 코스피 지수 ETF를 매매한다면 어떻게 될까를 시뮬레이션 해봤습니다.
여기서는 60일 이동평균을 사용합니다. 50일 이동평균을 계산하는 것이 어렵지는 않지만, 우선 60일 이동평균으로 위의 로직이 진짜 먹힐까를 시험해 보려고 합니다.
우선, DB_SQLSTK의 데이터베이스(평생 필요한 데이터 분석 책에서 사용하는 데이터베이스)를 사용해, 2019년부터 2020년 말까지 일별로 코스피 일반주 중에 60일 이동평균을 상회하는 종목의 비율을 구해서 엑셀의 차트로 그려봅니다. 아래와 같습니다. 비율이므로 0부터 100 사이를 왔다 갔다 합니다.
[그림 - 1]
[그림-1]을 구하는 SQL은 아주 쉽습니다. 아래와 같습니다.
SELECT T2.DT
,COUNT(*) ALL_CNT
,SUM(CASE WHEN T2.C_PRC >= T2.M60_PRC THEN 1 ELSE 0 END) OV_MV_CNT
,ROUND(SUM(CASE WHEN T2.C_PRC >= T2.M60_PRC THEN 1 ELSE 0 END) / COUNT(*) *100,2)OV_MV_RT
FROM DB_SQLSTK.STOCK T1
INNER JOIN DB_SQLSTK.HISTORY_DT T2
ON (T2.STK_CD = T1.STK_CD)
WHERE T1.STK_TP_NM IS NULL
AND T1.EX_CD = 'KP'
GROUP BY T2.DT;
이제, 위 60일 상회 종목 비율에 코스피 지수를 추종하는 ETF 중에 하나인 KODEX 200 의 주가를 겹쳐서 그려봅니다. 그리고 KODEX 200의 매수(B)와 매도(S) 시점을 잡아봅니다.
- 매수시점 : 60일 상회가 25% 밑으로 내려갔다가 25% 위로 올라오는 시점
- 매도시점: 60일 상회가 75% 위로 올라갔다가 75% 밑으로 내려오는 시점
[그림-2]
[그림-2]와 같이 결과가 형편없습니다. 제 생각을 지수 ETF를 매매하는 것이 틀렸다고 봐야겠죠. 그림을 보면, 코로나 시점에는 60일을 상회하는 종목이 거의 0%에 가까웠네요. 해당 구간을 벗어날때 매수가 들어갔다면 좋았겠지만, 앞에서 매수후 매도 조건에 들어 맞지 않았으므로 매수 하지 않았다고 가정했습니다.
그래도, 60일 이동평균을 상회하는 종목이 늘어나는 시점을 기준으로 시장을 공략해 볼수는 있어 보입니다.
위에서 테스트한 구간은 2019, 2020년 2년치입니다. 제가 가진 데이터 중에 가능한 긴 데이터를 사용해 시뮬레이션 해보면 아래와 같습니다.
2002년부터 현재까지의 60일 이동평균 상회 종목 비율의 움직임과 KODEX 200 ETF 주가의 움직입니다.
[그림-3]
매수, 매도 시점을 대략 집어 넣어 봤습니다. 수작업으로 하려니 힘드네요..
[그림-3]에서 아래쪽에 녹색 상자 위의 선이 60일 이동평균 상회 종목 비율입니다. 0부터 100 사이를 왔다 갔다 합니다. 그리고 위에 파란선은 KODEX 200 ETF의 주가입니다.
KODEX 200 ETF의 주가 위에는 빨간 점선이 그려져 있습니다. 매수와 매도 시점에 따른 주가의 흐름을 표시한 선입니다. 보면, 16번의 매매가 있었고 이 중에 두 번은 하락(5번, 15번) 나머지는 상승한 것을 볼 수 있습니다.
나빠보이지는 않습니다. 하지만 5번의 하락 정도가 매우 크고, 16번을 기점으로 유동성 대세 상승에서는 아무 수익을 얻지 못하는 것을 알 수 있습니다.
위의 그림을 봤을때는, 어느정도는 60일 이동평균 상회 종목 비율을 이용해, 지수 ETF의 움직임을 예측하는 것이 아주 불가능해 보이지는 않습니다. 다만, 60일 비율이 바닥을 만들고 틀어 올릴때 기준과.. 천정을 만들지 못하고 떨어지는 경우를 어떻게 구분해볼지 추가적인 고민이 필요해보입니다.
결국..오늘 설명 드린 내용은, "주식시장에서 살아남는 심리 투자 법칙" 책은 괜찮은거 같다... 이동평균을 상회하는 종목 비율 변화로 지수ETF를 따라가보는건 어떨까. 정도입니다.
감사합니다.
위와 같이 주식 데이터를 마음대로 분석해볼 수 있는 SQL을 공부하고 싶다면 아래 책을 참고해주세요~!
위에서 정한 기준으로 긴 아래 꼬리 음봉이 발생한 데이터를 출력해보면 아래의 [결과 - 1]과 같습니다. 결과를 출력할 때, 긴 아래 꼬리 음봉이 발생한 20일 후의 종가를 가져와 등락률도 같이 계산합니다.
[결과 - 1]
[결과 - 1] 의 내용을 종합해보면 다음과 같습니다.
- 긴 아래 꼬리 음봉 발생 횟수: 13회 (2019~2020년 사이)
- 20 거래일 후 5% 이상 상승 횟수: 5회
- 20 거래일 후 5% 이상 상승 확률: 38%
정리하면, 여기서 정한 '긴 아래 꼬리 길이' 기준으로 매매를 하게 된다면 20 거래일 후 5% 이상 상승할 확률이 38% 정도라고 볼 수 있습니다. (이러한 확률을 적용하기에는 모수가 너무 적지 않나 생각이 듭니다.)
중요한건, 제가 위에서 정한 기준에 따라 이러한 확률이 나온 것이고, 각자 기준을 변경해 본다면 더 좋은 확률이 나올 수 있습니다.(예를 들어, 거래금액이 더 높아야 한다거나, 다음날에 상승이 어느정도 되어야 한다거나)
[결과 - 1]에서 첫 번째 데이터를 살펴보면, '지누스' 종목에서 2020년 4월 2일에 긴 아래 꼬리 음봉이 나왔고, 20 거래일 후에 53%나 상승을 했습니다. 실제 차트를 살펴보면 아래 [그림 - 2]와 같습니다.
[그림 - 2]
단순하게, 위 결과만 보고 '긴 아래 꼬리 음봉'='상승'이라고 생각하면 안되겠죠. [결과 - 1]의 마지막 데이터를 보면, 공교롭게도 같은 종목인 '지누스'에서 2020년 2월 8일에도 긴 아래 꼬리 음봉이 나왔고, 해당 일자의 20일 후에는 오히려 -25% 하락이 발생했습니다. 아래 [그림 - 3]과 같습니다.
[그림 - 3]
무조건 '긴 아래 꼬리 음봉'이 나온다고 상승하지 않는다는 것을 알 수 있습니다.
위 차트를 보며 생각해 보니, 떨어진 경우는 2020년 3월 코로나로 모두가 급락한 것이고, 오른 시점은 코로나 이후 대세 상승한 케이스에 지나지 않나 생각도 듭니다.
당연히, 단순히 이 신호만으로 성공할 수 있다면 세상 모든 사람이 부자가 되었겠죠. ^^
내친김에, 2010년 이후로 현재(2021년7월8일)까지 여기서 정한 기준을 적용해 종목을 찾아보면 아래 [결과 - 2]와 같습니다. (아래 결과는 개인적으로 수집, 관리하는 일별주가 데이터를 사용했습니다.)
[결과 - 2]
[결과 - 2]의 내용을 종합해 보면 아래와 같습니다.
- 긴 아래 꼬리 음봉 발생 횟수: 55회 (2010~2021년 7월 8일 사이)
- 20 거래일 후 5% 이상 상승 횟수: 19회
- 20 거래일 후 5% 이상 상승 확률: 35%
35%라는 확률이 의미가 있는지 잘 모르겠습니다. 더욱이 기준에 따라 확률의 변화 정도가 크기 때문이죠.