이번 글에서는 세 가지 요소 중에 인덱스에 대해 살짝 맛을 보도록 하겠습니다. 인덱스의 개념에 대해서는 아마도 다음 글에 설명이 될거 같습니다.
1. INDEX를 만들어보자.
인덱스는 RDBMS에서 데이터를 빠르게 찾을 수 있도록 해주는 객체입니다. 보통은 테이블별로 인덱스를 여러 개 만들 수 있으며, 데이터를 접근하는 주요 패턴을 분석해 인덱스를 설계합니다.
데이터를 접근하는 주요 패턴을 분석한다는 것을 "아주 간단히" 이야기 하자면, SQL의 WHERE 절이나, 조인절에서 사용된 조건 컬럼을 분석하는 것입니다. ("아주 간단히"를 강조한 이유는, 실전에서 인덱스 설계는 그렇게 간단한 문제가 아니기 때문입니다.)
아래와 같은 SQL이 있다고 해보죠.
SELECT COUNT(*) ORD_CNT
FROM MYTUNDB.T_ORD_BIG T1
WHERE T1.ORD_DT >= STR_TO_DATE('20170201','%Y%m%d')
AND T1.ORD_DT < STR_TO_DATE('20170202','%Y%m%d');
위 SQL을 EXPLAIN ANALYZE를 통해 실제 실행계획을 추출해보면 아래와 같습니다. 아래 실행계획에서 가장 윗 줄에 actual time이 해당 SQL의 총 실행시간입니다. 535.476 ~ 535.478 밀리세컨드(0.53초)가 걸렸습니다.
위 SQL에서 WHERE절에 사용된 조건은 T_ORD_BIG의 ORD_DT 컬럼입니다. 그러므로 T_ORD_BIG에 ORD_DT에 인덱스를 만들어 성능 개선을 고려할 수 있습니다. 실제로 인덱스를 만들어보고 성능이 개선되는지 확인해봅니다.
아래 구문을 통해 T_ORD_BIG_X1이라는 인덱스를 생성합니다. T_ORD_BIG_X1은 MYTUNDB.T_ORD_BIG 테이블의 ORD_DT로 구성된 인덱스입니다.
CREATE INDEX T_ORD_BIG_X1 ON MYTUNDB.T_ORD_BIG(ORD_DT);
인덱스를 생성했다면, 다시 위의 SELECT SQL을 EXPLAIN ANALYZE로 실행해봅니다. 아래와 같은 실행계획이 나오는 것을 알 수 있습니다. 전체 실행 시간인, 가장 위의 actual time이 0.045 밀리세컨드(0.000045초) 밖에 안되는 것을 알 수 있습니다.
-> Aggregate: count(0) (actual time=0.045..0.046 rows=1 loops=1)
-> Filter: ((mytundb.t1.ORD_DT >= <cache>(str_to_date('20170201','%Y%m%d'))) and (mytundb.t1.ORD_DT < <cache>(str_to_date('20170202','%Y%m%d')))) (cost=1.21 rows=1) (actual time=0.041..0.041 rows=0 loops=1)
-> Index range scan on T1 using T_ORD_BIG_X1 (cost=1.21 rows=1) (actual time=0.039..0.039 rows=0 loops=1)
이처럼, WHERE 절의 조건에 인덱스를 잡는 것만으로, 아래와 같이 성능 개선이 되었습니다.
개선전후 시간 : 0.53초 -> 0.000045초
지금 살펴본 내용으로 아래 정도의 개념을 알 수 있습니다.
인덱스를 만들면 조회 속도가 빨라진다.
WHERE 절의 조건 컬럼에 인덱스를 고려한다.
하지만, 이 개념과 지식만으로 인덱스를 만들어대기 시작하면 매우 위험해집니다. (시스템이 오히려 문제가 생길 수 있습니다.) 실전에서 튜닝을 하고, 인덱스 설계를 위해서는 더 많은 경험과 공부가 필요합니다.
MySQL에서 실제 실행된 SQL의 실행계획을 보기 위해서는 EXPLAIN ANALYZE를 사용합니다. 아래와 같이 EXPLAIN ANALYZE를 추가해서 SQL을 실행하면, SQL이 실제 실행이 되면서, 실제 사용한 실행계획을 확인할 수 있습니다. (이전글에서 살펴본 실행계획은 예상 실행계획입니다.)
EXPLAIN ANALYZE
SELECT T2.CUS_ID, T2.CUS_NM ,T1.*
FROM MYTUNDB.T_ORD_BIG T1
INNER JOIN MYTUNDB.M_CUS T2 ON (T2.CUS_ID = T1.CUS_ID)
WHERE T1.ORD_SEQ <= 10;
위 SQL을 실행하면, SQL의 결과대신에 아래와 같은 실행계획이 출력됩니다. 실행 계획만 출력되지만 실제 SQL은 실행된 것과 다름없습니다.
-> Nested loop inner join (cost=14.03 rows=10) (actual time=0.871..0.898 rows=10 loops=1)
-> Filter: (mytundb.t1.ORD_SEQ <= 10) (cost=3.03 rows=10) (actual time=0.074..0.089 rows=10 loops=1)
-> Index range scan on T1 using PRIMARY (cost=3.03 rows=10) (actual time=0.070..0.080 rows=10 loops=1)
-> Single-row index lookup on T2 using PRIMARY (CUS_ID=mytundb.t1.CUS_ID) (cost=1.01 rows=1) (actual time=0.080..0.080 rows=1 loops=10)
MySQL을 설치하면 Workbench라는 SQL 툴이 같이 설치됩니다. Workbench에서는 SQL의 실행계획을 그래픽으로 Visual하게 확인할 수도 있습니다.
1. Visual하게 실행 계획 보기
쿼리 창에, SQL을 입력한 후에 Workbench의 아래 메뉴를 실행합니다.
- Workbench 상단 메뉴 중에 Query 선택 > Explain Current Statement 를 선택
- 또는 Ctlr + Alx + X 를 바로 누르셔도 됩니다.
SELECT T2.CUS_ID, T2.CUS_NM ,T1.*
FROM MYTUNDB.T_ORD_BIG T1
INNER JOIN MYTUNDB.M_CUS T2 ON (T2.CUS_ID = T1.CUS_ID)
WHERE T1.ORD_SEQ <= 10;
SQL을 입력한 후에 Explain Current Statement를 선택하면 아래와 같이 Visual하게 실행계획을 확인할 수 있습니다. Tree 형태나 표 형태로 볼때보다 훨씬 더 쿼리가 처리되는 내부적인 흐름을 보기에 유용합니다. 아래의 각 단계에 마우스를 가져다 대면 추가적인 정보도 확인할 수 있습니다. 보여지는 내용을 보면, 'EXPLAIN Format = JSON'의 내용을 요약해서 보여주는거 같습니다.
튜닝 관련해서는 오라클 쪽에서 많이 진행되다 보니, 튜너들에게는 위와 같은 형식 보다는 Tree 형태의 실행계획을 더 선호합니다. 어떤 방식으로 보든, 성능 개선이라는 결과를 얻을 수 있다면 각자 편한 형태로 보시는 걸 추천드립니다.
오늘은 여기까지입니다. 감사합니다.
SQL을 완벽히 배우는 방법 StartUP SQL!
StartUP SQL의 완전 무료 강의 노트를 오픈했습니다.(온라인 E-Book / ALL FREE ACCESS)
SQL 튜닝을 위해서는 실행 계획이라는 것을 볼 줄 알아야 합니다. 실행 계획은 RDBMS의 옵티마이져(쿼리최적화기)가 SQL을 DBMS 내부적으로 어떻게 처리하겠다고 만들어 놓은 작업 계획서입니다. 옵티마이져가 생성한 실행계획에 따라 SQL의 성능은 달라집니다. 옵티마이져는 SQL과 테이블의 통계, 인덱스 등을 참고해 최적의 실행계획을 만드려고 노력합니다. 우선은 MySQL에서 실행계획을 어떻게 볼 수 있는지 정도만 알고 넘어가면 될거 같습니다.
MySQL에서 제공하는 가장 고전적인 방법입니다. EXPLAIN 뒤에 쿼리를 적어 놓고 실행하면 됩니다.
EXPLAIN
SELECT T2.CUS_ID, T2.CUS_NM ,T1.*
FROM MYTUNDB.T_ORD_BIG T1
INNER JOIN MYTUNDB.M_CUS T2 ON (T2.CUS_ID = T1.CUS_ID)
WHERE T1.ORD_SEQ <= 10;
위와 같이 쿼리를 실행하면 아래와 같이 표형태로 실행계획이 출력됩니다. 오라클과 같은 환경에서 튜닝을 하던 분들께는 매우 생소한 스타일로 실행계획이 표현됩니다. 아래 실행계획을 이해하려면 각각의 항목을 이해해야 하는데, 이에 관련해서는 기회가 된다면 나중에 별도로 다루도록 하겠습니다.
2. EXPLAIN FORMAT = JSON
EXPLAIN 에 JSON 포맷을 지정할 수 있습니다. 아래와 같이 실행하면 JSON 형태의 실행계획이 나오면, EXPLAIN으로만 확인할 수 없는 다양한 정보도 같이 확인이 가능합니다. 다만, 정보가 너무 많고 길어서 비효율적입니다.
EXPLAIN FORMAT = JSON
SELECT T2.CUS_ID, T2.CUS_NM ,T1.*
FROM MYTUNDB.T_ORD_BIG T1
INNER JOIN MYTUNDB.M_CUS T2 ON (T2.CUS_ID = T1.CUS_ID)
WHERE T1.ORD_SEQ <= 10;
3. EXPLAIN FORMAT = TREE
MySQL 8부터는 Tree 형태의 실행계획을 제공합니다. 오라클을 주로 튜닝하셨던 분들께는 매우 유용한 기술입니다.
EXPLAIN FORMAT = TREE
SELECT T2.CUS_ID, T2.CUS_NM ,T1.*
FROM MYTUNDB.T_ORD_BIG T1
INNER JOIN MYTUNDB.M_CUS T2 ON (T2.CUS_ID = T1.CUS_ID)
WHERE T1.ORD_SEQ <= 10;
아래와 같은 Tree 형태의 실행계획이 나옵니다.
-> Nested loop inner join (cost=14.03 rows=10)
-> Filter: (mytundb.t1.ORD_SEQ <= 10) (cost=3.03 rows=10)
-> Index range scan on T1 using PRIMARY (cost=3.03 rows=10)
-> Single-row index lookup on T2 using PRIMARY (CUS_ID=mytundb.t1.CUS_ID) (cost=1.01 rows=1)
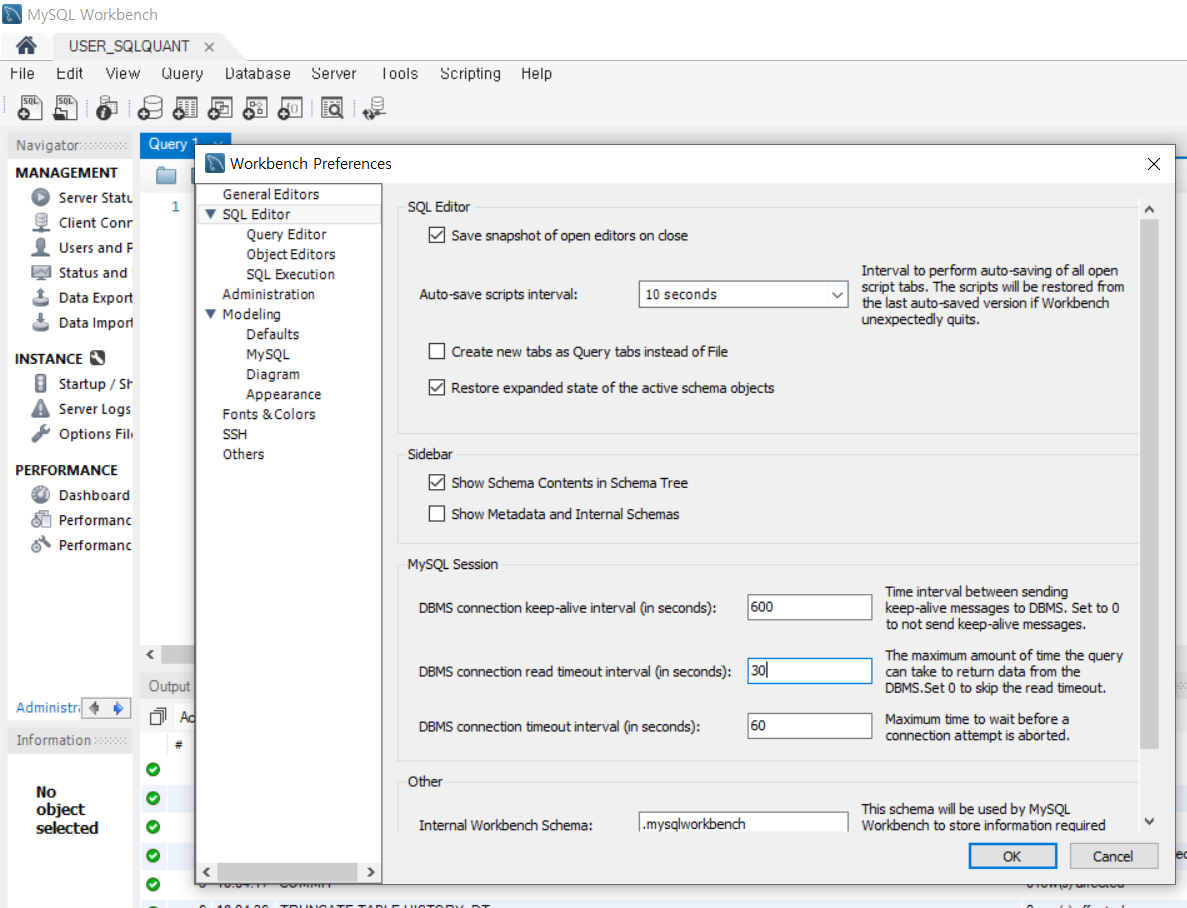
Tip. MySQL Workbench에서 Tree 형태나 Json 형태로 실행계획을 확인해보면, 실행계획의 내용이 모두 출력 안될 수도 있습니다. MySQL Workbench에서 출려 가능한 컬럼의 Bytes를 설정하기 때문입니다. 아래와 같은 과정으로 컬럼(Field)에서 보여줄 수 있는 길이의 제한을 풀어줘야 합니다. - Workbench 상단 메뉴 중 Edit -> Preferences... 선택 -> 좌측에서 SQL Editior > SQL Execution 선택 > - Max. Field alue Lengh to Display (in Bytes): 를 9999999 로 설정
- 'Check Requirements' 에서 'Microsoft Visual C++ 2019 redi~'가 필요사항으로 되어 있으면, 정상적으로 설치가 되지 않습니다. 'Check Requirements'에서 'Microsoft Visual C++ 2019 redi~'를 선택한 후에 Execute를 누른후 해당 항목을 설치후 MySQL을 재설치하도록 해주세요.
1. Setup Type을 선택합니다.
- Developer Default로 해주세요.(Fig.1)
Fig.1 Setup Type 선택
2. Check Requirements
- 'Microsoft Visual C++ 2019 Redist..'가 없으면 MySQL을 제대로 설치할 수 없습니다.
- 'Microsoft Visual C++ 2019 Redist..'를 선택하신 후 Execute를 눌러 해당 항목을 다운받아 설치합니다.
- 'Microsoft Visual C++ 2019 Redist..'가 설치 된 후 MySQL 설치를 계속해 나갑니다.
Fig.2 Execute로 Microsoft Visual C++2019 Red...를 설치
Fig.3 - 위의 두 항목은 설치가 필요 없습니다.
Fig.4 - 일부 항목이 없어도 괜찮습니다. Yes로 넘어갑니다.
3. Installation
- Execute로 설치를 진행합니다.
- 모두 설치 된 후 Next버튼으로 넘어갑니다.
(Connector/Python (3.7) 은 설치 안되어도 상관 없습니다.)
Fig.5 - Execute
4. Product Configuration
Fig.6 - Next
5. High Availabilty
- Next 눌러 주시면 됩니다.
Fig.7 - Next
6. Type and Networking
- 역시 Next 눌러주시면 됩니다.
- 여기서, Port가 3306으로 되어 있는걸 기억해 주세요.
- MySQL의 기본포트가 3306입니다.
- 필요에 따라 Port를 변경하셔도 됩니다.
Fig.8 - Type and Networking
7. Authentication Method
- 인증모드를 설정합니다. Use Strong Password가 기본입니다.
- 저 같은 경우 노트북에서만 사용할 것이므로 보다 편한 Use Legacy로 설정했습니다.
Fig.9 Authentication Method
8. Accounts and Roles
- Root의 Password을 설정합니다.
- 기억할 수 있는 Password로 설정해 주세요.
- 저는 1qaz2wsx를 사용했습니다.(좋은 방법은 절대 아닙니다.)
- 여기서 일반 사용자를 설정할 수도 있지만 넘어갑니다.
Fig.10 - Accounts and Roles
9. Windows Service
- Next를 클릭합니다
Fig.11 - Windows Service
10. Apply Configuration
- Execute 눌러주신 후 실해 완료되면, Finish 눌러주시면 됩니다.
Fig.12 - Apply Configuration
11. Connect To Server
- 계속 Next버튼을 누르시다, 아래 화면에서만 설정했던 Root의 Password를 입력해 Check 를 눌러주시고 Next로 넘어가면 됩니다.
아래와 같이 EXPLAIN을 SELECT SQL 앞에 붙여서 실행합니다. 실행하면, SQL은 실제 실행되지 않고, 예상 실행계획이 출력됩니다.
EXPLAIN
SELECT T2.CUS_GD
,COUNT(*)
FROM T_ORD_BIG T1
INNER JOIN M_CUS T2
ON (T2.CUS_ID = T1.CUS_ID)
WHERE T1.ORD_YMD LIKE '201703%'
GROUP BY T2.CUS_GD;
# 결과
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
==== ============= ======= ============ ======== ========================================================= =============== ========= =========================== ======== ========== ===========================================
1 SIMPLE T1 None range X_T_ORD_BIG_1,X_T_ORD_BIG_3,X_T_ORD_BIG_4,X_T_ORD_BIG_5 X_T_ORD_BIG_5 35 None 360858 100.0 Using where; Using index; Using temporary
1 SIMPLE T2 None eq_ref PRIMARY PRIMARY 162 db_mysqlbooster.T1.CUS_ID 1 100.0 None
오라클과 같은 Tree 형태가 아니어서 해석이 쉽지 않습니다. 아래와 같은 내용들을 기억하고 실행계획을 해석해야 합니다.
*id : 해당 단계의 ID입니다. 값이 작을 수록 먼저 실행된다고 해석할 수 있습니다.
*select_type : 해당 단계의 쿼리 유형을 나타냅니다. - SIMPLE : 단순한 SELECT를 나타냅니다. 가장 흔하게 나타는 경우입니다. - PRIMARY : UNION이나 서브쿼리 존재시에 가장 바깥쪽 쿼리를 뜻합니다. - UNION : UNION이 존재하는 쿼리에서 두 번째 UNION 이후의 쿼리 블록입니다. - SUBQUERY : SELECT 절 또는 WHERE 절의ㅣ 서브쿼리입니다. - DERVIED : FROM절의 서브쿼리입니다.(인라인-뷰)
- DEPENDEN SUBQUERY : SELECT, WHERE 절 서브쿼리가 바깥쪽 SELECT에 컬럼을 사용할 때입니다. *table : 해당 단계의 관련 테이블입니다. *type : 해당 단계의 접근 유형입니다. -const = PK, UNIQUE KEY로 한 건만 조회 하는 경우입니다. (오라클의 INDEXUNIQUE SCAN) - ref = INDEX RANGE SCAN 인데, 같다(=) 조건을 처리하는 경우입니다. - range = INDEXRANGE SCAN 인데, 범위 조건입니다. - index = INDEX FULL SCAN , 이 부분을 가장 유의해야 합니다. - ALL = TABLE ACCESS FULL(TABLE FULL SCAN)
* 위에서 type이 index나 ALL이면 성능에 문제가 있을 수 있습니다. - eq_req = 조인에서 후행 접근하는 쪽에 나타납니다. INDEX UNIQUE SCAN 정도로 이해하면 됩니다. *possible_keys : 후보 인덱스 목록입니다. *key : 실제 사용한 인덱스 * key_len : 인덱스를 몇 바이트 사용했는지 표시합니다. 바이트에 따라, 몇 개 컬럼에 인덱스가 적용되었는지 알 수 있습니다. * rows : 예측 레코드 건수입니다.
추가로, MySQL에서 실행계획을 볼때는 JSON 형태로도 출력이 가능합니다. 아래와 같습니다.
아래와 같이 FORMAT을 Tree형태로 출력도 할 수 있습니다. 오라클을 사용하는 사용자라면 훨씬 친숙합니다. (사실 이 방법이 훨씬 실행계획 이해하기에 유리합니다.)
EXPLAIN FORMAT = TREE
SELECT T2.CUS_GD
,COUNT(*)
FROM T_ORD_BIG T1
INNER JOIN M_CUS T2
ON (T2.CUS_ID = T1.CUS_ID)
WHERE T1.ORD_YMD LIKE '201703%'
GROUP BY T2.CUS_GD;
-> Table scan on <temporary>
-> Aggregate using temporary table
-> Nested loop inner join (cost=478369.15 rows=360858)
-> Filter: (t1.ORD_YMD like '201703%') (cost=81425.35 rows=360858)
-> Index range scan on T1 using X_T_ORD_BIG_5 (cost=81425.35 rows=360858)
-> Single-row index lookup on T2 using PRIMARY (CUS_ID=t1.CUS_ID) (cost=1.00 rows=1)
이 정도를 알면, 실행계획 해석에 큰 어려움은 없을거 같습니다.
참고로, MySQL 8에서는 EXPLAIN ANALYZE를 통해 트리 형태로 실제 실행된 실행계획도 확인할 수 있습니다.
설명의 편의상 반말체로 작성한 점 양해바랍니다. pdf 파일도 첨부드리니 다운 받아 보셔도 됩니다.
오늘은 통합된 ‘업로드 마스터 테이블’을 간단히 살펴보도록 하겠다.(정말 간단히 살펴볼 것이다.) ‘업로드 마스터’ 테이블이다. 다양한 업로드 양식을 통합한 테이블이 아니다.
결과부터 보면 아래와 같이 업로드 마스터 테이블을 설계할 수 있다.
ERD의 가운데 있는 테이블이 바로 통합된 업로드 마스터 테이블이다. 엑셀이나 파일의 데이터를 시스템에 올리기 위해서는 공통적으로 관리해야 하는 컬럼들이 있다. 바로 그러한 컬럼을 모아서 업로드 마스터를 만든다. 특별히 설명하지 않아도 쉽게 이해할 수 있겠지만 특징 있는 컬럼 몇 개만 설명하고 넘어가도록 하겠다.
- 업로드시퀀스: 업로드를 실행하면 부여되는 시퀀스 값이다. - 파일명/파일경로: 업로드 작업자에게 어떤 파일을 올렸는지 정보를 제공하기 위해서 관리한다. - 업로드건수/에러건수: 처리된 건수를 저장한다. 업로드 목록을 보여줄 때 처리 건수를 보여달라는 업무 요건이 있을 때, 실제 업로드를 수행한 테이블을 접근해서 보여주기에는 성능 이슈가 있다. - 업로드테이블: 업로드 파일의 내용이 실제 저장된 테이블명을 보관한다. 그래야만, 테이블을 보고 실제 업로드한 데이터가 어느 테이블에 있는지 쉽게 찾을 수 있다.
작업 프로세스는 간단하다. 다음과 같다.
이와 같이 통합된 형태의 테이블은 다양한 업무에 사용된다. 기업에는 각종 결제가 있다. 다양한 결제가 있지만 프로세스는 거의 동일하다. 그러므로 결제 마스터 역시 통합된 테이블 구조로 설계가 가능하다.
각종 인터페이스도 이와 같이 설계가 가능하다. 다양한 시스템에서 다양한 데이터를 인터페이스 받는 시스템이라면 이와 같이 통합된 인터페이스 마스터 테이블을 설계해 유용하게 사용할 수 있다. 인터페이스에 맞는 From시스템, To시스템, 인터페이스 유형 등을 추가로 관리하기만 하면 된다.
오늘은 여기까지입니다. 정말 짧게 살펴보고 마무리했습니다. 필요한 업무에 적절히 통합된 마스터 테이블을 활용할 수 있으시기 바랍니다.
시스템을 개발해 보면, 사용자의 편의를 위해 엑셀 업로드 기능을 개발해야 할 때가 있다. 이때, 소량의 데이터를 올리는 경우라면 큰 문제가 없지만, 대량의 데이터를 업로드 해야 한다면 정교하게 프로그램을 개발해야 한다. 프로그램 코드 부분에서도 성능을 고려해야 하지만 데이터베이스에 던지는 SQL의 부하를 줄이는 것이 매우 중요하다.
엑셀 업로드를 구현할 때, 빠질 수 없는 것이 바로 데이터의 정확성을 확인하는 로직이다. 중복된 데이터가 있거나, 잘 못된 코드 값들이 입력되는 경우를 확인해서 업로드 되지 않도록 해야 한다. 이러한 데이터 체크 로직을 데이터베이스를 거치지 않고 확인할 수 있다면 좋겠지만 절대 그럴 수가 없다.
SQL BOOSTER 에 이어지는 이야기들입니다.~! SQL BOOSTER 를 보신 분들께 좀 더 도움을 드리고자 추가로 작성한 내용입니다.
여기서는 ‘이어지는 이야기 10’에서 새로 생성했던 M_SN(시리얼 마스터) 테이블을 사용해 엑셀 업로드 하는 과정을 설명하도록 하겠다.
먼저 최악의 방법을 살펴보자. 아래와 같다.
엑셀 데이터를 한 건씩 읽으면서 데이터베이스를 호출해 데이터 점검을 수행하는 방식이다. 엑셀 한 건을 위해 데이터베이스를 여섯 번 호출해야 한다. 한 번 호출에 0.01초가 걸린다고 가정했을 때, 엑셀 한 건 처리에 0.06초가 걸린다. 한 건 처리에 느린 속도는 아니다. 하지만 올리고자 하는 데이터가 만 건이라면 600초의 시간이 필요하다. 또한 업로드하려는 컬럼이 많아지고 체크 로직이 많아질수록 속도는 더 느려지게 될 것이다.
위의 체크 로직중에 시리얼번호 자릿수와 생산일자 포맷 등은 데이터베이스를 거치지 않고 프로그램 소스 레벨에서도 점검이 가능할 수 있다. 하지만 어떤 로직은 데이터베이스를 통해서, 어떤 로직은 프로그램 로직에서 처리하는 것은 프로그램 소스 관리에 혼란함을 더해주기도 한다.(그럼에도 불구하고 성능을 위해서라면 나누어 처리하는 것이 좋다.)
위의 방법은 올리고자 하는 데이터 중에 잘 못된 데이터가 있을 때도 문제다. 만약에 잘못된 데이터는 빼고 업로드 처리해야 한다면, 업로드에 실패한 데이터를 어떻게 보여줄지 고민해야 한다.
필자가 추천하는 엑셀 업로드의 데이터 체크 로직은 다음과 같다.
중간에 업로드용 테이블을 만들고, 업로드용 테이블을 이용해 업로드 된 단위로 한 번에 데이터를 체크하고, 체크 완료된 데이터만 M_SN에 밀어 넣는 방식이다. 만 건 이상의 데이터가 업로드 된다고 해도, ‘INSERT – 업로드용 테이블’ 시점 외에는 데이터베이스를 반복해서 콜 할 필요가 없다. 그렇기 때문에 매우 빠르게 데이터 정확성을 점검하고 업로드를 처리할 수 있다.
실습을 위해 아래와 같은 업로드용 테이블을 만들 예정이다.
아래 SQL로 테이블을 생성하자.
[SQL-1] M_SN_UP
CREATE TABLE M_SN_UP
(
UP_SEQ NUMBER(9) NOT NULL
,ROW_NO NUMBER(9) NOT NULL
,SN VARCHAR2(100) NULL
,PRD_YMD VARCHAR2(100) NULL
,ITM_ID VARCHAR2(100) NULL
,ITM_TP VARCHAR2(100) NULL
,UP_ERR_ID VARCHAR2(100) NULL
,SYS_REG_DTM DATE
,SYS_REG_UID VARCHAR2(40) NULL
,SYS_CHG_DTM DATE
,SYS_CHG_UID VARCHAR2(40) NULL
);
ALTER TABLE M_SN_UP ADD CONSTRAINT PK_M_SN_UP PRIMARY KEY(UP_SEQ, ROW_NO);
테스트를 위해 M_SN_UP에 데이터를 입력하도록 하자. 아래 SQL을 사용한다. 아래 SQL을 실행하면 M_SN_UP에 102건의 데이터가 만들어진다.
[SQL-2] M_SN_UP 테스트 데이터 생성
INSERT INTO M_SN_UP (UP_SEQ, ROW_NO, SN, PRD_YMD, ITM_ID, ITM_TP)
SELECT 1 UP_SEQ
,ROWNUM ROW_NO
,'E'||LPAD(ROWNUM,15,'X') SN
,CASE WHEN ROWNUM <= 10 THEN '20200230' ELSE '20200212' END PRD_YMD
,CASE WHEN ROWNUM BETWEEN 11 AND 20 THEN 'ITMXXX' ELSE 'ITM080' END ITM_ID
,CASE WHEN ROWNUM BETWEEN 21 AND 30 THEN '' ELSE 'ELEC' END ITM_TP
FROM DUAL
CONNECT BY ROWNUM <= 100
UNION ALL
SELECT 1 UP_SEQ ,101 ROW_NO ,'E'||LPAD(100,15,'X') SN ,'20200212' PRD_YMD,'ITM080' ITM_ID,'ELEC' ITM_TP FROM DUAL
UNION ALL
SELECT 1 UP_SEQ, 102 ROW_NO ,MIN(SN) SN ,'20200212' PRD_YMD ,'ITM080' ITM_ID ,'ELEC' ITM_TP
FROM M_SN
WHERE ITM_ID = 'ITM080'
;
COMMIT;
위 SQL에서 UP_SEQ는 모두 1로 설정했다. 102건을 한 번에 묶어 에러 체크 할 수 있도록 한 것이다. ROW_NO는 1부터 102까지의 숫자를 갖는다. 실제 엑셀 파일을 이용했다면 엑셀의 줄번호가 여기에 해당한다. ROW_NO가 1~10번째 데이터는 생산일자를 일부로 2월30일로 설정했다. 에러 데이터로 만든 것이다. 마찬가지로 11~20번째 데이터는 아이템ID를 ITMXXX로, 21~30번째 데이터는 아이템유형에 빈 값을 입력했다. 그리고 11~12 라인의 ROW_NO=101은 업로드 데이터 중 중복 SN을 만들고 있다. 마지막으로 14~16 라인은 M_SN에 이미 있는 SN을 입력하고 있다.
에러 체크하는 SQL을 만들어보자. 위 102건에 대해 단 여섯 개의 SQL을 실행하면 된다.
(1) 시리얼번호 존재 체크
[SQL-3] 시리얼번호는 존재하는가?
UPDATE M_SN_UP T1
SET T1.UP_ERR_ID = '이미존재하는SN'
WHERE T1.UP_SEQ = 1
AND T1.UP_ERR_ID IS NULL
AND EXISTS(
SELECT *
FROM M_SN A
WHERE A.SN = T1.SN);
업로드 할 SN 중에 M_SN에 존재하는지는 위 SQL로 확인 가능하다. UP_SEQ=1인 102건의 데이터를 모두 한 번에 처리했다. 위 SQL을 실행하면 102건 중의 한 건의 데이터에 업데이트가 발생한다. 이해의 편의를 위해 UP_ERR_ID의 값을 한글로 설정했다.(다국어 및 표준화를 위해서 메시지 테이블과 데이터를 설정한 후 해당 메시지ID를 사용하는 것이 좋다.) 위 SQL을 실행한 후에 COMMIT을 하지 않는다. 데이터 체크 SQL을 모두 완료하고 M_SN에 정상 데이터를 밀어 넣은 후에 COMMIT을 해야 한다.
(2) 업로드 데이터내에 중복 확인
두 번째, 업로드하려는 데이터내에 중복을 확인해 처리하는 SQL은 다음과 같다.
[SQL-4] 시리얼번호가 중복되는가?
UPDATE M_SN_UP T1
SET T1.UP_ERR_ID = '중복SN업로드'
WHERE T1.UP_SEQ = 1
AND T1.UP_ERR_ID IS NULL
AND EXISTS(
SELECT *
FROM M_SN_UP A
WHERE A.UP_SEQ = 1
AND A.UP_ERR_ID IS NULL
AND A.SN = T1.SN
AND A.ROW_NO != T1.ROW_NO);
위 SQL을 실행하면 두 건이 업데이트된다. ROW_NO 100, 101번이 같이 SN이기 때문이다. 이때, 4번, 9번 라인과 같이 UP_ERR_ID가 NULL인 데이터만 대상으로 해야 한다. 이미 이전 과정에서 에러로 처리된 데이터를 다시 점검할 필요가 없기 때문이다.
(3) 시리얼번호 자릿수가 맞는가?
[SQL-5] 시리얼번호가 번호 자릿수 점검
UPDATE M_SN_UP T1
SET T1.UP_ERR_ID = 'SN길이오류'
WHERE T1.UP_SEQ = 1
AND T1.UP_ERR_ID IS NULL
AND (
(T1.ITM_TP = 'ELEC' AND LENGTH(T1.SN) != 16)
OR
(T1.ITM_TP = 'PC' AND LENGTH(T1.SN) != 17)
);
아이템유형별로 사용하는 SN길이를 이용해 에러 점검을 한다. 위 SQL로 업데이트되는 데이터는 없다. 업로드 하려는 데이터의 SN 길이는 모두 문제가 없는 것이다.
(4) 생산일자 포맷이 맞는가?
[SQL-6] 생산일자 포맷이 맞는가?
UPDATE M_SN_UP T1
SET T1.UP_ERR_ID = '날짜형식이 맞지 않습니다.'
WHERE T1.UP_SEQ = 1
AND T1.UP_ERR_ID IS NULL
AND NOT EXISTS(
SELECT *
FROM C_BAS_YMD A
WHERE A.BAS_YMD = T1.PRD_YMD);
‘이어지는 이야기 .03’에서 만들었던 기준일자(C_BAS_YMD) 테이블을 사용하면 일자 유효성을 쉽게 체크할 수 있다.
(5) 존재하는 아이템인가?
아이템 테이블을 이용해 존재하는 아이템인지 확인하면 된다.
[SQL-7] 존재하는 아이템인가?
UPDATE M_SN_UP T1
SET T1.UP_ERR_ID = '아이템ID가 맞지 않습니다.'
WHERE T1.UP_SEQ = 1
AND T1.UP_ERR_ID IS NULL
AND NOT EXISTS(
SELECT *
FROM M_ITM A
WHERE A.ITM_ID = T1.ITM_ID);
(6) 아이템유형이 맞는가?
마찬가지로 아이템 테이블을 이용한다. 아이템ID는 갖지만 아이템유형이 다른 경우를 찾아내면 된다. NOT EXISTS가 아니라 EXISTS인 점에 유의해야 한다. 업로드한 데이터에 ITM_TP가 NULL인 데이터가 있으므로 NVL로 치환해서 비교하도록 한다.
[SQL-8] 존재하는 아이템 유형인가?
UPDATE M_SN_UP T1
SET T1.UP_ERR_ID = '아이템유형이 맞지 않습니다.'
WHERE T1.UP_SEQ = 1
AND T1.UP_ERR_ID IS NULL
AND EXISTS(
SELECT *
FROM M_ITM A
WHERE A.ITM_ID = T1.ITM_ID
AND A.ITM_TP != NVL(T1.ITM_TP,'-'));
모든 에러 점검을 맞쳤다. 102건의 데이터를 루프를 돌면서 한 건씩 에러 점검하지 않고 한 번에 모두 처리했다. 아래 SQL로 처리 결과를 알 수 있다.
[SQL-9] 처리결과 조회
SELECT T1.UP_ERR_ID, COUNT(*)
FROM M_SN_UP T1
WHERE T1.UP_SEQ = 1
GROUP BY T1.UP_ERR_ID
ORDER BY T1.UP_ERR_ID;
위 SQL을 실행하면, 에러가 없는 SQL이 총 69건이 나온다. 업무 규칙에 따라, 에러가 한 건이라도 있으면 업로드 자체를 금지할 수도 있고, 에러는 제외하고 업로드 할 수도 있다. 여기서는 에러는 제외하고 M_SN 테이블에 밀어 넣도록 하자. 아래와 같다.
[SQL-10] M_SN에 INSERT 및 COMMIT
INSERT INTO M_SN(SN ,PRD_YMD ,ITM_ID ,ITM_TP)
SELECT T1.SN ,T1.PRD_YMD ,T1.ITM_ID ,T1.ITM_TP
FROM M_SN_UP T1
WHERE T1.UP_SEQ = 1
AND T1.UP_ERR_ID IS NULL;
COMMIT;
여기서 살펴본 방법은 여러 건을 한 번에 처리하기 때문에, 루프 방식으로 한 건씩 실행하는 것보다 틀림없이 성능이 좋다고 장담한다. (물론 처리하려는 건수가 매우 적다면 이 같은 방법이 큰 이득은 없다.)
[SQL-1] 고객의 주문 건수 조회.(주문 일자는 전체일 수도 있다.)
SELECT COUNT(*) ORD_CNT
FROM T_ORD_JOIN T1
WHERE T1.CUS_ID LIKE :v_CUS_ID||'%'
AND T1.ORD_YMD LIKE :v_ORD_YMD||'%';
위 SQL에서는 CUS_ID와 ORD_YMD에 모두 LIKE 조건을 사용했다. 그러므로 인덱스 설계에 고민하게 된다. 업무를 가만히 생각해 보면, ‘고객이 접속해서 자신의 주문 건수를 조회’하는 것이다. 그러므로 고객ID(CUS_ID)는 빈 값이 절대 들어 올 수 없다. 아래와 같이 CUS_ID에는 같다(=) 조건을 사용해야 한다.
[SQL-2] 고객의 주문 건수 조회. (주문 일자는 전체일 수도 있다.) – 같다(=) 조건 사용
SELECT COUNT(*) ORD_CNT
FROM T_ORD_JOIN T1
WHERE T1.CUS_ID = :v_CUS_ID
AND T1.ORD_YMD LIKE :v_ORD_YMD||'%';
위 SQL은 CUS_ID+ORD_YMD 순서의 인덱스를 만들면 된다. 인덱스 설계에 고민이 덜하다. 부디 습관적으로 LIKE 조건을 사용하는 일은 없기 바란다.
‘LIKE 사용은 최대한 자제하자!’ 이것은 필자의 개인적인 의견이다. 인덱스를 효율적으로 설계해 SQL의 성능을 높일 수 있기 때문이다.
LIKE 사용으로 발생하는 문제점을 하나 더 살펴보자. 이번 설명을 위해서 M_SN(시리얼번호)이라는 새로운 테이블을 만들 것이다. M_SN 테이블은 아이템유형(ITM_TP)가 PC, ELEC 인 아이템의 시리얼번호를 관리한다. 이 테이블을 통해 LIKE 사용에 주의할 점을 알아볼 것이다.
M_SN 테이블은 ‘SQL BOOSTER’를 처음 작성할 때 이미 생각해서 설계했던 테이블이다. (그때는 SQL BOOSTER라는 이름이 탄생하기 전이다.) 하지만 해당 테이블을 사용한 활용 예제들을 충분히 담기가 쉽지 않아 결국 생략하게 되었다. 다행히도 이어지는 이야기를 통해 소개할 수 있게 되었다. 새로 만들 테이블은 아래와 같은 구조다.
그림 1
아래 스크립트로 M_SN 테이블을 생성하도록 하자.
[SQL-3] M_SN 테이블 만들기
CREATE TABLE M_SN
(SN VARCHAR2(40) NOT NULL
,PRD_YMD VARCHAR2(8) NULL
,SHP_YMD VARCHAR2(8) NULL
,ITM_ID VARCHAR2(40) NOT NULL
,ITM_TP VARCHAR2(40) NOT NULL);
ALTER TABLE M_SN
ADD CONSTRAINT PK_M_SN PRIMARY KEY(SN);
아래 스크립트를 이용해 M_SN 테이블에 데이터를 생성한다.
[SQL-4] M_SN 데이터 만들기
INSERT INTO M_SN (SN ,PRD_YMD ,SHP_YMD ,ITM_ID ,ITM_TP)
SELECT CASE WHEN T1.ITM_TP = 'ELEC' THEN 'E' ELSE 'P' END||LPAD(T3.RNO,3,'0')
||LPAD(T2.T_NO,4,T3.SN_ADD)
||LPAD(ROW_NUMBER() OVER(PARTITION BY T1.ITM_TP ORDER BY T2.BAS_YMD, T1.ITM_ID, T3.RNO),7,'0')
||SN_ADD
||CASE WHEN T1.ITM_TP != 'ELEC' THEN TO_CHAR(T2.YMD_NO) ELSE '' END SN
,T2.BAS_YMD PRD_YMD
,TO_CHAR(TO_DATE(T2.BAS_YMD,'YYYYMMDD')
+ MOD(TO_NUMBER(REGEXP_REPLACE(T1.ITM_ID,'([^[:digit:]])','')),8),'YYYYMMDD') SHP_YMD
,T1.ITM_ID
,T1.ITM_TP
FROM M_ITM T1
,(
SELECT A.BAS_YMD
,MOD(ROW_NUMBER() OVER(ORDER BY A.BAS_YMD ASC),4) YMD_NO
,ROW_NUMBER() OVER(ORDER BY TO_NUMBER(SUBSTR(REVERSE(A.BAS_YMD),1,5))) T_NO
FROM C_BAS_YMD A
WHERE A.BAS_YMD >= '20190101'
AND A.BAS_YMD <= '20200120'
) T2,
(
SELECT ROWNUM RNO
,CHR(MOD(ROWNUM, 8)+65) SN_ADD
FROM DUAL CONNECT BY ROWNUM <= 100
) T3
WHERE T1.ITM_TP IN ('ELEC','PC')
AND MOD(TO_NUMBER(REGEXP_REPLACE(T1.ITM_ID,'([^[:digit:]])','')),4) <= T2.YMD_NO
;
COMMIT;
위 SQL은 카테시안-조인을 이용해 총 721,500개의 시리얼 번호를 만들어낸다. 카테시안-조인을 활용해 테스트 데이터를 만드는 과정은 SQL BOOSTER에 설명되어 있다. 위 SQL에서는 REGEXP_REPLACE라는 정규식 함수를 사용하고 있다. REGEXP_REPLACE를 이용해 숫자가 아닌 데이터([^[:digit:]])는 빈 값으로 치환하고 있다.
오라클은 REGEXP_REPLACE 외에도 다양한 정규식 함수를 제공한다. 정희락님의 ‘불친절한 SQL 프로그래밍’에 설명이 되어 있으니 한 번 찾아보기 바란다. 이러한 정규식 함수는 개발자에게도 유용하지만, 데이터 클린징이나 이행을 담당해야 하는 사람에게도 매우 유용하다.
시리얼번호가 존재하는지 확인하는 SQL을 만들어보자. 아래와 같다.
[SQL-5] SN 조회 - 16자리 시리얼번호와 아이템유형을 입력 받는다.
SELECT T1.*
FROM M_SN T1
WHERE T1.SN = 'E018CC400000418C'
AND T1.ITM_TP = 'ELEC';
문제없이 시리얼번호가 조회된다. 이번에는 PC제품을 조회해보자. 아래와 같다.
[SQL-6] SN 조회 - 16자리 시리얼번호와 아이템유형을 입력 받는다.(PC제품 조회)
SELECT *
FROM M_SN T1
WHERE T1.SN = 'P080AA400000680A'
AND T1.ITM_TP = 'PC';
위 SQL을 실행하면 조회되는 데이터가 없다. 위 SQL에서 사용한 변수('P080AA400000680A')는 16자리다. 앞에서 M_SN에 데이터를 만들 때 의도적으로 ITM_TP(아이템유형)가 ELEC은 16자리, PC 는 17자리로 구성했다. 그러므로 PC아이템을 같다(=) 조건으로 조회하려면 17자리 SN을 입력해야 한다. 만약에 ‘SN 조회 화면’에서 17자리를 모두 입력 받을 수 있다면 위 SQL은 문제가 없을 것이다. 여기서는 PC 제품도 ‘SN 조회 화면’에서 16자리까지만 입력할 수 있다고 가정한다.
무조건 16자리만 입력된다고 가정했을 때, M_SN에서 PC 제품을 조회하기 위해 아래와 같은 SQL을 고민해 볼 수 있을 것이다.
[SQL-7] SN 조회 - SUBSTR 사용
SELECT *
FROM M_SN T1
WHERE SUBSTR(T1.SN,1,16) = 'P080AA400000680A'
AND T1.ITM_TP = 'PC';
위 SQL은 최악이다.SQL BOOSTER의 독자라면 절대 위와 같이 SQL을 개발하는 일은 없기 바란다. SUBSTR 대신에 아래와 같이 LIKE를 사용하면 16자리를 이용해 SN을 조회할 수 있다.
[SQL-8] SN 조회 - LIKE 사용
SELECT *
FROM M_SN T1
WHERE T1.SN LIKE 'P080AA400000680A'||'%'
AND T1.ITM_TP = 'PC';
위 SQL을 사용하면, ELEC과 PC 아이템 유형의 SN 조회에 모두 사용할 수 있다. 성능에 있어서 같다(=) 조건보다 아주 약간의 손해가 있지만, 신경 쓰지 않아도 될 정도다.
과연, 여기서 안심하고 개발을 마무리하면 될 것인가? 이 글의 제목은 “잘 되던 LIKE도 다시 보자”다. 프로그램 오류로 시리얼 번호가 16자리가 입력되지 않고, 3자리만 입력되었다고 생각해보자. 아래와 같이 말이다.
[SQL-9] SN 존재 확인 SQL LIKE – 프로그램 오류로 3자리만 입력됨
SELECT *
FROM M_SN T1
WHERE T1.SN LIKE 'P08'||'%'
AND T1.ITM_TP = 'PC';
위 SQL은 P08로 시작하는 모든 시리얼번호를 조회하게 된다. 성능에 문제가 있을 수 밖에 없다. 성능 부하를 고려해 ROWNUM = 1 조건을 추가하는 것을 고려해 볼 수 있다. 아래와 같이 말이다.
[SQL-10] SN 존재 확인 SQL LIKE, ROWNUM – 프로그램 오류로 3자리만 입력됨
SELECT *
FROM M_SN T1
WHERE T1.SN LIKE 'P08'||'%'
AND T1.ITM_TP = 'PC'
AND ROWNUM = 1;
[SQL-10]은 한 건의 데이터만 조회되므로 성능의 문제는 없겠지만, 원하는 결과가 아니다. 성능보다는 데이터의 정확성이 먼저다.
길이가 짧은 변수로 성능 저하가 발생하지 않게 하기 위해 아래와 같은 SQL을 고려할 수 있다.
[SQL-11] SN 존재 확인 SQL LIKE, LENGTH – 프로그램 오류로 3자리만 입력됨
SELECT *
FROM M_SN T1
WHERE T1.SN LIKE 'P08'||'%'
AND T1.ITM_TP = 'PC'
AND LENGTH('P08') = 16; -- 입력된 변수가 16자리일때만 SQL이 처리되도록 한다.
위와 같이 WHERE 절에 입력된 변수의 길이를 체크하는 조건을 추가하는 것이다. 이처럼 SQL을 작성하면 입력된 변수의 길이가 맞지 않으면 데이터 자체를 뒤질 일도 없다.
물론, 프로그램적으로 길이가 짧은 변수가 입력되는 일이 없도록 해주는 것이 기본이다. 하지만 개발하다 보면 어디선가 실수가 나게 된다. 프로그램과 함께 SQL에 위의 조건을 추가해 혹시 모를 오류를 한 번 더 막을 수 있다.
시리얼번호가 모두 16자리로 관리되고 있다면 이와 같은 고민을 할 필요조차 없다. 필자의 경험으로는, 업무는 계속 변하고, 만들어 놓은 규칙도 계속 변한다. 변하는 부분을 모델에 모두 반영하고 개발한 SQL에 제대로 제때 반영하는 작업은 만만하지 않다. 이러한 과정에서 실수가 발생하고, 이로 인해 성능 문제를 일으키는 SQL들이 만들어진다. 여기서 살펴본 예제를 통해 LIKE를 사용하기 전에 한 번 더 생각해 보기 바란다. 성능에 이슈가 없을지 말이다.
T_ORD_JOIN 테이블에서 고객별 마지막 주문만 가져오는 SQL을 작성해보자. 먼저 아래와 같은 인덱스를 만들도록 한다.
X_T_ORD_JOIN_TEST 인덱스 생성
CREATE INDEX X_T_ORD_JOIN_TEST ON T_ORD_JOIN(CUS_ID,ORD_SEQ);
인덱스를 만든 후에는, 아래와 같은 SQL로 고객별 마지막 주문을 가져올 수 있다.
[SQL-1] 고객별 마지막 주문 가져오기 – WHERE절 서브쿼리
SELECT *
FROM T_ORD_JOIN T1
WHERE T1.ORD_SEQ = (SELECT MAX(A.ORD_SEQ)
FROM T_ORD_JOIN A
WHERE A.CUS_ID = T1.CUS_ID);
WHERE절의 서브쿼리를 사용한 간단한 방법이다. FROM절의 T_ORD_JOIN을 순차적으로 읽어가면서 WHERE 절의 서브쿼리에 T1.CUS_ID를 공급하고, 해당 T1.CUS_ID의 마지막 ORD_SEQ를 찾아서 FROM절의 ORD_SEQ와 같으면 조회하는 방법이다. 이와 같은 SQL 작성 방법은 좋지 않다.
실행계획에서는 서브쿼리를 먼저 처리하고 있다. 실행계획의 3~5번 단계에서 X_T_ORD_JOIN_TEST 인덱스를 모두 읽어서 HASH GROUP BY 한 후에, 2번 단계에서 NL 조인 하는 것을 보면 알 수 있다. 오라클의 옵티마이져가 재치(?)를 발휘해 서브쿼리를 인라인-뷰처러 만들어 처리한 것이다. 실행계획의 총 Buffers 수치는 11,867이다. 기억하기 바란다.
고객별 마지막 주문을 구하는 또 다른 방법은 ROW_NUMBER 분석함수를 사용하는 것이다. 아래와 같다.
[SQL-2] 고객별 마지막 주문 가져오기 – ROW_NUMBER
SELECT T0.*
FROM (
SELECT T1.*
,ROW_NUMBER() OVER(PARTITION BY T1.CUS_ID ORDER BY T1.ORD_SEQ DESC) RNK
FROM T_ORD_JOIN T1
) T0
WHERE T0.RNK = 1;
분석함수의 OVER절과 PARTITION BY만 이해하고 있다면 어렵지 않게 사용할 수 있는 방법이다. (분석함수는 SQL BOOSTER 본서에서 자세하게 다루고 있다.) T_ORD_JOIN 테이블을 한 번만 접근하면 되므로 WHERE절 서브쿼리 방식보다 성능이 좋을 것 같지만, 오히려 좋지 못하다. T_ORD_JOIN 전체를 모두 읽어야 하기 때문이다. 실행계획을 확인해 보면 총 26,488의 Buffers가 발생한다.
지금 상황에서 필자가 추천하는 방법은 다음과 같다.
[SQL-3] 고객별 마지막 주문 가져오기 – M_CUS를 사용
SELECT T2.*
FROM (
SELECT (SELECT MAX(B.ORD_SEQ) FROM T_ORD_JOIN B WHERE B.CUS_ID = A.CUS_ID) ORD_SEQ
FROM M_CUS A
) T1
,T_ORD_JOIN T2
WHERE T1.ORD_SEQ = T2.ORD_SEQ
인라인-뷰에서(3~4 라인) M_CUS 테이블과 스칼라 서브쿼리로 고객별 마지막 ORD_SEQ를 구한 후에 T_ORD_JOIN과 조인 처리하는 방법이다. 실행계획을 살펴보면 다음과 같다.
필자는 여기서 이 방법을 추천했다. 하지만, 항상 이 방법이 좋은 것은 아니다. SQL BOOSTER에서 사용하고 있는 예제는 고객 수가 많지 않다. 그렇기 때문에 M_CUS를 이용해 마지막 주문을 가져오는 방법이 효율적이었던 것이다. 만약에 고객 수가 매우 많다면 이와 같은 방법은 성능이 더 나쁠 수 있다. 언제나 실행계획을 보고, 상황에 따라 좋은 방법을 찾아서 쓸 수 있어야 한다.
(2) 고객별 월별 마지막 주문 데이터 가져오기.
이번에는 고객+월별(ORD_YM=SUBSTR(T1.ORD_YMD,1,6)) 마지막 주문을 가져오는 SQL을 살펴보자.
테스트를 위해 인덱스를 먼저 만들도록 한다.
X_T_ORD_JOIN_TEST_2 인덱스 생성
CREATE INDEX X_T_ORD_JOIN_TEST_2 ON T_ORD_JOIN(CUS_ID,ORD_YMD,ORD_SEQ);
여기서 가장 안 좋은 방법은 WHERE절의 서브쿼리를 사용하는 경우다. 아래와 같이 말이다. (아래 SQL은 필자 노트북에서 실행 결과가 나오지 않았다. 독자 여러분도 마찬가지일 수 있다.)
[SQL-4] 고객별 월별 마지막 주문 가져오기 – WHERE 절 서브쿼리
SELECT *
FROM T_ORD_JOIN T1
WHERE T1.ORD_SEQ = (SELECT MAX(A.ORD_SEQ)
FROM T_ORD_JOIN A
WHERE A.CUS_ID = T1.CUS_ID
AND A.ORD_YMD LIKE SUBSTR(T1.ORD_YMD,1,6)||'%'
)
ORDER BY T1.CUS_ID, T1.ORD_YMD DESC;
위 SQL은 필자 환경에서 매우 오랜 시간이 지나도 결과가 나오지 않았다. EXPLAIN PLAN FOR를 이용해 실행계획만 확인해보니 무지막지한 방법으로 SQL이 실행되고 있었다. 실행계획은 다음과 같다.
[실행계획-4] 고객별 월별 마지막 주문 가져오기 – WHERE 절 서브쿼리
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1792 | 136K| | 584K (95)| 01:56:58 |
|* 1 | FILTER | | | | | | |
| 2 | SORT GROUP BY | | 1792 | 136K| | 584K (95)| 01:56:58 |
|* 3 | HASH JOIN | | 5774M| 419G| 110M| 350K (92)| 01:10:04 |
| 4 | INDEX FAST FULL SCAN| X_T_ORD_JOIN_TEST_2 | 3224K| 73M| | 4237 (1)| 00:00:51 |
| 5 | TABLE ACCESS FULL | T_ORD_JOIN | 3224K| 166M| | 7257 (1)| 00:01:28 |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("T1"."ORD_SEQ"=MAX("A"."ORD_SEQ"))
3 - access("A"."CUS_ID"="T1"."CUS_ID")
filter("A"."ORD_YMD" LIKE SUBSTR("T1"."ORD_YMD",1,6)||'%')
실행계획의 Predicate Information을 보면 3번 단계에서 (A.CUS_ID = T1.CUS_ID) 조건으로 해시 조인이 되고 있다. 두 개의 T_ORD_JOIN 간에 같은 CUS_ID끼리 모두 조인이 되고 있는 것이다. 마치 카테시안-조인처럼 데이터가 연결되고 있는 것이다. 이번에는 오라클이 재치를 발휘하지 못했다.
위 SQL은 아래와 같이 인라인-뷰와 조인 조합으로 변경할 수 있다.
[SQL-5] 고객별 월별 마지막 주문 가져오기 – 인라인-뷰
SELECT T1.*
FROM (
SELECT A.CUS_ID
,SUBSTR(A.ORD_YMD,1,6) ORD_YM
,MAX(A.ORD_SEQ) MAX_ORD_SEQ
FROM T_ORD_JOIN A
GROUP BY A.CUS_ID
,SUBSTR(A.ORD_YMD,1,6)
) T0
,T_ORD_JOIN T1
WHERE T1.ORD_SEQ = T0.MAX_ORD_SEQ
ORDER BY T1.CUS_ID, T1.ORD_YMD DESC;
인라인-뷰에서 고객별 월별 마지막 ORD_SEQ를 구해서 T_ORD_JOIN과 조인하는 방법이다. 실행계획은 다음과 같다.
인라인-뷰를 사용한 방법의 총 Buffers는 42,125다. 인라인-뷰 결과와 T_ORD_JOINN을 해시-조인 처리하고 있다. 필자 생각에는 인라인-뷰 결과와 T_ORD_JOIN을 NL 조인 하는 것이 성능이 더 좋을 것이라 생각된다. 인라인-뷰의 결과가 천 건밖에 안되기 때문이다. (직접 힌트를 사용해 NL 조인으로 테스트해보기 바란다.)
고객별 월별 마지막 주문을 구하기 위해서도 ROW_NUMBER 분석함수를 사용할 수 있다. 아래와 같이 PARTITION BY에 SUBSTR(T1.ORD_YMD,1,6)을 추가하면 된다.
[SQL-5] 고객별 월별 마지막 주문 가져오기 – ROW_NUMBER
SELECT T0.*
FROM (
SELECT T1.*
,ROW_NUMBER() OVER(PARTITION BY T1.CUS_ID, SUBSTR(T1.ORD_YMD,1,6)
ORDER BY T1.ORD_SEQ DESC) RNK
FROM T_ORD_JOIN T1
) T0
WHERE T0.RNK = 1
위 SQL의 실행계획을 확인해 보면, 총 26,490의 Buffers가 발생한다.
‘(1) 고객별 마지막 주문 데이터 가져오기’에서 성능이 가장 좋았던 방법은 M_CUS를 이용한 방법이었다. 하지만 여기서는 주문년월까지 포함되어야 하므로 M_CUS를 이용한 방법을 쉽게 사용할 수 없다. 하지만 일자(C_BAS_YMD) 테이블을 이용하면 이를 해결 할 수 있다. 아래와 같다.
[SQL-6] 고객별 월별 마지막 주문 가져오기 – M_CUS와 C_BAS_YMD
SELECT T2.*
FROM (
SELECT (SELECT MAX(B.ORD_SEQ)
FROM T_ORD_JOIN B
WHERE B.CUS_ID = A.CUS_ID AND B.ORD_YMD LIKE D.BAS_YM||'%') ORD_SEQ
FROM M_CUS A
,(SELECT DISTINCT C.BAS_YM FROM C_BAS_YMD C WHERE C.BAS_YMD LIKE '2017%') D
) T1
,T_ORD_JOIN T2
WHERE T1.ORD_SEQ = T2.ORD_SEQ
ORDER BY T2.CUS_ID, T2.ORD_YMD DESC;
SQL의 7번 라인을 보면 C_BAS_YMD에서 2017년에 해당하는 월(BAS_YM) 데이터 12건을 가져온 후에 M_CUS와 카테시안-조인하고 있다. 이와 같이 하면, M_CUS의 고객별로 201701부터 201712까지의 데이터가 만들어진다. (현재 T_ORD_JOIN에는 2017년 데이터만 있기 때문에 고객별 2017년 월별 데이터만 만들면 된다.) M_CUS의 고객별 월별 데이터를 이용해 마지막 ORD_SEQ를 구한 후에 다시 T_ORD_JOIN과 조인하는 방법이다. 실행계획은 다음과 같다.
총 Buffers가 21,226으로 줄어들었다. 일자 테이블까지 가져와서 카테시안-조인 처리하긴 했지만, 지금까지 SQL 중에는 IO 성능이 제일 좋다.
(3) 고객별 일자별 마지막 주문 데이터 가져오기.
이번에는 고객+일자별 마지막 주문을 가져오는 SQL을 살펴보자. WHERE 절 서브쿼리는 보나마나 성능이 좋지 못할 것이다.
고객별 일자별 마지막 주문을 조회하기 위해 아래와 같이 인라인-뷰를 사용해보자.
[SQL-7] 고객별 일자별 마지막 주문 가져오기 – 인라인-뷰
SELECT T1.*
FROM (
SELECT A.CUS_ID
,A.ORD_YMD
,MAX(A.ORD_SEQ) MAX_ORD_SEQ
FROM T_ORD_JOIN A
GROUP BY A.CUS_ID
,A.ORD_YMD
) T0
,T_ORD_JOIN T1
WHERE T1.ORD_SEQ = T0.MAX_ORD_SEQ
ORDER BY T1.CUS_ID, T1.ORD_YMD DESC;
이번에는 인라인-뷰의 결과와 T_ORD_JOIN이 NL 조인으로 처리되고 있다. (‘(2)’에서 인라인-뷰를 사용한 방법은 해시-조인으로 처리되었었다.) NL 조인이면서 총 Buffers는 23,452다.
그렇다면, (1)번에서 추천한 방법인 M_CUS를 사용한 방법은 어떨까? 고객+일자별 마지막 주문을 가져와야 하므로 그 방법은 좋지 못할 것으로 예상된다. 스칼라-서브쿼리가 반복적으로 많이 실행되기 때문이다. 실제 테스트 해보도록 하자.
[SQL-8] 고객별 일자별 마지막 주문 가져오기 – M_CUS와 C_BAS_YMD
SELECT T2.*
FROM (
SELECT (SELECT MAX(B.ORD_SEQ) FROM T_ORD_JOIN B
WHERE B.CUS_ID = A.CUS_ID AND B.ORD_YMD = D.BAS_YMD) ORD_SEQ
FROM M_CUS A
,(SELECT C.BAS_YMD FROM C_BAS_YMD C WHERE C.BAS_YMD LIKE '2017%') D
) T1
,T_ORD_JOIN T2
WHERE T1.ORD_SEQ = T2.ORD_SEQ
ORDER BY T2.CUS_ID, T2.ORD_YMD DESC;
그렇다면 인라인-뷰를 사용한 방법을 좀 더 향상시킬 수는 없을까? 다음과 같이 KEEP 분석함수와 ROWID를 사용하는 방법이 있다.
[SQL-9] 고객별 일자별 마지막 주문 가져오기 – 인라인-뷰와 KEEP
SELECT T1.*
FROM (
SELECT A.CUS_ID
,A.ORD_YMD
,MAX(A.ROWID) KEEP(DENSE_RANK FIRST ORDER BY A.ORD_SEQ DESC) RID
FROM T_ORD_JOIN A
GROUP BY A.CUS_ID
,A.ORD_YMD
) T0
,T_ORD_JOIN T1
WHERE T1.ROWID = T0.RID
KEEP을 이용해 고객, 일별 마지막 주문SEQ의 ROWID를 가져와서, ROWID로 T_ORD_JOIN에 바로 접근하는 방법이다. PK_T_ORD_JOIN 인덱스를 경유하지 않아 성능에 이득이 있다. 실행계획은 다음과 같다.
UNION과 UNION ALL은 두 데이터 집합을 상하로 결합시킨다. 아마도 이를 모르는 개발자는 없을 것이다. 반면에 MINUS 구문은 사용해 본적이 없거나 처음 접하는 개발자도 있을 것이다. MINUS는 상하의 두 데이터 집합간의 차집합을 구한다. 이 MINUS 연산은 도통 쓸데가 없다. 일반적인 조회 화면에서 MINUS가 포함된 SQL이 사용되는 경우는 거의 없기 때문이다. 하지만 MINUS는 데이터 검증 작업을 할 때 매우 유용하다. 필자는 MINUS 구문을 성능 개선 작업할 때 많이 사용한다.
SQL BOOSTER 에 이어지는 이야기들입니다.~! SQL BOOSTER 를 보신 분들께 좀 더 도움을 드리고자 추가로 작성한 내용입니다.
[SQL-1] MINUS 예제
SELECT *
FROM (
SELECT 'A' COL1, 1 COL2 FROM DUAL
UNION ALL
SELECT 'B' COL1, 3 COL2 FROM DUAL) T1
MINUS
SELECT *
FROM (SELECT 'A' COL1, 1 COL2 FROM DUAL
UNION ALL
SELECT 'B' COL1, 2 COL2 FROM DUAL
) T2
MINUS를 기준으로 위쪽 SQL(T1)을 기준 집합이라고 하자. 그리고 아래쪽 SQL(T2)을 참조 집합이라고 하자. [SQL-1]을 실행하면 기준 집합에는 있지만 참조 집합에는 없는 데이터만 조회할 수 있다. 아래와 같은 결과가 나온다.
[결과-1] MINUS 예제
COL1 COL2
======== =========
B 3
COL1이 B면서 COL2가 3인 데이터는 T1에는 있지만, T2에는 없다. 그러므로 해당 건만 결과에 나오게 된다. 이처럼 MINUS는 특정 컬럼이 아니라 SELECT절에 표시된 모든 컬럼을 비교한다.
성능 개선을 위해 SQL을 변경해야만 할 때가 있다. 힌트나 인덱스로는 성능 개선이 어려운 경우가 있기 때문이다. 간단한 변경은 문제 없지만, 약간 복잡한 변경을 하게 되면 변경 이전과 결과가 같은지 검증을 꼭 해야 한다. 이 때 MINUS를 사용 할 수 있다.
아래 SQL을 보자.(SQL BOOSTER에서 ROLLUP을 대신할 방법으로 소개했던 SQL이다.)
[SQL-2] UNION ALL을 이용한 중간합계
SELECT TO_CHAR(T1.ORD_DT,'YYYYMM') ORD_YM ,T1.CUS_ID
,SUM(T1.ORD_AMT) ORD_AMT
FROM T_ORD T1
WHERE T1.CUS_ID IN ('CUS_0001','CUS_0002')
AND T1.ORD_DT >= TO_DATE('20170301','YYYYMMDD')
AND T1.ORD_DT < TO_DATE('20170501','YYYYMMDD')
GROUP BY TO_CHAR(T1.ORD_DT,'YYYYMM') ,T1.CUS_ID
UNION ALL
SELECT TO_CHAR(T1.ORD_DT,'YYYYMM') ORD_YM ,'Total' CUS_ID
,SUM(T1.ORD_AMT) ORD_AMT
FROM T_ORD T1
WHERE T1.CUS_ID IN ('CUS_0001','CUS_0002')
AND T1.ORD_DT >= TO_DATE('20170301','YYYYMMDD')
AND T1.ORD_DT < TO_DATE('20170501','YYYYMMDD')
GROUP BY TO_CHAR(T1.ORD_DT,'YYYYMM')
UNION ALL
SELECT 'Total' ORD_YM ,'Total' CUS_ID
,SUM(T1.ORD_AMT) ORD_AMT
FROM T_ORD T1
WHERE T1.CUS_ID IN ('CUS_0001','CUS_0002')
AND T1.ORD_DT >= TO_DATE('20170301','YYYYMMDD')
AND T1.ORD_DT < TO_DATE('20170501','YYYYMMDD')
위와 같은 SQL은 ROLLUP으로 변경하는 것이 성능에 유리할 수 있다. 실행계획까지 확인해 ROLLUP이 더 좋다면 SQL을 변경하도록 한다. 이때, 성능보다 중요한 건 데이터의 정확성이다. 성능을 얻고 정확성을 잃을 수는 없다. 그러므로 반드시 변경한 SQL의 데이터가 맞는지 확인해야 한다. 다음과 같이 MINUS를 사용해 확인할 수 있다. MINUS를 기준으로 위쪽은 ROLLUP, 아래쪽은 UNION ALL이다.
[SQL-3] MINUS를 이용한 SQL 검증
--ROLLUP을 이용한 SQL
SELECT CASE WHEN GROUPING(TO_CHAR(T1.ORD_DT,'YYYYMM')) = 1 THEN 'Total'
ELSE TO_CHAR(T1.ORD_DT,'YYYYMM') END ORD_YM
,CASE WHEN GROUPING(T1.CUS_ID) = 1 THEN 'Total' ELSE T1.CUS_ID END CUS_ID
,SUM(T1.ORD_AMT) ORD_AMT
,COUNT(*) OVER() TTL_CNT
FROM T_ORD T1
WHERE T1.CUS_ID IN ('CUS_0001','CUS_0002')
AND T1.ORD_DT >= TO_DATE('20170301','YYYYMMDD')
AND T1.ORD_DT < TO_DATE('20170501','YYYYMMDD')
GROUP BY ROLLUP(TO_CHAR(T1.ORD_DT,'YYYYMM') ,T1.CUS_ID)
MINUS
-- 기존 SQL(UNION ALL)
SELECT A.*, COUNT(*) OVER() TTL_CNT
FROM (
SELECT TO_CHAR(T1.ORD_DT,'YYYYMM') ORD_YM ,T1.CUS_ID
,SUM(T1.ORD_AMT) ORD_AMT
FROM T_ORD T1
WHERE T1.CUS_ID IN ('CUS_0001','CUS_0002')
AND T1.ORD_DT >= TO_DATE('20170301','YYYYMMDD')
AND T1.ORD_DT < TO_DATE('20170501','YYYYMMDD')
GROUP BY TO_CHAR(T1.ORD_DT,'YYYYMM') ,T1.CUS_ID
UNION ALL
SELECT TO_CHAR(T1.ORD_DT,'YYYYMM') ORD_YM ,'Total' CUS_ID
,SUM(T1.ORD_AMT) ORD_AMT
FROM T_ORD T1
WHERE T1.CUS_ID IN ('CUS_0001','CUS_0002')
AND T1.ORD_DT >= TO_DATE('20170301','YYYYMMDD')
AND T1.ORD_DT < TO_DATE('20170501','YYYYMMDD')
GROUP BY TO_CHAR(T1.ORD_DT,'YYYYMM')
UNION ALL
SELECT 'Total' ORD_YM ,'Total' CUS_ID
,SUM(T1.ORD_AMT) ORD_AMT
FROM T_ORD T1
WHERE T1.CUS_ID IN ('CUS_0001','CUS_0002')
AND T1.ORD_DT >= TO_DATE('20170301','YYYYMMDD')
AND T1.ORD_DT < TO_DATE('20170501','YYYYMMDD')
) A;
위 SQL을 실행하면 조회되는 데이터가 없다. MINUS를 기준으로 위쪽 SQL 결과와 아래쪽 SQL의 결과가 완전히 같기 때문이다. 6번 라인과 14번 라인을 보면 두 데이터 집합에 COUNT(*) OVER()를 추가한 것을 볼 수 있다. 데이터 건수까지 완전히 같은지 확인하기 위해서다.
이처럼 MINUS 연산은 데이터를 검증하기 위해서 많이 사용한다. 이행한 데이터가 문제 없는지, 변경한 SQL이 문제 없는지 확인하기 위해서 말이다. 그러므로 “쓸데 없는 MINUS”는 아니다. 나름 유용하게 쓸 데가 있다. 잘 기억하고 사용할 수 있기 바란다.
SQL을 성능 개선 할 때, 가장 손쉬운 방법은 인덱스를 추가하는 것이다. 물론 인덱스로 성능이 개선될 수 있다면 말이다. 하지만, 그런 식으로 인덱스를 만들다 보면 데이터베이스에는 인덱스가 테이블보다 더 많은 용량을 차지하기 시작한다. SQL BOOSTER 본서 183페이지, ‘6.4.3 너무 많은 인덱스의 위험성’에서 설명했던 내용이다.
손쉬운 인덱스 추가보다는, 주어진 인덱스에서 성능을 개선할 방법을 찾는 것이 SQL 성능 개선의 첫 단계다. 인덱스는 그 다음 단계다.
SQL BOOSTER 에 이어지는 이야기들입니다.~! SQL BOOSTER 를 보신 분들께 좀 더 도움을 드리고자 추가로 작성한 내용입니다.
[SQL-1] T_ORD_JOIN을 집계 조회
SELECT /*+ GATHER_PLAN_STATISTICS */
T1.ORD_ST
,SUM(T1.ORD_QTY * T1.UNT_PRC) ORD_AMT
FROM T_ORD_JOIN T1
WHERE T1.ORD_YMD BETWEEN '20170101' AND '20170930'
AND T1.ITM_ID = 'ITM020'
AND T1.CUS_ID = 'CUS_0004'
GROUP BY T1.ORD_ST;
특정 고객의, 특정 아이템에 대해 1월1일부터 9월30일까지의 판매금액을 주문상태(ORD_ST)별로 집계하고 있다. 실행계획은 다음과 같다.
[실행계획-1] T_ORD_JOIN을 집계 조회
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers | OMem |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1 |00:00:00.11 | 257 | |
| 1 | HASH GROUP BY | | 1 | 1 |00:00:00.11 | 257 | 934K|
|* 2 | TABLE ACCESS BY INDEX ROWID| T_ORD_JOIN | 1 | 2000 |00:00:00.01 | 257 | |
|* 3 | INDEX RANGE SCAN | X_T_ORD_JOIN_2 | 1 | 19000 |00:00:00.03 | 80 | |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("T1"."ITM_ID"='ITM020')
3 - access("T1"."CUS_ID"='CUS_0004' AND "T1"."ORD_YMD">='20170101' AND "T1"."ORD_YMD"<='20170931')
원하는 결과를 얻기 위해 257번의 논리IO가 발생했다. 성능이 나쁜 SQL은 아니다. 하지만, 더 성능을 개선할 수 없을까 고민해보자. 성능을 개선하려면 비효율을 먼저 찾아야 한다. 비효율은 실행계획에 빨간색으로 표시해 놓았다. 실행계획의 3번 단계에서 19,000건을 찾았고, 2번 단계에서 ITM_ID 조건이 필터 되면서 17,000건이 버려졌다. T_ORD_JOIN에 19,000번 접근했지만, 그 중에 17,000번이 불필요한 접근인 것이다. 만약에 CUS_ID, ORD_YMD의 인덱스에 ITM_ID 컬럼도 있었다면 테이블에 접근한 후 버려지는 비효율이 발생하지 않았을 것이다. 그리고 CUS_ID, ITM_ID, ORD_YMD, ORD_ST 순서의 인덱스가 있었다면, 테이블을 접근하는 비효율 자체가 없었을 것이다. 하지만, 현재 가진 인덱스에서 해결해야 한다면 어떻게 해야 할까? 우선 T_ORD_JOIN에 어떤 인덱스가 있는지 살펴보자.
노란색으로 표시된 부분은 해당 인덱스에서 사용할 수 있는 컬럼이다. [SQL-1]을 처리하기에 가장 좋은 인덱스는 X_T_ORD_JOIN_2와 X_T_ORD_JOIN_4다. 위의 실행계획에서도 X_T_ORD_JOIN_2 인덱스를 사용했다.
인덱스의 리프 블록에는 ROWID가 있다는 사실을 기억하고 있는가? 이 점을 항상 기억하기 바란다. 하나의 테이블에 종속된 인덱스들은 ROWID라는 공통 분모를 가지고 있다. 이 점을 이용하면 가지고 있는 인덱스 안에서 어느 정도의 성능 개선이 가능하다. 바로 아래와 같이 SQL을 바꿔보는 것이다.
[SQL-2] T_ORD_JOIN을 집계 조회 – 성능 개선
SELECT /*+ NO_MERGE(T0) LEADING(T0 T3) USE_NL(T3) */
T3.ORD_ST
,SUM(T3.ORD_QTY * T3.UNT_PRC) ORD_AMT
FROM (
SELECT /*+ LEADING(T2) USE_HASH(T1) INDEX(T1 X_T_ORD_JOIN_2) INDEX(T2 X_T_ORD_JOIN_4) */
T1.ROWID RID
FROM T_ORD_JOIN T1
,T_ORD_JOIN T2
WHERE T1.ORD_YMD BETWEEN '20170101' AND '20170930'
AND T1.CUS_ID = 'CUS_0004'
AND T2.ORD_YMD BETWEEN '20170101' AND '20170930'
AND T2.ITM_ID = 'ITM020'
AND T1.ROWID = TRIM(T2.ROWID)
) T0
,T_ORD_JOIN T3
WHERE T3.ROWID = T0.RID
GROUP BY T3.ORD_ST
SQL이 굉장히 길고 복잡해졌다. 주의 깊게 볼 부분을 빨간색과 노란색으로 표시해 놓았다. T_ORD_JOIN 테이블이 세 번이나 출현하고 있다. SQL 성능을 위해서는 같은 테이블을 불필요하게 반복 사용해서는 안 된다. 필자가 줄 곧 해온 이야기며, 일반적으로 맞는 말이다. 하지만 인덱스의 구조를 정확히 알면, 위와 같이 SQL을 작성해 성능을 개선할 수 있다.
위 SQL은 X_T_ORD_JOIN_2 인덱스로 CUS_ID와 ORD_YMD 조건이 맞는 ROWID를 찾아내고, X_T_ORD_JOIN_4 인덱스로 ITM_ID와 ORD_YMD 조건에 맞는 ROWID를 찾아내 해시 조인 처리하고 있다. 해시 조인으로 얻은 두 인덱스간에 공통된 ROWID를 T_ORD_JOIN(T3)에 공급해 최종 결과를 얻어내는 방법이다. 실행계획을 살펴보자. 논리IO가 257에서 188로 줄어들었다.
[실행계획-2] T_ORD_JOIN을 집계 조회 – 성능 개선
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts |A-Rows | A-Time | Buffers | OMem |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1 |00:00:00.02 | 188 | |
| 1 | HASH GROUP BY | | 1 | 1 |00:00:00.02 | 188 | 934K|
| 2 | NESTED LOOPS | | 1 | 2000 |00:00:00.02 | 188 | |
| 3 | VIEW | | 1 | 2000 |00:00:00.02 | 170 | |
|* 4 | HASH JOIN | | 1 | 2000 |00:00:00.02 | 170 | 1814K|
|* 5 | INDEX RANGE SCAN | X_T_ORD_JOIN_4 | 1 | 23000 |00:00:00.01 | 90 | |
|* 6 | INDEX RANGE SCAN | X_T_ORD_JOIN_2 | 1 | 19000 |00:00:00.01 | 80 | |
| 7 | TABLE ACCESS BY USER ROWID| T_ORD_JOIN | 2000 | 2000 |00:00:00.01 | 18 | |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T1".ROWID=CHARTOROWID(TRIM(ROWIDTOCHAR("T2".ROWID))))
5 - access("T2"."ITM_ID"='ITM020' AND "T2"."ORD_YMD">='20170101' AND "T2"."ORD_YMD"<='20170931')
6 - access("T1"."CUS_ID"='CUS_0004' AND "T1"."ORD_YMD">='20170101' AND "T1"."ORD_YMD"<='20170931')
6 - access("T2"."ITM_ID"='ITM002' AND "T2"."ORD_YMD">='20170101' AND "T2"."ORD_YMD"<='20170228')
논리IO가 개선되었지만, 해시조인으로 인해 메모리 사용은 늘어날 수 밖에 없다. 보통은 IO 개선이 SQL 성능에 많은 도움이 되기 때문에 이와 같은 방법을 사용해야 할 때가 있다.
이와 같이 SQL을 많이 변경해야 한다면 좋은 방법이라고 말하기는 어렵다. SQL이 길어지고, 조건이 늘어났으며 힌트도 많이 사용되었다. 사실, NO_MERGE 정도의 간단한 힌트만 사용해 원하는 결과를 얻고 싶었지만, 그럴 수 없어 힌트를 많이 사용하게 되었다. SQL의 13번 라인에서 T2.ROWID를 TRIM 처리하기도 했다. 실행계획이 원하는 대로 만들어지지 않아 강제 처리한 것이다.
오라클에는 INDEX_JOIN이나 INDEX_COMBINE 힌트가 있다. [SQL-2]처럼 복잡하게 SQL을 변경하지 않아도 해당 힌트를 사용할 수 있다. 하지만, 힌트가 먹지 않는 경우가 있다. 또는 작동하던 힌트가 어느 순간부터 작동하지 않을 수도 있다. 그리고, 힌트를 사용할 수 없는 DBMS도 있다. 그러므로 이와 같이 SQL을 변경할 수 있다면, 힌트가 작동하지 않아도, 힌트가 없어도 성능 개선을 할 수 있다.
복합인덱스를 이용해 데이터를 찾을 때, 선두 컬럼이 같다(=) 조건으로 사용되어야 뒤쪽 컬럼도 데이터 검색에 효율적으로 사용될 수 있다. (이 내용은 SQL BOOSTER의 ‘6.3.1절. 복합 인덱스 – 컬럼 선정과 순서#1’에 설명되어 있다.) 바꿔 말하면, 복합 인덱스의 선두 컬럼에는 범위 조건이, 뒤쪽 컬럼에는 같다(=) 조건이 사용된 SQL이 있다면, 선두 컬럼의 범위 조건을 같다(=) 조건으로 변경해 성능을 향상 시킬 수도 있다. 여기서는 일자 테이블을 이용해 날짜에 대한 범위 조건을 같다(=) 조건으로 변경해 볼 예정이다.
이와 같은 내용은 이미 많은 사람들이 알고 있는 기술이다. 정확히 기억나지 않지만, 어느 책에선가 본 기억도 있으며, 구글에서 MySQL 성능 관련 자료를 찾다가도 발견한 적이 있다. 직접 실습해보고 싶은 독자들을 위해 ‘이어지는 이야기’에서 다루어 보기로 했다. SQL BOOSTER는 실제 연습 해볼 수 있게 구성되어 있는 장점을 가지고 있다.
특정 고객들의 고객별 2017년 1월 주문 금액을 조회하는SQL을 만들어 보자. 여기서는 T_ORD_BIG 테이블을 사용한다.
T_ORD_BIG의 인덱스를 확인해보자. ‘이어지는 이야기 .02’에서 인덱스 리스트를 조회하는 SQL은 이미 살펴보았다. T_ORD_BIG에는 아래와 같이 인덱스가 구성되어 있다.
많은 인덱스가 있지만, 여기서는 ORD_YMD, CUS_ID 순서로 구성된 X_T_ORD_BIG_3 인덱스만 사용할 수 있다고 가정한다. 주어진 인덱스에서 최대의 성능이 나오도록 튜닝 연습을 할 필요가 있다. 인덱스로 모든 것을 해결하기 보다는 주어진 상황에서 먼저 해결책을 찾는 것이 좋다. (인덱스로 계속 덧칠한 시스템을 볼 때면 너무 가슴이 아프다.)
특정 고객들의 고객별 주문 금액을 조회하는 SQL은 아래와 같다. X_T_ORD_BIG_3 인덱스를 사용하도록 힌트를 주었다.
[SQL-1] 특정 고객들의 고객별 2017년 1월 주문 금액 조회하기
SELECT /*+ INDEX(T2 X_T_ORD_BIG_3) */
T1.CUS_ID
,SUM(T2.ORD_AMT) ORD_AMT
FROM M_CUS T1
,T_ORD_BIG T2
WHERE T2.CUS_ID = T1.CUS_ID
AND T1.CUS_GD = 'A'
AND T1.RGN_ID = 'A'
AND T2.ORD_YMD LIKE '201701%'
GROUP BY T1.CUS_ID;
실행계획은 아래와 같다.
[실행계획-1] 특정 고객들의 고객별 2017년 1월 주문 금액 조회하기
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 18 |00:00:07.48 | 736K|
| 1 | SORT GROUP BY NOSORT | | 1 | 18 |00:00:07.48 | 736K|
| 2 | NESTED LOOPS | | 1 | 540K|00:01:24.55 | 736K|
| 3 | NESTED LOOPS | | 1 | 540K|00:01:21.99 | 196K|
|* 4 | TABLE ACCESS BY INDEX ROWID| M_CUS | 1 | 20 |00:00:00.01 | 3 |
| 5 | INDEX FULL SCAN | PK_M_CUS | 1 | 90 |00:00:00.01 | 1 |
|* 6 | INDEX RANGE SCAN | X_T_ORD_BIG_3 | 20 | 540K|00:00:54.67 | 196K|
| 7 | TABLE ACCESS BY INDEX ROWID | T_ORD_BIG | 540K| 540K|00:00:02.38 | 540K|
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter(("T1"."RGN_ID"='A' AND "T1"."CUS_GD"='A'))
6 - access("T2"."ORD_YMD" LIKE '201701%' AND "T2"."CUS_ID"="T1"."CUS_ID")
filter(("T2"."ORD_YMD" LIKE '201701%' AND "T2"."CUS_ID"="T1"."CUS_ID"))
실행계획의 총 Buffers는 736K다. 실행계획의 6번 항목을 보면 X_T_ORD_BIG_3을 이용해 NL 조인을 처리하고 있다. X_T_ORD_BIG_3 인덱스는 ORD_YMD, CUS_ID 순서로 구성되어 있다. 조인 처리시에 ORD_YMD에는 범위(LIKE) 조건이, CUS_ID에는 같다(=) 조건이 사용된다. 선두 컬럼이 범위 조건으로 사용되어 CUS_ID 조건은 조인에서 좋은 역할을 할 수 없게 된다.
사실 위 SQL은 CUS_ID, ORD_YMD 순서로 구성된 X_T_ORD_BIG_4 인덱스를 사용하는 것이 성능이 더 좋다. 여기서는 성능 개선 연습을 위해 무조건 X_T_ORD_BIG_3 인덱스만 사용하기로 한다.
X_T_ORD_BIG_3 인덱스를 효율적으로 사용하려면 ORD_YMD가 같다(=) 조건으로 사용되어야 한다. 이를 위해 기준일자 테이블을 활용할 수 있다. 아래 SQL을 보자.
[SQL-2] 특정 고객들의 고객별 2017년 1월 주문 금액 조회하기 – 기준일자 테이블 사용
SELECT /*+ NO_MERGE(T1) INDEX(T2 X_T_ORD_BIG_3) */
T1.CUS_ID
,SUM(T2.ORD_AMT) ORD_AMT
FROM (
SELECT A.CUS_ID ,B.BAS_YMD
FROM M_CUS A
,C_BAS_YMD B
WHERE A.CUS_GD = 'A'
AND A.RGN_ID = 'A'
AND B.BAS_YM = '201701'
) T1
,T_ORD_BIG T2
WHERE T2.CUS_ID = T1.CUS_ID
AND T2.ORD_YMD = T1.BAS_YMD
GROUP BY T1.CUS_ID;
[SQL-2]는 M_CUS와 C_BAS_YMD를 카테시안-조인 한 후에 T_ORD_BIG과 조인 처리하고 있다. 조회할 고객별로 1월 한 달의 일자 데이터를 만든 후에 T_ORD_BIG에 ORD_YMD와 CUS_ID를 같다(=) 조건으로 공급해주는 것이다. 이로 인해 ORD_YMD가 선두 컬럼인 X_T_ORD_BIG_3 인덱스를 효율적으로 사용해 조인을 처리할 수 있게 된다. 실행계획을 살펴보자.
Buffers가 736K에서 544K로 줄어들었다. 조인은 한 번 늘어났지만, 성능은 오히려 좋아졌다. X_T_ORD_JOIN_3 인덱스의 선두 컬럼인 ORD_YMD를 같다(=) 조건으로 처리했기 때문이다.
항상 그래왔듯이, 실행계획을 보고 실제로 성능이 개선되었는지, 자신이 원하는 방향으로 SQL이 처리되었는지 확인하는 것이 중요하다. 데이터에 따라 성능이 더 나빠질 수도 있으며, 실행계획이 다르게 풀릴 수도 있다. 여기서 사용한 예제는 필자가 몇 번의 수고 끝에, 기준일자 테이블을 사용하면 성능이 좋은 경우를 억지로 찾아낸 것이다. 중요한 건 이러한 방법이 있다는 것을 기억하고, 상황에 따라 응용해 보고, 실행계획까지 확인하는 것이다.
[SQL-1] 주문이 두 건 이상인 고객의 주문 로우 데이터 보여주기
SELECT /*+ GATHER_PLAN_STATISTICS */
T1.CUS_ID ,T1.ORD_YMD ,T1.ORD_QTY
FROM (
SELECT A.CUS_ID
FROM T_ORD_JOIN A
GROUP BY A.CUS_ID
HAVING COUNT(*)>=2
) T0
,T_ORD_JOIN T1
WHERE T1.CUS_ID = T0.CUS_ID
ORDER BY T1.CUS_ID ,T1.ORD_YMD;
인라인-뷰에서 주문이 두 건 이상인 고객을 찾아서 T_ORD_JOIN과 다시 조인해서 조회하는 SQL이다. 위 SQL의 실행계획은 다음과 같다.
[실행계획-1] 주문이 두 건 이상인 고객의 주문 데이터 보여주기
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1100 |00:00:02.98 | 47234 |
| 1 | SORT ORDER BY | | 1 | 1100 |00:00:02.98 | 47234 |
| 2 | NESTED LOOPS | | 1 | 3224K|00:00:02.75 | 47228 |
| 3 | NESTED LOOPS | | 1 | 3224K|00:00:00.96 | 18187 |
| 4 | VIEW | | 1 | 90 |00:00:00.32 | 9025 |
|* 5 | FILTER | | 1 | 90 |00:00:00.32 | 9025 |
| 6 | HASH GROUP BY | | 1 | 90 |00:00:00.31 | 9025 |
| 7 | INDEX FAST FULL SCAN | X_T_ORD_JOIN_1 | 1 | 3224K|00:00:00.23 | 9025 |
|* 8 | INDEX RANGE SCAN | X_T_ORD_JOIN_1 | 90 | 3224K|00:00:00.34 | 9162 |
| 9 | TABLE ACCESS BY INDEX ROWID| T_ORD_JOIN | 3224K| 3224K|00:00:00.96 | 29041 |
-------------------------------------------------------------------------------------------------
실행계획을 보면, 7번 단계에서 X_T_ORD_JOIN_1 인덱스를 FAST FULL SCAN해서 두 건 이상인 고객을 찾아 낸 후, 다시 T_ORD_JOIN과 조인을 처리하고 있다. SQL을 작성한 대로 실행계획이 만들어졌다. 총 Buffers를 보면 47,234다. X_T_ORD_JOIN_1 인덱스를 모두 읽어서 처리했기 때문이다.
사실 T_ORD_JOIN 테이블의 데이터는 해당 테스트에 적당하게 구성되어 있지 않다. 모든 고객의 주문이 두 건 이상이기 때문이다. 그냥 조회해도 결과는 같다.
어쨌든 현업의 요구 사항 자체가 이와 같다면, 데이터 구성에 상관 없이 위와 같은 SQL을 작성해야만 한다. 조건에 맞는 모든 데이터를 조회해야 한다면, 위의 SQL도 나쁘다고 할 수는 없다. 하지만 우선 조회가 가능한 몇 건을 조회해야 한다면 어떨까? 우선 몇 건 조회만을 위해서는 너무 많은 IO가 발생했다.
아래와 같이 SQL을 변경해보면 어떨까?
[SQL-2] 주문이 두 건 이상인 고객의 주문 로우 데이터 보여주기 – EXISTS 사용
SELECT /*+ GATHER_PLAN_STATISTICS */
T1.CUS_ID ,T1.ORD_YMD ,T1.ORD_QTY
FROM T_ORD_JOIN T1
WHERE EXISTS(
SELECT /*+ USE_NL(A) */
*
FROM T_ORD_JOIN A
WHERE A.CUS_ID = T1.CUS_ID
AND A.ROWID != T1.ROWID)
ORDER BY T1.CUS_ID ,T1.ORD_YMD;
T_ORD_JOIN을 CUS_ID와 ORD_YMD 순서로 읽어가면서, CUS_ID는 같으면서 ROWID가 다른 데이터가 존재할 때만 조회를 하고 있다. 실행계획을 제어하기 위해 EXISTS 서브쿼리에 USE_NL 힌트도 사용했다. [SQL-1]의 결과와 정렬 순서는 약간 차이가 있을 수 있지만, 우선 몇 건만 조회하기에는 성능이 최적인 SQL이다. 실행계획을 살펴보자.
[실행계획-2] 주문이 두 건 이상인 고객의 주문 로우 데이터 보여주기 – EXISTS 사용
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1100 |00:00:00.01 | 94 |
| 1 | NESTED LOOPS SEMI | | 1 | 1100 |00:00:00.01 | 94 |
| 2 | TABLE ACCESS BY INDEX ROWID| T_ORD_JOIN | 1 | 1100 |00:00:00.01 | 60 |
| 3 | INDEX FULL SCAN | X_T_ORD_JOIN_2 | 1 | 1100 |00:00:00.01 | 28 |
|* 4 | INDEX RANGE SCAN | X_T_ORD_JOIN_1 | 1100 | 1100 |00:00:00.01 | 34 |
------------------------------------------------------------------------------------------------
총 Buffers가 94로 개선되었다. SQL-1은 총 Buffers가 47,234였다.
SQL을 변경해서 성능을 개선했다. 물론, 우선 몇 건만 보여주는 경우이면서 적절한 인덱스가 있을 때만 사용할 수 있는 방법이다.
현업의 요구 사항은 무궁무진하다. 요구 사항에 따라 SQL을 무작정 작성할 것이 아니라, 성능을 향상 할 방법을 고민해 보고 다양한 방법으로 SQL을 작성해보기 바란다. SQL은 언제나 변화무쌍하다.
기준일자 테이블을 사용하는 사이트가 가끔 있다. 기준일자는 업무에 직접적으로 관련은 없지만 일자 정보만 모아서 저장해 놓은 테이블이다. 필자가 처음 맡았던 시스템에는 이미 기준일자 테이블을 누군가 설계 해놓았다. 덕분에 기준일자 테이블을 사용할 수 있었고 기준일자 테이블을 더욱 확장해 매우 유용하게 사용했다.
아래와 같은 형태로 기준일자 테이블을 생성할 예정이다.
[그림 1]
기준일자(BAS_YMD) 컬럼은 문자열로 ‘YYYYMMDD’ 형태의 일자 데이터를 저장한다. 기준일(BAS_DT)은 DATE형으로 일자를 저장한다. 논리명에 문자열은 ‘일자’, DATE형은 ‘일’을 쓰기로 한다. 기준요일은 기준일에 대한 요일 값이다. 기준일자순번은 기준일자 순서에 따라 1부터 시작하는 연속된 값을 부여한다. 이 값을 이용해 일자 연산을 대신할 수 있다. 기준주는 기준일자가 속한 주를 뜻한다. 기준월, 기준분기, 기준반기, 기준년도도 마찬가지다.
아래 스크립트를 이용해 기준일자 테이블을 생성할 수 있다.
[SQL-1] 기준일자 테이블 생성
CREATE TABLE C_BAS_YMD
( BAS_YMD VARCHAR2(8) NOT NULL
,BAS_DT DATE NULL
,BAS_DY VARCHAR2(40) NULL
,BAS_YMD_SEQ NUMBER(9) NULL
,BAS_YW VARCHAR(6) NULL
,BAS_YM VARCHAR(6) NULL
,BAS_YQ VARCHAR(5) NULL
,BAS_YH VARCHAR(5) NULL
,BAS_YY VARCHAR(6) NULL
);
ALTER TABLE C_BAS_YMD
ADD CONSTRAINT PK_C_BAS_YMD PRIMARY KEY(BAS_YMD);
CREATE UNIQUE INDEX UX_C_BAS_YMD_01 ON C_BAS_YMD(BAS_DT);
CREATE UNIQUE INDEX UX_C_BAS_YMD_02 ON C_BAS_YMD(BAS_YMD_SEQ);
CREATE INDEX X_C_BAS_YMD_01 ON C_BAS_YMD(BAS_YM,BAS_YMD);
기준일자 테이블을 만든 후에는 다음 SQL을 이용해 기준일자 데이터를 생성할 수 있다. 2016년1월1일부터 2030년12월31일까지의 기준일자를 생성한다.
[SQL-2] 기준일자 데이터 생성
INSERT INTO C_BAS_YMD
(BAS_YMD,BAS_DT,BAS_YMD_SEQ)
SELECT TO_CHAR(TO_DATE('20160101','YYYYMMDD') + ROWNUM,'YYYYMMDD') BAS_YMD
,TO_DATE('20160101','YYYYMMDD') + ROWNUM BAS_DT
,ROWNUM BAS_YMD_SEQ
FROM DUAL T1
CONNECT BY TO_DATE('20160101','YYYYMMDD') + ROWNUM <= TO_DATE('20301231','YYYYMMDD');
COMMIT;
C_BAS_YMD에는 BAS_YMD(기준일자), BAS_DT(기준일), BAS_YMD_SEQ(기준일자순번) 값만 입력되어 있다. 나머지 값들은 UPDATE로 채워 넣을 예정이다. 아래 SQL은 기준주(BAS_YW)를 제외한 나머지 값들을 채워 넣는 SQL이다. 기준주는 로직이 조금 복잡해 별도 처리한다.
[SQL-3] 기준월, 기준분기, 기준반기, 기준년도, 기준요일 UPDATE
UPDATE C_BAS_YMD T1
SET T1.BAS_YM = SUBSTR(T1.BAS_YMD,1,6)
,T1.BAS_YQ = SUBSTR(T1.BAS_YMD,1,4)||CEIL(TO_NUMBER(SUBSTR(T1.BAS_YMD,5,2)) / 3)
,T1.BAS_YH = SUBSTR(T1.BAS_YMD,1,4)||CEIL(TO_NUMBER(SUBSTR(T1.BAS_YMD,5,2)) / 6)
,T1.BAS_YY = SUBSTR(T1.BAS_YMD,1,4)
,T1.BAS_DY = CASE TO_CHAR(T1.BAS_DT,'D')
WHEN '1' THEN 'SUN'
WHEN '2' THEN 'MON'
WHEN '3' THEN 'TUE'
WHEN '4' THEN 'WED'
WHEN '5' THEN 'THU'
WHEN '6' THEN 'FRI'
WHEN '7' THEN 'SAT' END
;
COMMIT;
[SQL-3]은 설명 없이도 이해하는데 아무 어려움이 없을 것이다. 아래 [SQL-4]는 기준주를 UPDATE하는 SQL이다. SQL을 먼저 살펴보자.
[SQL-4] 기준주 UPDATE
UPDATE C_BAS_YMD T1
SET T1.BAS_YW =
CASE
WHEN TO_CHAR(T1.BAS_DT,'MMDD') <= '0107' AND TO_CHAR(T1.BAS_DT,'IW') >= 50 THEN
TO_CHAR(T1.BAS_DT,'YYYY')-1||TO_CHAR(T1.BAS_DT,'IW')
WHEN TO_CHAR(T1.BAS_DT,'MMDD') >= '1224' AND TO_CHAR(T1.BAS_DT,'IW') = 01 THEN
TO_CHAR(T1.BAS_DT,'YYYY')+1||TO_CHAR(T1.BAS_DT,'IW')
ELSE TO_CHAR(T1.BAS_DT,'YYYY')||TO_CHAR(T1.BAS_DT,'IW')
END;
C_BAS_YMD의 기준일(BAS_DT) 값을 이용해 기준주를 구하고 있다. TO_CHAR(T1.BAS_DT,’IW’)를 실행하면, 해당 일의 주 값을 알 수 있다.
첫 번째 WHEN 부분부터 살펴보자. 기준일이 1월7일보다 작으면서, 기준일의 주 값이 50보다 크면, 기준일의 년도가 아니라, 전년도의 년도를 가져와 주 값과 결합한다. 아래와 같은 경우다. 2016년1월1일이 2016-53주일리는 없다. 그러므로 전년도인 2015-53으로 만들어야 한다. (비교에서 년도는 제외하고 년월만 사용한다.)
[SQL-5] 첫 번째 WHEN, 기준일이 1월7일보다 작으면서 주 값이 50 이상인 경우
SELECT TO_CHAR(TO_DATE('20160101'),'IW') FROM DUAL; -- 결과 값은 53주가 나온다.
[SQL-4]의 두 번째 WHEN 부분을 살펴보자. 기준일이 12월24일보다 크면서, 주 값이 1주인 경우다. 이 경우에는 기준일의 년도의 다음 년도를 가져와 주를 결합한다. 아래와 같은 경우다. (비교에서 년도는 제외하고 년월만 사용한다.)
[SQL-5] 두 번째 WHEN, 기준일이 12월24일보다 크면서 주 값이 1인 경우.
SELECT TO_CHAR(TO_DATE('20191231'),'IW') FROM DUAL; -- 결과 값은 1주가 나온다.
첫 번쨰, 두 번째 WHEN은 년초의 몇 일이 작년 주에 속하거나, 년말의 몇 일이 내년 주에 속하는 경우를 예외처리한 것이다. 세 번째 WHEN은 나머지 경우로 기준일의 년도를 그대로 사용하면 되는 경우다.
위에서 첫 번째 두 번째 WHEN절에서 1월7일, 12월24일을 사용했는데 꼭 그 날이 아니어도 된다. 대략 년초, 년말이면 된다.
데이터가 제대로 입력되었는지는 아래 SQL로 확인해볼 수 있다.
[SQL-6] 주 데이터 확인
SELECT T1.BAS_YW
,COUNT(*)
,MIN(T1.BAS_DT) FRS_DT
,MAX(T1.BAS_DT) LST_DT
,MAX(T1.BAS_DY) KEEP(DENSE_RANK FIRST ORDER BY T1.BAS_DT ASC)
,MAX(T1.BAS_DY) KEEP(DENSE_RANK LAST ORDER BY T1.BAS_DT ASC)
FROM C_BAS_YMD T1
GROUP BY T1.BAS_YW;
기준일자 테이블에 첫 주와 마지막 주를 제외하고 모두 7일씩 제대로 데이터가 만들어진 것을 확인할 수 있다. [SQL-6]에는 KEEP이 사용되었다. KEEP의 사용법은 정희락님의 ‘불친절한 SQL 프로그래밍’을 참고해보길 추천한다.
이제 기준일자(C_BAS_YMD) 테이블에 기본적인 데이터를 모두 채워 넣었다. 이 테이블은 개발 곳곳에서 유용하게 사용할 수 있다. 사용자 화면에 아래 그림과 같이 주를 고르는 콤보 박스를 만들어야 한다고 가정해보자. 현재일 기준으로 최근 30주 데이터가 나와야 한다.
[그림 2]
개발자 입장에서 보면, 이와 같은 컨트롤을 만드는 일이 어렵지는 않다. 더욱이 개발 환경이 갈수록 좋아져서 많은 것들이 모듈화가 잘 되어 있다. 어쨌든, 위와 같은 컨트롤에 값을 채워 넣는 작업을 SQL로도 쉽게 해결 할 수 있다. 현재일 기준으로 최근 30주 데이터를 구하기 위해서는 아래 SQL을 사용할 수 있다.
[SQL-7] 현재일 기준으로 최근 30주 가져오기.(현재 2019년12월10일이라고 가정)
SELECT T1.BAS_YW
FROM (
SELECT T1.BAS_YW||'('||MIN(T1.BAS_YMD)||'~'||MAX(T1.BAS_YMD)||')' BAS_YW
FROM C_BAS_YMD T1
WHERE T1.BAS_YMD <= '20191210'
GROUP BY T1.BAS_YW
ORDER BY T1.BAS_YW DESC
) T1
WHERE ROWNUM <= 30;
위 SQL의 실행 결과는 아래와 같다.
결과-7] 현재일 기준으로 최근 30주 가져오기.(현재 2019년12월10일이라고 가정)
BAS_YW
=========================
201950(20191209~20191210)
201949(20191202~20191208)
201948(20191125~20191201)
201947(20191118~20191124)
…
값을 잘 보면 잘못된 부분이 있다. 2019년50주가 2019년12월10일까지 밖에 없다. 2019년50주는 12월15일까지 나와야 한다. 현재일을 기준으로 데이터를 조회했기 때문이다. 주말인 12월15일까지 포함되서 조회하기 위해서는 아래와 같이 서브쿼리를 추가해야 한다.
[SQL-8] 현재일 기준으로 최근 30주 가져오기 – 주말을 포함
SELECT T1.BAS_YW
FROM (
SELECT T1.BAS_YW||'('||MIN(T1.BAS_YMD)||'~'||MAX(T1.BAS_YMD)||')' BAS_YW
FROM C_BAS_YMD T1
WHERE T1.BAS_YW <= (SELECT A.BAS_YW FROM C_BAS_YMD A WHERE A.BAS_YMD = '20191210')
GROUP BY T1.BAS_YW
ORDER BY T1.BAS_YW DESC
) T1
WHERE ROWNUM <= 30;
기준일자 테이블을 사용해 최근 30주를 손쉽게 구했다. 위 SQL의 경우 성능을 고려해 BAS_YW 컬럼에 인덱스를 고민해 볼 수 있다. C_BAS_YMD 테이블에는 필요하다면 얼마든지 인덱스를 만들어도 된다. 데이터가 한 번 입력되고 나면 추가로 입력되거나 변경될 일은 없기 때문이다. (물론 기준일자의 마지막쯤에 다다르면, 다음 일자들에 대한 생성은 필요하다.)
기준일자 테이블을 사용하면, 실적이 없는 일자의 실적도 손쉽게 구할 수 있다. 아래 SQL은 2017년3월의 특정 고객 주문을 조회하는 SQL이다. 주문이 없는 날도 0으로 표현해야 한다.
[SQL-9] 특정 고객의 일별 주문 조회
SELECT T1.BAS_YMD
,COUNT(T2.ORD_SEQ) ORD_CNT
FROM C_BAS_YMD T1
,T_ORD_JOIN T2
WHERE T1.BAS_YM = '201703'
AND T1.BAS_YMD = T2.ORD_YMD(+)
AND T2.CUS_ID(+) = 'CUS_0010'
GROUP BY T1.BAS_YMD
ORDER BY T1.BAS_YMD;
위 SQL을 실행하면 CUS_0010 고객의 주문이 없는 일도 모두 0으로 집계해서 조회가 가능하다. 물론 일자 테이블이 없어도 얼마든지 위의 결과를 만들어 낼 수 있다. 아래 SQL을 참고하자.
[SQL-10] 특정 고객의 일별 주문 조회 – CONNECT BY 사용
SELECT T1.BAS_YMD
,COUNT(T2.ORD_SEQ) ORD_CNT
FROM (
SELECT TO_DATE('20170301','YYYYMMDD') + (ROWNUM - 1) BAS_YMD
FROM DUAL A
CONNECT BY TO_DATE('20170301','YYYYMMDD') + (ROWNUM - 1) <= TO_DATE('20170331','YYYYMMDD')
) T1
,T_ORD_JOIN T2
WHERE T1.BAS_YMD = T2.ORD_YMD(+)
AND T2.CUS_ID(+) = 'CUS_0010'
GROUP BY T1.BAS_YMD
ORDER BY T1.BAS_YMD;
[SQL-9]와 [SQL-10]의 결과는 동일하다. 하지만 [SQL-9]가 좀 더 깔끔하다는 것을 모두 동의하리라 생각한다.
오라클은 그나마 CONNECT BY가 있기 때문에 기준일자 테이블이 없어도 [SQL-10]과 같은 패턴을 사용할 수 있다. 하지만 MySQL과 MS-SQL은 CONNECT BY가 없기 때문에, 기준일자 테이블이 없으면 더 복잡한 방법을 사용해야 한다. (MS-SQL은 WITH절을 중첩 사용해 CONNECT BY를 구현한다. 사용해 본 사람들은 이러한 방법이 구현도 복잡하며, 성능이 안 좋은 경우도 많다는 것을 알 것이다.)
겨울을 대비해 보일러를 들여 놓는 것처럼, 편리한 개발을 위해 기준일자 테이블 하나 들여 놓기 바란다.
끝으로, 숨겨진 퀴즈가 두 개 있다. 첫 번째 퀴즈, [SQL-10]에는 성능에 영향을 주는 잘 못된 부분이 하나 있다. [SQL-9]와 [SQL-10]의 실행계획을 모두 떠보고, 잘 못된 부분을 찾아 고쳐보기 바란다. 아마도 어렵지 않게 찾아 낼 수 있을 것이다. 두 번쨰 퀴즈, [SQL-9]의 IO를 좀 더 개선해 보기 바란다. CPU나 메모리 사용량이 좀 더 늘어도 상관 없다. IO를 줄이는 것이 목표다. SQL만 조금 변경해 IO를 개선해 보기 바란다. 절대 힌트는 사용하지 않아야 한다.
설명의 편의상 반말체로 작성한 점 양해바랍니다. pdf 파일도 첨부드리니 다운 받아 보셔도 됩니다.
<LISTAGG & 테이블의 인덱스 확인하기>
오늘은 정말 짧은 글을 하나 올립니다. 앞으로 이어질 글에, 인덱스를 확인해야 하는 경우들이 있기 때문에 짧지만 LISTAGG와 같이 설명하고 넘어가려고 합니다.
오라클 11g에는 LISTAGG함수가 있다. LISTAGG는 여러 로우를 하나로 만드는 유용한 기능이다. 쉽게 말에 여러 건의 데이터를 콤마로 결합해 한 건으로 보여주기 위해 사용한다. [그림 2-1]을 본다면 이해가 쉽다.
그림 2-1
현업의 요구 사항 중에는 [그림 2-1]의 우측과 같이 여러 건의 로우를 콤마를 이용해 한 건으로 보여주기를 원하는 경우가 있다. 이때, LISTAGG를 사용하면 비교적 쉽게 요구 사항을 해결할 수 있다. 하지만 많은 데이터를 LISTAGG로 처리하면 성능적인 이슈가 있을 수 있다. 로우를 모두 끌어 올려 컬럼으로 변경하는 것이기 때문에, 일반적인 데이터 조회보다 성능 부하가 있을 수 밖에 없다.
필자의 경우, 현업에서 여러 건을 콤마로 구분해 한 건으로 보여주고자 하는 요구 사항은 최대한 들어주지 못하는 쪽으로 협의해왔다. 꼭 필요한 경우라면, 건수에 제한을 두고 성능까지 검토한 후에 요구사항을 받아들였다. LISTAGG를 익히기 전에 성능적인 이슈가 있음을 알고 제한적으로 사용해야 함을 꼭 명심해주기 바란다.
C_BAS_CD 테이블을 BAS_CD_DV(기준코드구분) 별로, 기준코드(BAS_CD) 리스트를 한 컬럼으로 보여주는 SQL을 작성해보자. 아래와 같다.
[SQL-1] BAS_CD_DV별 BAS_CD 리스트를 한 컬럼으로 표현
SELECT T1.BAS_CD_DV
,LISTAGG(T1.BAS_CD,',') WITHIN GROUP(ORDER BY T1.BAS_CD) IND_COLS
FROM C_BAS_CD T1
WHERE T1.LNG_CD = 'KO'
GROUP BY T1.BAS_CD_DV;
위 SQL을 실행하면 아래와 같은 결과가 나온다.
[결과-1] BAS_CD_DV별 BAS_CD 리스트를 한 컬럼으로 표현
BAS_CD_DV BAS_CD_LST
========= ==========
CUS_GD A,B
GND_TP FEMLE,MALE
ITM_TP CLOTHES,COOK,ELEC,PC
...
LISTAGG를 사용하려면 GROUP BY를 같이 사용해야 한다. SQL BOOSTER의 GROUP BY 부분을 읽었다면 전혀 어렵지 않을 것이다. SUM이나 MAX가 사용될 집계함수 부분만 LISTAGG로 대체하면 된다. LISTAGG에는 WITHIN GROUP절도 같이 사용해야 한다. 아래를 참고하기 바란다.
- LISTAGG(결합할 컬럼명, 구분자) WITHIN GROUP(ORDER BY 정렬기준)
이번에는 코드와 코드명을 결합해 코드명까지 보여주도록 LISTAGG를 변형해보자.
[SQL-2] BAS_CD_DV별 BAS_CD, BAS_CD_NM 리스트를 한 컬럼으로 표현
SELECT T1.BAS_CD_DV
,(SELECT A.BAS_CD_DV_NM FROM C_BAS_CD_DV A WHERE A.BAS_CD_DV = T1.BAS_CD_DV) BAS_CD_DV_NM
,LISTAGG('['||T1.BAS_CD||']'||T1.BAS_CD_NM,',') WITHIN GROUP(ORDER BY T1.BAS_CD) BAS_CD_LST
FROM C_BAS_CD T1
WHERE T1.LNG_CD = 'KO'
GROUP BY T1.BAS_CD_DV;
여기까지 위의 SQL 들을 직접 입력하고 실행해봤다면, LISTAGG의 사용에는 문제가 없으리라 생각된다. LISTAGG 외에도, 유사한 XMLLAG도 있으니 찾아보기 바란다. 처음에도 이야기 했듯이 성능적인 부분을 고려해 제한적으로 사용하기 바란다.
사실, LISTAGG에 대해서는 쓰고 싶지 않았다. 프로젝트 여기 저기에서, 무분별하게 LISTAGG가 사용되게 될까 걱정되기 때문이다. 그럼에도 불구하고 LISTAGG에 대해 짤막하게 다룬 이유는, 아래의 인덱스 리스트를 조회하는 SQL을 보여주기 위해서다. 필자가 자주 사용하는 SQL이다.
[SQL-3] 인덱스 리스트 조회하기
SELECT T1.INDEX_OWNER ,T1.TABLE_NAME ,T1.INDEX_NAME
,LISTAGG(T1.COLUMN_NAME,',') WITHIN GROUP(ORDER BY T1.COLUMN_POSITION) IND_COLS
FROM ALL_IND_COLUMNS T1
,ALL_INDEXES T2
WHERE T1.TABLE_NAME = 'T_ORD_BIG'
AND T1.INDEX_NAME = T2.INDEX_NAME
AND T1.TABLE_NAME = T2.TABLE_NAME
AND T1.INDEX_OWNER = T2.OWNER
GROUP BY T1.INDEX_OWNER ,T1.TABLE_NAME ,T1.INDEX_NAME
ORDER BY T1.INDEX_OWNER ,T1.TABLE_NAME ,T1.INDEX_NAME;
위 SQL을 실행하면 아래와 같이, T_ORD_BIG 테이블의 인데스 현황을 보기 좋게 조회할 수 있다.
SQL BOOSTER를 읽어주신 독자 여러분께 깊은 감사의 마음을 전합니다. 꼼꼼히 읽어주시는 분들의 고마움에 보답하고자 책에는 담지 않았지만, 책에서 구축된 데이터베이스를 사용해 추가로 익힐 수 있는 내용을 짤막하게 시리즈로 적어보려고 합니다. (SQL BOOSTER를 끝까지 읽으면 만들어지는 테이블들을 사용합니다.) 올리는 주기와 시기, 내용을 약속할 수 없는 점 먼저 이해 바랍니다. 본문의 내용은 전달 효율성을 위해 반말체를 사용하는 점 이해 부탁드립니다. 그럼, 시작하도록 하겠습니다.
하나의 테이블에서 데이터를 조회할 때, 상황에 따라 다양한 구간을 조회해야 할 때가 있다. 예를 들면 아래 SQL과 같다.
-- [SQL-1] ITM_ID에 따라 다양한 구간을 조회 – UNION ALL
SELECT T1.ITM_ID
,COUNT(*) ORD_CNT
FROM T_ORD_JOIN T1
WHERE T1.CUS_ID = 'CUS_0002'
AND T1.ITM_ID = 'ITM002' AND T1.ORD_YMD BETWEEN '20170102' AND '20170103'
GROUP BY T1.ITM_ID
UNION ALL
SELECT T1.ITM_ID
,COUNT(*) ORD_CNT
FROM T_ORD_JOIN T1
WHERE T1.CUS_ID = 'CUS_0002'
AND T1.ITM_ID = 'ITM079' AND T1.ORD_YMD BETWEEN '20170102' AND '20170115'
GROUP BY T1.ITM_ID
UNION ALL
SELECT T1.ITM_ID
,COUNT(*) ORD_CNT
FROM T_ORD_JOIN T1
WHERE T1.CUS_ID = 'CUS_0002'
AND T1.ITM_ID = 'ITM015' AND T1.ORD_YMD BETWEEN '20170102' AND '20170125'
GROUP BY T1.ITM_ID
아이템별로 팔리는 주기가 다르다고 가정했을 때 이와 같은 SQL이 나올 수 있다. 위 SQL을 실행계획을 확인해보면 아래와 같다.
[PLAN-1] ITM_ID에 따라 다양한 구간을 조회 – UNION ALL
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 |00:00:00.01 | 106 |
| 1 | UNION-ALL | | 1 | 3 |00:00:00.01 | 106 |
| 2 | SORT GROUP BY NOSORT | | 1 | 1 |00:00:00.01 | 27 |
|* 3 | TABLE ACCESS BY INDEX ROWID| T_ORD_JOIN | 1 | 1000 |00:00:00.01 | 27 |
|* 4 | INDEX RANGE SCAN | X_T_ORD_JOIN_2 | 1 | 2000 |00:00:00.01 | 11 |
| 5 | SORT GROUP BY NOSORT | | 1 | 1 |00:00:00.01 | 27 |
|* 6 | TABLE ACCESS BY INDEX ROWID| T_ORD_JOIN | 1 | 1000 |00:00:00.01 | 27 |
|* 7 | INDEX RANGE SCAN | X_T_ORD_JOIN_2 | 1 | 2000 |00:00:00.01 | 11 |
| 8 | SORT GROUP BY NOSORT | | 1 | 1 |00:00:00.01 | 52 |
|* 9 | TABLE ACCESS BY INDEX ROWID| T_ORD_JOIN | 1 | 1000 |00:00:00.01 | 52 |
|* 10 | INDEX RANGE SCAN | X_T_ORD_JOIN_2 | 1 | 4000 |00:00:00.01 | 19 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("T1"."ITM_ID"='ITM002')
4 - access("T1"."CUS_ID"='CUS_0002' AND "T1"."ORD_YMD">='20170102' AND
"T1"."ORD_YMD"<='20170103')
6 - filter("T1"."ITM_ID"='ITM079')
7 - access("T1"."CUS_ID"='CUS_0002' AND "T1"."ORD_YMD">='20170102' AND
"T1"."ORD_YMD"<='20170115')
9 - filter("T1"."ITM_ID"='ITM015')
10 - access("T1"."CUS_ID"='CUS_0002' AND "T1"."ORD_YMD">='20170102' AND
"T1"."ORD_YMD"<='20170125')
실행계획을 확인해 보면 Buffers(논리적IO)가 106이다. 그리고 같은 테이블인 T_ORD_JOIN에 세 번이나 접근하고 있다. SQL에서 T_ORD_JOIN을 3개를 UNION ALL로 묶었기 때문에 당연한 결과다.
같은 테이블의 반복 사용은 성능 저하로 이어진다. 반복 사용을 제거하기 위해 아래와 같은 SQL을 고민해 볼 수 있다.
-- [SQL-2] ITM_ID에 따라 다양한 구간을 조회 – CASE 사용
SELECT T1.ITM_ID
,COUNT(*) ORD_CNT
FROM T_ORD_JOIN T1
WHERE T1.CUS_ID = 'CUS_0002'
AND CASE WHEN T1.ITM_ID = 'ITM002' AND T1.ORD_YMD BETWEEN '20170102' AND '20170103' THEN 1
WHEN T1.ITM_ID = 'ITM079' AND T1.ORD_YMD BETWEEN '20170102' AND '20170115' THEN 1
WHEN T1.ITM_ID = 'ITM015' AND T1.ORD_YMD BETWEEN '20170102' AND '20170125' THEN 1
END = 1
GROUP BY T1.ITM_ID;
T_ORD_JOIN을 한 번만 사용해 SQL이 간단해졌다. 사실 이와 같은 SQL은 개발 편의성을 위해 작성되는 패턴이다. SQL의 성능 향상과는 아무 연관이 없다. ORD_YMD 조건이나, ITMD_ID 조건에 대해 적절한 인덱스가 있어도 효율적으로 사용할 수 없기 때문이다. 이와 같은 방법보다는 [SQL-1]의 UNION ALL 방법이 성능에 있어서 훨씬 유리하다. [SQL-2]의 실행계획을 살펴보자. 아래와 같다.
-- [PLAN-2] ITM_ID에 따라 다양한 구간을 조회 – CASE 사용
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 |00:00:00.02 | 359 |
| 1 | HASH GROUP BY | | 1 | 3 |00:00:00.02 | 359 |
|* 2 | TABLE ACCESS BY INDEX ROWID| T_ORD_JOIN | 1 | 3000 |00:00:00.01 | 359 |
|* 3 | INDEX RANGE SCAN | X_T_ORD_JOIN_1 | 1 | 30000 |00:00:00.01 | 87 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(CASE WHEN ("T1"."ITM_ID"='ITM002' AND "T1"."ORD_YMD">='20170102' AND
3 - access("T1"."CUS_ID"='CUS_0002')
[SQL-2]의 실행계획에서 총 Buffers는 359다. [SQL-1]보다 세 배 정도 나빠졌다. 테이블 반복을 아무리 제거해도 효율적으로 인덱스를 사용하지 못한다면 성능이 좋아질 수 없다. [PLAN-2]를 보면 X_T_ORD_JOIN_1 인덱스를 이용해 CUS_ID 조건만 access 처리했다. ([PLAN-2]의 7번, 13번 라인을 보면 알 수 있다.)
가능하면 [SQL-1]과 같이 개발하는 것이 성능에도 유리하고 명확해 보인다. 만약에 추가로 성능 개선이 필요하다면 아래와 같은 패턴을 고민해 볼 수 있다. 오라클의 LEAST와 GREATEST 함수를 사용한 방법이다.
[SQL-3] ITM_ID에 따라 다양한 구간을 조회 – LEAST, GREATEST 사용
SELECT
T1.ITM_ID
,COUNT(*) ORD_CNT
FROM T_ORD_JOIN T1
WHERE T1.CUS_ID = 'CUS_0002'
AND CASE WHEN T1.ITM_ID = 'ITM002' AND T1.ORD_YMD BETWEEN '20170102' AND '20170103' THEN 1
WHEN T1.ITM_ID = 'ITM079' AND T1.ORD_YMD BETWEEN '20170102' AND '20170115' THEN 1
WHEN T1.ITM_ID = 'ITM015' AND T1.ORD_YMD BETWEEN '20170102' AND '20170125' THEN 1
END = 1
AND T1.ORD_YMD BETWEEN LEAST('20170102','20170102','20170102')
AND GREATEST('20170103','20170115','20170125')
GROUP BY T1.ITM_ID;
[SQL-2]를 그대로 사용하고, 대신에 CUS_ID, ORD_YMD로 구성된 복합인덱스를 효율적으로 사용할 수 있도록 10번과 11번 라인에 조건을 추가했다. LEAST는 매개 변수 값 중에서 가장 작은 값을 돌려준다. GREATEST는 LEAST의 반대다. LEAST와 GREATEST의 매개 변수 값은 어느 값을 사용했는지 위 SQL을 보면 쉽게 알 수 있다. 색으로 표시해 놓았다.
실행계획을 통해 성능 개선이 되었는지 확인해보자. 아래와 같다.
[PLAN-3] ITM_ID에 따라 다양한 구간을 조회 – 최적화
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 |00:00:00.01 | 52 |
| 1 | HASH GROUP BY | | 1 | 3 |00:00:00.01 | 52 |
|* 2 | TABLE ACCESS BY INDEX ROWID| T_ORD_JOIN | 1 | 3000 |00:00:00.01 | 52 |
|* 3 | INDEX RANGE SCAN | X_T_ORD_JOIN_2 | 1 | 4000 |00:00:00.01 | 19 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(CASE WHEN ("T1"."ITM_ID"='ITM002' AND "T1"."ORD_YMD">='20170102' AND … 생략
3 - access("T1"."CUS_ID"='CUS_0002' AND "T1"."ORD_YMD">='20170102' AND "T1"."ORD_YMD"<='20170125')
총 Buffers가 52로 개선되었다. 인덱스를 추가하지 않아도, 조금만 생각해 보면 성능을 개선 할 수 있는 다양한 방법들이 있다. 항상 고민하고 좋은 방법을 찾는 습관을 갖기 바란다.
마지막으로 연습 문제를 하나 남긴다. 아래 SQL을 같은 방법으로 성능 개선을 시도해 보고 실행계획을 확인해 보기 바란다.
[SQL-4] PAY_TP에 따라 다양한 구간을 조회 – LEAST, GREATEST 사용
SELECT T1.PAY_TP
,COUNT(*) ORD_CNT
FROM T_ORD_BIG T1
WHERE T1.CUS_ID = 'CUS_0002'
AND CASE WHEN T1.PAY_TP IS NULL AND T1.ORD_YMD BETWEEN '20170102' AND '20170103' THEN 1
WHEN T1.PAY_TP = 'CARD' AND T1.ORD_YMD BETWEEN '20170102' AND '20170115' THEN 1
WHEN T1.PAY_TP = 'BANK' AND T1.ORD_YMD BETWEEN '20170102' AND '20170120' THEN 1
END = 1
GROUP BY T1.PAY_TP;