* 2024년 5월 5일 수정: 이벤트 테이블과 이벤트 응모 테이블, 상품테이블에 출시일자가 추가되었습니다.
StartUP SQL에서 여러분께 가장 먼저 보여드릴 것은 바로 ERD(Entity Relationship Diagram)입니다. ERD는 데이터베이스의 설계도입니다. SQL을 배우는데 왜 데이터베이스 설계도를 알아야 할까요? 그냥 빠르게 SQL 문법만 알려주면 되는 거 아닌가 하는 생각이 드는 분도 있을 것입니다. SQL은 관계형 데이터를 다루는 언어입니다. 다시 말해, SQL을 배우는 목적의 근본은 관계형 데이터를 다루기 위함이며, 더 나아가서 데이터를 분석하고 활용하기 위함입니다. 데이터를 분석하고 활용하는 단계에 이루기 위해서는 SQL로 활용할 데이터 구조를 충분히 이해하고 있어야 합니다.
SQL을 배우는 과정에서 ERD를 계속해서 들여다보는 습관을 갖다보면, 자연스럽게 ERD와 데이터구조가 머릿속에서 빠르게 매핑이 되며, 보다 쉽게 SQL을 작성하고 배울 수 있게 될 것입니다. SQL 입문자라면, ERD 자체가 생소할 것입니다. 걱정할 필요 없습니다. ERD를 이해하기 위해서, 지금은 아래 내용만 이해하면 됩니다.
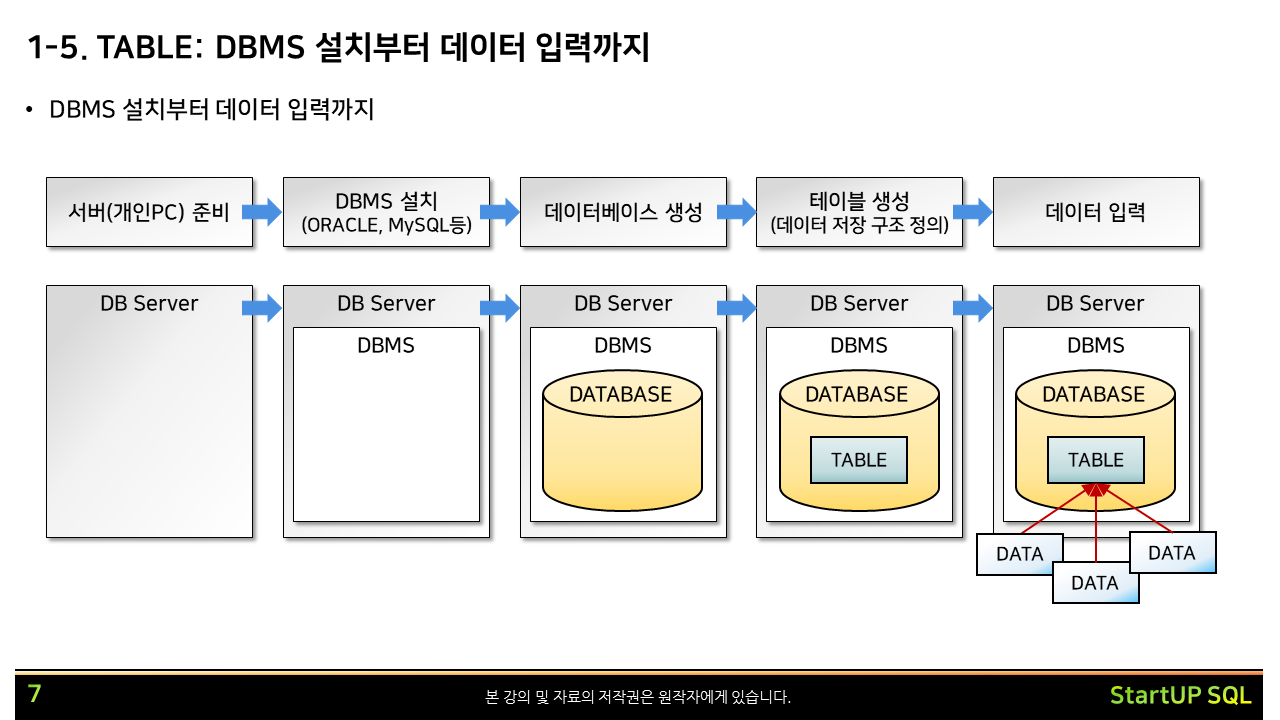
각각의 네모 하나 하나가 데이터 집합입니다.
네모의 가장 위에는 데이터 집합의 이름이 표시되어 있습니다.
네모 안에는 해당 데이터 집합이 갖고 있는 정보들이 나열되어 있습니다.
네모를 연결하는 선들이 있는데, 네모 간에 관계가 있다는 뜻으로만 이해하면 됩니다.
논리(Logical)는 우리가 쉽게 이해할 수 있는 언어로 작성된 설계도입니다.
물리(Physical)는 실제 데이터베이스에 구현된 실제 명칭을 사용한 설계도입니다.
위 내용을 토대로 논리 ERD를 읽어보면 다음과 같습니다.
매장, 주문, 회원, 주문상세, 상품과 같은 데이터 집합이 있구나.
매장 데이터집합에는 매장ID, 매장명, 매장면적, 매장운영유형과 같은 정보가 있구나.
주문에는 주문번호, 주문일시, 회원ID, 매장ID와 같은 정보가 있구나.
매장과 주문간에 선이 있는 것을 보니 관계가 있구나.
이런식으로 논리ERD를 한번씩 쭉 읽어 보시기 바랍니다. 그리고 논리ERD의 각각 명칭들이 물리ERD에 표시된 이름으로 데이터베이스에 구현된다는 정도만 알고 넘어가시면 됩니다. 앞으로 SQL을 배우는 과정에서 아래의 ERD와 같은 데이터 구조를 계속해서 보여드릴 것입니다.
1만 시간의 법칙이라고 들어보셨나요? 1만 시간을 투자한다면, 전문가가 될 수 있다는 개념입니다.
2024년을 맞이해, 새로운 기술로 1만 시간을 채워볼수 있을까란 생각이 들어 계산을 좀 해봤습니다.
SQL로요! (여기서는 MySQL을 사용했습니다.) 먼저 아래와 같이 날짜 테이블을 생성합니다.
(C_BAS_DT는 StartUP Tuning 강의에서 튜닝을 위해 소개되는 테이블입니다.)
CREATE TABLE C_BAS_DT
(
BAS_DT DATE NOT NULL
,BAS_YMD VARCHAR(8) NOT NULL
,BAS_YM VARCHAR(6) NOT NULL
,BAS_YW VARCHAR(6) NOT NULL
,BAS_DT_SEQ INT NOT NULL
,PRIMARY KEY(BAS_DT)
);
그다음에, MySQL의 RECURSIVE문을 이용해 기본 데이터를 저장합니다. 아래 SQL을 실행하면 2050년 1월 1일까지의 날짜 데이터가 C_BAS_DT에 저장됩니다.
SET @@cte_max_recursion_depth = 30000;
INSERT INTO C_BAS_DT (BAS_DT, BAS_YMD, BAS_YM, BAS_YW, BAS_DT_SEQ)
WITH RECURSIVE WR01 AS (
SELECT STR_TO_DATE('20000101','%Y%m%d') AS BAS_DT
UNION ALL
SELECT DATE_ADD(BAS_DT, INTERVAL 1 day) BAS_DT
FROM WR01
WHERE BAS_DT < STR_TO_DATE('20500101','%Y%m%d')
)
SELECT BAS_DT BAS_DT
,DATE_FORMAT(BAS_DT, '%Y%m%d') AS BAS_YMD
,DATE_FORMAT(BAS_DT, '%Y%m') AS BAS_YM
,CONCAT(YEAR(BAS_DT), LPAD(WEEK(BAS_DT), 2, '0')) AS BAS_YW
,ROW_NUMBER() OVER (ORDER BY BAS_DT) AS BAS_DT_SEQ
FROM WR01
ORDER BY BAS_DT ASC;
1만 시간의 법칙을 계산하기 위해서는 더 많은 날짜 데이터가 필요합니다. 리커시브를 계속 사용하기 보다는 셀프조인을 사용해 추가 날짜 데이터를 생성합니다.
아래의 SQL을 여러번 실행해 2300년 1월 1일까지의 데이터를 생성합니다. 세 번 정도 실행하면 됩니다.(앞에서 생성된 C_BAS_DT를 다시 사용(셀프조인)해 더 많은 연속된 날짜 데이터를 추가로 생성하는 방법입니다.)
-- INSERT 건수가 0건 될때까지 계속 실행(세번 실행하면 됨)
INSERT INTO C_BAS_DT (BAS_DT, BAS_YMD, BAS_YM, BAS_YW, BAS_DT_SEQ)
SELECT T3.BAS_DT BAS_DT
,DATE_FORMAT(T3.BAS_DT, '%Y%m%d') AS BAS_YMD
,DATE_FORMAT(T3.BAS_DT, '%Y%m') AS BAS_YM
,CONCAT(YEAR(T3.BAS_DT), LPAD(WEEK(BAS_DT), 2, '0')) AS BAS_YW
,ROW_NUMBER() OVER (ORDER BY T3.BAS_DT) + T3.MAX_DT_SEQ AS BAS_DT_SEQ
FROM (
SELECT DATE_ADD(T2.MAX_DT, INTERVAL T1.BAS_DT_SEQ day) BAS_DT
,T2.MAX_DT_SEQ
FROM C_BAS_DT T1
CROSS JOIN (SELECT MAX(X.BAS_DT) MAX_DT , MAX(X.BAS_DT_SEQ) MAX_DT_SEQ FROM C_BAS_DT X) T2
WHERE DATE_ADD(T2.MAX_DT, INTERVAL T1.BAS_DT_SEQ day) <= '23000101'
) T3
;
이제 위에서 만들어진 C_BAS_DT 테이블을 사용해, 평일에만 하루에 30분씩 투자해서 1만 시간을 채우려면 얼마나 걸릴지를, SQL로 구해봅니다. 아래와 같이 SQL을 구현해 볼 수 있습니다.
-- 오늘부터 하루에 30분씩 투자해서 평일(월,화,수,목,금)만 했을때 만시간을 채우려면 몇일이 끝일까?
-- SQL로 구해보자.
SELECT MAX(T2.BAS_DT) 만시간완료일자
,SUM(CASE WHEN T2.HOUR_SUM <= 10000 THEN 1 END) 일수
FROM (
SELECT T1.*
,DAYNAME(T1.BAS_DT) DNM
,0.5 HOUR
,SUM(0.5) OVER(ORDER BY T1.BAS_DT ASC) HOUR_SUM
FROM C_BAS_DT T1
WHERE T1.BAS_DT >= DATE_FORMAT(NOW(),'%Y%m%d')
AND DAYNAME(T1.BAS_DT) IN ('Monday','Tuesday','Wednesday','Thursday','Friday')
ORDER BY T1.BAS_DT ASC
) T2
WHERE T2.HOUR_SUM <= 10000;
만시간완료일자 |일수
---------------+-----+
2100-08-27 |20000|
제가 죽기전에는 하루에 30분씩으로는 1만 시간을 채울수가 없네요!
그렇다면, 지금 자신이 하고 있는 직업으로 1만 시간을 채우려면 얼마나걸리까요.
하루에 보통 8시간 일을 하니, 위 SQL에서 0.5 HOUR만 8 로 변경해주면 됩니다.
SELECT MAX(T2.BAS_DT) 만시간완료일자
,SUM(CASE WHEN T2.HOUR_SUM <= 10000 THEN 1 END) 일수
FROM (
SELECT T1.*
,DAYNAME(T1.BAS_DT) DNM
,8 HOUR
,SUM(8) OVER(ORDER BY T1.BAS_DT ASC) HOUR_SUM
FROM C_BAS_DT T1
WHERE T1.BAS_DT >= DATE_FORMAT(NOW(),'%Y%m%d')
AND DAYNAME(T1.BAS_DT) IN ('Monday','Tuesday','Wednesday','Thursday','Friday')
ORDER BY T1.BAS_DT ASC
) T2
WHERE T2.HOUR_SUM <= 10000;
만시간완료일자 |일수 |
----------+----+
2028-10-13|1250|
자신의 직업을 꾸준히 1250일 정도 한다면 만시간을 채울 수 있네요. 우리가 하고있는 일을 오늘부터 열심히 2028년 10월까지, 하루에 8시간씩만 쏟는다면 1만 시간을 채울 수 있습니다.
이처럼, 1만 시간을 채우기란 매우 어려운 일입니다. 실제 1만 시간을 채우지 않고도 1만 시간을 채운 효과를 보기 위해서는 다른 사람들의 도움을 받고, 다른 사람과 유연하게 협동을 해야 하지 않나란 생각이 듭니다.
2024년에서는 다양한 교육 과정과 협동을 통해 1만 시간을 더욱 단축해보실 수 있기 바랍니다.!
SQL(Structured Query Language)은 선언적 언어입니다. 그러나 SQL 튜닝을 잘하고 싶다면, SQL이 DBMS 내부적으로는 절차형 언어로 처리된다는 생각의 전환이 필요합니다. (SQL을 절차형 언어처럼 작성하라는 뜻이 절대 아닙니다.!!)
선언적 언어는 "어떻게(How)" 가 아닌 "무엇을(What)" 할 것인지, 또는 "무엇이" 필요한지를 정의하는 언어입니다. 다시말해, SQL을 사용할때는 필요한 데이터 집합이 무엇인지 정의만 해주면 됩니다. SQL과 같은 선언적 언어는 데이터를 어떠한 순서, 또는 어떠한 절차로 가져올 것인지를 정의할 필요가 없습니다.
자바, 파이썬, C와 같은 프로그래밍 언어는 절차형 언어입니다. 절차형 언어는 "무엇(What)"과 함께 "어떻게(How)"에 모두 집중해야 합니다. 절차형 언어는 필요한 결과(무엇)를 얻기 위한 절차(어떻게)까지 모두 구현해야 하기 때문입니다. 이와 같은 차이로, 절차형 언어만 다루던 분들이 초반에 SQL을 다루기 어려워하기도 합니다. 하지만, 절차형 언어를 제대로 잘하는 개발자라면, 분명히 "SQL 튜너"의 소질이 있을거라 생각합니다.
SQL은 표면적으로는 선언적 언어입니다. 하지만, DBMS 내부적으로 데이터가 처리되는 과정은 절차적입니다. 예를 들어, 뉴욕에 사는 고객의 최근 한달 주문 건수가 필요하다면, 아래와 같이 SQL로 필요한 데이터 집합을 정의해주면 됩니다.
SELECT COUNT(*) 주문건수
FROM 고객 A INNER JOIN 주문 B ON (A.고객ID = B.고객ID)
WHERE A.도시 = 'NY'
AND B.주문 >= ADD_MONTHS(NOW(),-1M);
위와 같은 SQL을 실행하면, DBMS는 내부적인 절차를 만들어 SQL에 맞는 데이터 집합을 만들어 줍니다. 이때, DBMS는 사용자가 요청한 SQL의 결과를 만들기 위해, 다양한 내부적인 처리 절차를 고려할 수 있습니다. 주문 테이블에서 최근 한달치를 읽은 후에, 고객에 접근해 결합(JOIN)할 수도 있으며, 반대로 도시가 NY인 고객을 먼저 찾은 후에 주문 테이블과 결합 할 수도 있습니다. SQL은 선언적인 언어이기 때문에, 내부적인 절차는 DBMS가 마음대로 정하고 처리하게 됩니다. 어떠한 절차로 처리하든 사용자가 요구한 데이터만 정확히 만들어주면 됩니다. 그러나, DBMS가 마음대로 처리 절차를 정한다기 보다는, SQL의 최종 결과를 얻는데 가장 비용이 적은(성능이 좋은) 방법을 고려해 절차를 정합니다. 그리고 이러한 처리 절차를 만드는 모듈이 그 유명한 옵티마이져(Optimizer)입니다.
이 글에서 SQL 성능 관련해 우리가 주목해야 할 것은, 선언적 언어인 SQL이 DBMS 내부에서는 절차적으로 처리된다는 것입니다. 그리고 이 절차에 따라 SQL의 성능 차이가 천차만별이 될 수 있습니다. SQL의 처리 절차는 실행계획(EXPLAIN)을 통해 확인할 수 있습니다. 그러므로, SQL의 성능에 이상이 있다면 가장 먼저 실행계획을 확인해야 합니다. 좀더 덧붙여 말하자면, 실행계획을 통해 SQL의 내부적인 처리 절차를 확인해야 하는 것입니다. 실행계획을 통해, 비효율적인 절차(처리 순서나 처리 방법)를 발견해 제거할 수 있다면, SQL의 성능은 저절로 좋아지게 될 것입니다.
SQL 튜닝은, 이러한 내부적인 절차를 관찰하고 비효율적인 절차를 찾아 제거하거나 변경하는 것입니다. 다시말해, SQL은 표면적으로는 선언적 언어이지만, SQL 튜닝 관점에서는 절차형 사고 방식으로 내부적인 처리 절차를 확인해야 합니다. 이러한 이해를 바탕으로 SQL 튜닝에 접근하면, SQL 튜닝을 좀 더 잘 할 수 있습니다.
끝으로, SQL을 절차적으로 작성하라는 뜻이 절대 아님을 다시 한 번 강조드립니다. 우리가 집합 개념으로 작성한 SQL이, DBMS 내부에서 어떤 절차로 처리되는지를 알 필요가 있다는 뜻입니다.
주식 분석 시스템을 만들기 위해, "종목코드"에 대한 물리명(Column Name)을 고민중입니다.
지금까지는 단순하게 Stock Code 개념으로 STK_CD를 사용해왔는데요,
글로벌하게는 Ticker 또는 Symbol이란 용어가 더 많이 사용되니까요.
글로벌한 시스템을 고려한다면 물리명을 다시 한번 고려해야겠단 생각이 들었습니다.
그래서!, GPT에게 물어봤죠.
단순한 랜덤 결정이 아닌, GPT가 데이터 아키텍쳐나 데이터 모델러 관점으로 결정할 수 있게,
실시간 웹 검색을 유도했고, 논리적으로 결정을 내려주도록 질문을 했습니다.
아래와 같이 Ticker나 Symbol 사용하는 것이 좋을거 같다는 논리를 들어 설명해줍니다.
이처럼 논리를 가지고 어떠한 결정을 하는 것은 데이터 모델러와 데이터 아키텍쳐에게 매우 중요한 부분입니다.
주식 분석 시스템의 데이터베이스에서 사용할 용어로 "Stock Code", "Ticker", "Symbol" 중에서 고르는 것에 대해 고려할 점들을 한글로 정리해드리겠습니다:
주식 기호/티커(Ticker): 주식 기호 또는 티커는 거래 목적으로 증권에 할당된 고유한 문자 시리즈입니다. 트레이더와 투자자가 특정 주식 시장의 특정 주식을 식별하기 위해 사용하는 약어 또는 코드입니다. 예를 들어, 마이크로소프트의 주식 기호는 MSFT이고 애플의 주식 기호는 AAPL입니다. 이 기호는 금융 시장에서 회사의 정체성을 확인하는 디지털 여권 역할을 하며, 거래를 간소화하여 주식 시장을 보다 효율적이고 접근하기 쉽게 만듭니다. 또한 전 세계 금융 시장 참여자들 간의 공통 언어 역할을 하여 국경을 넘는 거래를 원활하게 합니다. "티커"라는 용어는 주식 교환소에서 사용되던 티커 테이프 기계에서 유래되었으며, 이 기계는 실시간 주식 가격 및 거래 정보를 제공했습니다.
주식 코드(Stock Code): 티커 심볼 또는 주식 기호를 나타내기 위해 사용되기도 하지만, "주식 코드"는 이 용어들보다는 구체적이지 않고 국제 사용자나 주식 거래 용어에 익숙한 사람들에게 즉시 알아보기 어려울 수 있습니다. 주식 코드 또는 티커 심볼은 전보를 사용하여 주식 가격을 약어 코드로 전달하는 시스템에서 발전했습니다. 이 시스템은 1960년대까지 사용되었으며, 오늘날 이 코드들은 비즈니스 TV 보고서, 금융 웹사이트 및 기타 매체에 나타나 실시간 주식 시장 정보를 제공하는 중요한 역할을 합니다.
국제 및 지역 변형: 서로 다른 주식 거래소와 지역은 주식 심볼에 대한 자체 명명 규칙과 특정 형식을 가지고 있을 수 있습니다. 예를 들어, 아시아 시장에서는 숫자 기반 주식 심볼이 더 일반적이지만, 미국과 유럽 거래소에서는 문자 기반 심볼이 널리 사용됩니다. 또한, 일부 주식 심볼은 특히 상호 기금과 워런트에 대해 문자와 숫자를 결합할 수도 있습니다.
이 정보를 바탕으로, 주식 분석 시스템에서 "Ticker" 또는 "Symbol"을 사용하는 것이 더 적절할 수 있습니다. 특히 시스템이 글로벌 청중을 대상으로 하거나 주식 거래에 익숙한 사람들을 위한 것이라면, 이 용어들은 금융 세계에서 널리 인식되고 이해됩니다.
GPT가 Ticker와 Symbol 중에 하나를 선택을 못해서, 아무거나 하나 정해서 테이블을 설계해달라고 요청했습니다. 그러자 글로벌 인지도를 고려해 Symbol을 선택한 것을 알 수 있습니다.
기존의 논의를 바탕으로, 주식 분석 시스템을 위한 '종목마스터' 정보를 관리하는 데이터베이스 테이블을 설계할 때, "Ticker" 또는 "Symbol" 중 어느 것을 사용해도 괜찮을 것 같습니다. 두 용어 모두 주식이나 증권을 식별하는 데 널리 사용되고 있으며, 사용자와 시장의 요구에 적합한 용어를 선택하는 것이 중요합니다.
가정해 보자면, "Symbol"이라는 용어를 사용하는 것이 좋을 것 같습니다. "Symbol"은 글로벌한 인식도가 높고, 주식 시장에 익숙한 사용자들에게도 쉽게 이해될 수 있습니다. 이를 바탕으로 종목마스터 테이블을 다음과 같이 설계할 수 있습니다:
종목 심볼 (Symbol): 주식의 고유 식별자. 예: 'AAPL' (애플), 'MSFT' (마이크로소프트).
회사명 (CompanyName): 주식을 발행하는 회사의 이름.
시장 (Market): 주식이 거래되는 시장. 예: 'NASDAQ', 'NYSE'.
산업 분류 (Industry): 회사가 속한 산업 분류.
시가총액 (MarketCap): 회사의 시가총액.
주식 가격 (StockPrice): 현재 주식 가격.
배당률 (DividendYield): 주식의 배당률.
연간 수익 (AnnualRevenue): 회사의 연간 수익.
순이익 (NetIncome): 회사의 순이익.
주식 수 (SharesOutstanding): 시장에 유통되는 주식 수.
이 테이블은 주식 분석을 위한 핵심적인 데이터를 제공하며, 사용자들이 주식 시장에 대한 효율적인 분석 및 의사결정을 할 수 있도록 도와줍니다. 데이터베이스 설계는 시스템의 목적과 사용자의 요구에 따라 변경될 수 있으며, 이는 단지 기본적인 구조를 제시한 것입니다.
그런데, 설계해준 내용을 보면, 종목마스터라고 하기에는 마스터 성이 아닌 정보(주기적으로 변할 수 있는 정보)가 섞여 있습니다.(물론 최종 개념으로 마스터에 넣어줘도 무방한 정보이긴 합니다.)
어쨋든, 주기적으로 변하는 정보는 분리해서 MySQL용으로 DDL을 부탁했더니 아래와 같이 만들어주네요.
CREATE TABLE StockMaster (
Symbol VARCHAR(10) PRIMARY KEY,
CompanyName VARCHAR(100),
Market VARCHAR(50),
Industry VARCHAR(100)
);
주어진 내용에 대한 댓글을 생성하기 위해 OpenAI의 GPT 모델을 호출하는 함수입니다.
이 함수는 모델을 지정하고, 사용자의 메시지를 바탕으로 챗봇 응답을 생성합니다.
웹 페이지 크롤링
requests와 BeautifulSoup 라이브러리를 사용하여 특정 URL의 HTML 내용을 가져오고 파싱합니다.
이 코드에서는 단순하게 티스토리의 특정 페이지만 사용했습니다.
사용하는 블로그에 따라 쉽게 크롤링이 안되거나, 파싱이 안되므로 그에 맞게 코드를 변경해야 합니다.
코드는 다음과 같습니다.
# GPT를 사용한 댓글 봇 만들기.
from openai import OpenAI
import requests
import traceback
from bs4 import BeautifulSoup
client = OpenAI(api_key='각자API키를사용') # API 키 설정
def getReplyFromGPT(content):
try:
# 사용하려는 모델 지정
model = "gpt-4"
# 댓글을 생성할 메시지 설정
prompt = f"이 내용에 공감하는 댓글을 짧은 한 문장의 한글로, 진짜 사람같은 느낌으로 만들어줘: {content}"
# GPT 모델을 사용하여 챗봇 응답 생성
response = client.chat.completions.create(
model=model, # 사용할 모델 지정
messages=[
{"role": "user", "content": prompt}
]
)
res = response.choices[0].message.content
return res
except Exception as e:
print(traceback.format_exc())
# URL 설정
url = 'https://sweetquant.tistory.com/481'
# GET 요청으로 URL에서 데이터 가져오기
response = requests.get(url)
# 응답 상태 확인
if response.status_code == 200:
# HTML 내용 파싱
soup = BeautifulSoup(response.content, 'html.parser')
# 원하는 부분의 내용 추출
# 이 예제에서는 'div' 태그와 'tt_article_useless_p_margin' 클래스를 기준으로 내용을 추출합니다.
# 실제 웹사이트 구조에 따라 이 부분은 변경될 수 있습니다.
main_content = soup.find('div', class_='tt_article_useless_p_margin')
content = main_content.get_text(strip=True)
reply = getReplyFromGPT(content)
print(reply)
else:
print(f"페이지를 가져오는 데 실패했습니다. 상태 코드: {response.status_code}")
그랬더니, 갑자기 영어로.. 어쩌고 합니다. 한글로 설명을 부탁하니, 아래와 같이 설명해줍니다.
제공하신 엑셀 파일에는 2015년부터 2023년까지 각 월별로 한국을 방문한 각국 국민들의 통계 데이터가 포함되어 있습니다. 각 행은 한 달을 나타내며, 열에는 'TOTAL'이라는 총 방문자 수를 비롯하여 중국, 일본, 미국, 대만, 홍콩, 필리핀, 태국 등 다양한 국가별 방문자 수가 포함되어 있습니다. 또한 자이르, 케이맨제도, 미국인근섬과 같이 덜 일반적인 출신지에 대한 기록도 250개의 열에 걸쳐 포함되어 있습니다.
이 데이터를 통해 원하시는 특정 분석이나 요약을 진행해 드릴까요? 예를 들어, 시간에 따른 추세, 국가별 비교, 연간 요약 등이 있을 수 있습니다.
이제, 저는 면세점 직원인데 이 데이터를 이용해 마케팅 분석 보고서를 만들어야 한다고 GPT에게 말했습니다.
아래와 같이 제법 유용한 말들을 해줍니다.
월별 방문자 패턴 분석: 각 월별로 평균 방문자 수를 분석하여 특정 시즌에 방문자 수가 증가하는 경향을 파악합니다. 예를 들어, 여름 휴가철이나 명절 시즌에 방문자 수가 증가하는지 여부를 분석할 수 있습니다.
주요 국가별 방문자 비율 분석: 중국, 일본, 미국 등 주요 국가의 방문자 수를 전체 방문자 수와 비교하여 그 비율을 분석합니다. 이를 통해 주요 고객층이 어느 국가에 집중되어 있는지 파악할 수 있습니다.
국가별 월별 방문자 비교: 주요 국가들을 대상으로 각 월별 방문자 수를 비교합니다. 이를 통해 어떤 국가의 방문자들이 특정 시즌에 많이 방문하는지 파악할 수 있습니다.
이러한 분석은 면세점의 재고 관리 및 마케팅 전략 수립에 유용한 정보를 제공할 수 있습니다.
뭔가 가능한 이야기들인거 같습니다. 그래서 당장 12월 연말에 마케팅을 해야하는 관점으로 분석을 요청했습니다. 아래와 같이 답을 줍니다.
12월 연말 시즌에 대한 분석을 진행한 결과, 다음과 같은 정보를 얻었습니다:
중국: 12월 평균 방문자 수가 가장 많은 국가로, 약 215,139명입니다.
일본: 두 번째로 많은 방문자를 보내는 국가로, 평균 약 185,687명입니다.
미국: 세 번째로 방문자 수가 많으며, 평균 약 50,007명입니다.
대만, 홍콩, 태국: 이 국가들도 각각 평균 40,589명, 33,565명, 32,521명으로 상당한 방문자 수를 기록했습니다.
필리핀, 싱가포르, 말레이시아: 각각 평균 26,942명, 26,936명, 25,960명의 방문자 수를 보입니다.
교포: 평균 19,103명이 방문합니다.
이 데이터를 바탕으로, 연말 마케팅 전략을 수립할 때 중국, 일본, 미국 방문객을 주요 타겟으로 설정하는 것이 좋습니다. 또한 대만, 홍콩, 태국 등의 국가들에 대해서도 특별한 마케팅 활동을 고려할 수 있습니다. 이러한 국가의 방문객들을 위한 맞춤형 프로모션, 특별 할인, 문화적 행사 등을 기획하여 방문객들의 관심을 끌고 매출을 증대시킬 수 있을 것입니다
관련 내용을 시각화를 부탁하니 알아서 시각화도 잘 해줍니다. 그런데, GPT-4에서 데이터 분석을 통한 시각화에서는 한글이 깨지는 문제가 있습니다. 그래서 한글 부분은 영어로 번역해서 표현하도록 처리했습니다. (시각화 했던 내용은 저장되어 있지 않아 보여드릴 수가 없네요.)
계속해서 분석을 하다가, 중국 관광객이 많으니 중국인들 대상으로 마케팅을 해야 할거 같다는 생각이 들었습니다.
그래서, 중국 관광객에 대한 최신 인터넷 기사들을 검색해서, 중국 관광객과 관련 높은 키워드를 뽑아달라고 부탁했습니다.
GPT-4에는 현재 빙을 사용한 인터넷 검색 기능이 있어, 이와 같은 검색이 가능합니다. 아래와 같은 결과를 얻었습니다.
최신 중국 관광객에 대한 인터넷 기사를 검토한 결과, 다음과 같은 주요 키워드가 도출되었습니다:
MZ세대 중심의 개별 여행 선호: 중국 MZ세대(1980년대 초~2000년대 초 출생)는 단체 여행보다 개별 여행을 선호하는 경향이 있습니다.
제주도 방문 증가: 제주도는 중국인 관광객들에게 인기 있는 목적지로, 특히 MZ세대 관광객이 많이 찾고 있습니다. 제주목 관아 등의 문화 명소가 인기를 끌고 있습니다.
SNS 영향력: 중국 관광객들은 여행지를 선택할 때 SNS의 영향을 크게 받습니다. 특히 샤오홍슈(小红书)와 같은 중국 SNS 플랫폼이 중요한 역할을 합니다.
체험 중심 여행 선호: 중국 관광객들은 쇼핑 위주의 단체 관광보다 로컬 체험, 카페투어, 맛집투어 등 체험 중심의 자유 관광을 선호합니다.
모바일 결제 증가: 중국 관광객들 사이에서 모바일 페이를 통한 간편 결제의 사용이 증가하고 있습니다. 이는 소비 패턴의 변화를 반영합니다.
한복 대여 및 문화체험 인기: 중국 관광객들은 한국 전통 문화를 체험하고자 한복 대여 및 문화체험에 관심이 많습니다.
개별 여행지 및 맛집 탐방: 중국 젊은 층은 일정이 짜여진 단체관광보다 개별적으로 특정 여행지나 맛집을 집중적으로 찾는 경향이 있습니다.
이러한 키워드들은 중국 관광객을 대상으로 한 마케팅 전략을 수립하거나 워드클라우드를 만드는 데 유용하게 활용될 수 있습니다.
지금까지 만든 차트와 검색 결과를 통해 스토리 있게 발표문을 만들어 달라고 부탁했습니다. 아래와 같이 잘 만들어 주네요.
슬라이드 1: 인사 및 주제 소개
"안녕하세요, 오늘 저는 최근 중국 관광객의 트렌드 변화와 이에 따른 우리의 마케팅 전략에 대해 발표하겠습니다."
슬라이드 2: 현재 중국 관광객의 통계 및 변화
"먼저, 최근의 통계에 따르면, 중국인 관광객의 수는 올해 약 200만 명에 달할 것으로 예상되며, 이는 큰 취업 유발 효과를 가져올 것입니다. 하지만 코로나19 이전과 비교하면, 여전히 회복이 더디게 진행되고 있습니다."
슬라이드 3: 중국 MZ세대의 여행 선호도 변화
"중요한 변화 중 하나는, 중국 MZ세대가 단체 여행보다 개별 여행을 선호한다는 점입니다. 이들은 제주도 같은 특정 목적지를 찾으며, 샤오홍슈와 같은 SNS를 통해 여행지를 결정합니다."
슬라이드 4: 중국인 관광객의 소비 특성
"중국인 관광객은 체험 중심의 여행을 선호하며, 모바일 결제를 증가시키고 있습니다. 이들은 쇼핑보다는 로컬 체험, 카페투어, 맛집투어 등을 선호합니다."
슬라이드 5: 마케팅 전략 제안
"이러한 트렌드를 바탕으로, 우리는 중국 MZ세대의 개별적인 여행 스타일과 문화 체험에 초점을 맞춘 마케팅 전략을 수립해야 합니다. 예를 들어, 한복 대여 및 문화 체험 서비스를 강화하고, 개별적인 맛집이나 특별한 여행지를 홍보하는 것이 좋습니다."
슬라이드 6: 결론 및 감사 인사
"오늘 제시한 마케팅 전략이 중국 관광객 유치에 크게 기여할 것으로 기대합니다. 감사합니다."
그런데 보고서 내용이, 현재 조사한 내용만 정리되어 있는 느낌입니다.
그래서, 면세점에서 중국 관광객 대상으로 12월 마케팅을 어떻게 해야 할지 전략도 보고서에 추가해달라고 했습니다.
그랬더니, 아래와 같이 마케팅 전략 제안을 해줍니다.
개별 여행객 중심의 상품 구성: 중국 MZ세대가 선호하는 개별적인 여행 경험을 반영하여, 다양한 문화적 체험과 연계된 상품을 제공합니다.
SNS 마케팅 강화: 중국인 관광객이 많이 사용하는 SNS 플랫폼을 활용하여, 면세점의 상품과 프로모션을 홍보합니다.
모바일 결제 옵션 확대: 중국 관광객의 모바일 결제 선호도를 고려하여, 다양한 결제 옵션을 제공합니다.
문화 체험 연계 프로모션: 한복 대여, 맛집 투어 등의 체험과 연계된 프로모션을 진행하여, 면세점 방문을 유도합니다.
현지화된 고객 서비스 제공: 중국어 서비스, 문화적으로 맞춤형 상담 및 안내를 통해 고객 만족도를 높입니다.
StartUP Tuning(PostgreSQL, MySQL을 활용한 SQL 튜닝 입문) 강의에서는,
Booster QUIZ를 통해, SQL 튜닝을 각자 직접 실습해볼 수 있도록 하고 있습니다.
이와 같은 실습과 고민의 시간은 SQL 튜닝 능력 향상에 많은 도움이 됩니다.
오늘은 Booster Quiz 중에 NL 조인 관련 연습문제를 하나 풀어보도록 하겠습니다.
Booster Quiz: 아래 SQL을 NL 조인으로 처리한다고 했을때, 어느 방향으로 NL 처리하는 것이 좋은지 파악하기 위해 아래 질문에 차례대로 답해보세요.
SELECT t1.itm_id
,COUNT(*) CNT
FROM m_itm t1
INNER JOIN t_itm_evl_big t2 ON (t2.itm_id = t1.itm_id)
WHERE t1.itm_tp = 'CLOTHES'
AND t1.unt_prc <= 1000
AND t2.evl_pt = 5
GROUP BY t1.itm_id;
SQL을 보면 m_itm(아이템/품목)과 t_itm_evl_big(아이템평가), 두 개의 테이블이 사용되고 있습니다.
위 SQL에 대한 실행계획과 인덱스를 확인하지 않고 아래 질문에 차례대로 답해봅니다.
1. t1 > t2 방향으로 NL 조인한다면, t2에 방문(loop) 횟수는?
아래와 같이 원래 SQL에서 t1 부분만 추출해 카운트하면 알 수 있습니다.(답: 10번)
SELECT COUNT(*)
FROM m_itm t1
WHERE t1.itm_tp = 'CLOTHES'
AND t1.unt_prc <= 1000;
count|
-----+
10|
2. t2 > t1 방향으로 NL 조인한다면, t1에 방문(loop) 회수는?
아래와 같이 원래 SQL에서 t2 부분만 추출해 카운트하면 알 수 있습니다.(답:25,000번)
SELECT COUNT(*)
FROM t_itm_evl_big t2
WHERE t2.evl_pt = 5;
count|
-----+
25000|
1번과 2번 질문을 통해, 2번보다는 1번 방법이 더 유리할 수 있겠구나 판단할 수 있습니다.
t1>t2 방향으로 NL 조인하면 t2에는 10번만 접근하면 되고, t2>t1 방향으로 NL 조인하면 t1에는 무려 25,000번 반복 접근해야 합니다. 반복적인 접근 횟수를 줄이는 것은 SQL 성능에 도움이 됩니다. (물론 적절한 인덱스 구성이 선행되어야 합니다.)
이어서 다음 질문에도 답해봅니다.
3. 힌트를 사용해 t1 > t2 방향으로 NL 조인되도록 처리하고, 실제 실행계획을 확인
아래와 같이 힌트를 적용해 실행계획을 확인해보면, t2의 loops가 10인 것을 알 수 있습니다.
EXPLAIN (ANALYZE,BUFFERS,COSTS OFF)
/*+ Leading((t1 t2)) NestLoop(t1 t2) */
SELECT t1.itm_id
,COUNT(*) CNT
FROM m_itm t1
INNER JOIN t_itm_evl_big t2 ON (t2.itm_id = t1.itm_id)
WHERE t1.itm_tp = 'CLOTHES'
AND t1.unt_prc <= 1000
AND t2.evl_pt = 5
GROUP BY t1.itm_id;
GroupAggregate (actual time=9.148..10.760 rows=2 loops=1)
Group Key: t1.itm_id
Buffers: shared hit=296
-> Nested Loop (actual time=0.035..10.411 rows=3500 loops=1)
Buffers: shared hit=296
-> Index Scan using m_itm_pk on m_itm t1 (actual time=0.012..0.035 rows=10 loops=1)
Filter: ((unt_prc <= '1000'::numeric) AND ((itm_tp)::text = 'CLOTHES'::text))
Rows Removed by Filter: 90
Buffers: shared hit=2
-> Index Scan using t_itm_evl_big_pk on t_itm_evl_big t2 (actual time=0.807..1.004 rows=350 loops=10)
Index Cond: ((itm_id)::text = (t1.itm_id)::text)
Filter: (evl_pt = '5'::numeric)
Rows Removed by Filter: 1550
Buffers: shared hit=294
Planning Time: 0.179 ms
Execution Time: 10.792 ms
4. 힌트를 사용해 t2 > t1 방향으로 NL 조인되도록 처리하고, 실제 실행계획을 확인
아래와 같이 힌트를 적용해 실행계획을 확인해보면, t1의 실제 loops는 16번만 발생했습니다. 하지만, NL 조인의 후행 집합쪽을 보면, t1의 데이터를 Memoize 처리했고, Memoiz에 25,000 번의 반복 접근이 발생했습니다.
EXPLAIN (ANALYZE,BUFFERS,COSTS OFF)
/*+ Leading((t2 t1)) NestLoop(t1 t2) */
SELECT t1.itm_id
,COUNT(*) CNT
FROM m_itm t1
INNER JOIN t_itm_evl_big t2 ON (t2.itm_id = t1.itm_id)
WHERE t1.itm_tp = 'CLOTHES'
AND t1.unt_prc <= 1000
AND t2.evl_pt = 5
GROUP BY t1.itm_id;
HashAggregate (actual time=30.695..30.697 rows=2 loops=1)
Group Key: t1.itm_id
Batches: 1 Memory Usage: 24kB
Buffers: shared hit=1694
-> Nested Loop (actual time=0.028..30.145 rows=3500 loops=1)
Buffers: shared hit=1694
-> Seq Scan on t_itm_evl_big t2 (actual time=0.010..22.777 rows=25000 loops=1)
Filter: (evl_pt = '5'::numeric)
Rows Removed by Filter: 147500
Buffers: shared hit=1662
-> Memoize (actual time=0.000..0.000 rows=0 loops=25000)
Cache Key: t2.itm_id
Cache Mode: logical
Hits: 24984 Misses: 16 Evictions: 0 Overflows: 0 Memory Usage: 2kB
Buffers: shared hit=32
-> Index Scan using m_itm_pk on m_itm t1 (actual time=0.004..0.004 rows=0 loops=16)
Index Cond: ((itm_id)::text = (t2.itm_id)::text)
Filter: ((unt_prc <= '1000'::numeric) AND ((itm_tp)::text = 'CLOTHES'::text))
Rows Removed by Filter: 1
Buffers: shared hit=32
Planning Time: 0.186 ms
Execution Time: 30.736 ms
지금까지의 내용을 종합해, NL 조인 처리 방향에 따른 성능 차이를 아래와 같이 정리할 수 있습니다. 정리를 통해 현재 SQL에서는 어떤 방향으로 NL 조인이 적합한가를 판단할 수 있습니다.
t1 > t2
후행(t2)에 접근횟수: 10번
t1 > t2 IO(Buffers) : 296
t1 > t2 Execution time : 10.792 ms
t2 > t1
후행(t1)에 접근횟수: 실제 테이블에는 16번 접근, 하지만 memoize(cache) 처리된 데이터를 25,000번 접근.
IO(Buffers): 1694
Execution time : 30.736 ms
물론, 지금까지 살펴본 내용에 인덱스 구성을 추가하거나 변경한다면 완전히 다른 결과가 나올 수 있습니다.
여기서 중요한건, 이와 같은 순차적인 질문과 답으로 NL 조인의 방향에 따라 어떤 부분에서 성능 변화가 발생할 수 있는지 확인해보는 과정입니다.
안녕하세요. 오늘은 어떻게 보면 당연한 이야기이지만, SQL 튜닝 입문자라면 한번쯤은 생각해볼 이야기입니다.
SQL 튜닝(성능 개선)을 위해서는 SQL이 내부적으로 처리하는 데이터의 양을 정확히 파악할 필요가 있습니다. SQL의 성능은 SQL을 실행하면 나오는 최종 결과 건수 보다는 내부적으로 처리하는 데이터 양에 따라 좌우될 가능성이 높기 때문입니다.
아래의 SQL 을 살펴보도록 하겠습니다.
SELECT t1.ord_st ,COUNT(*) cnt
FROM t_ord_big t1
WHERE t1.ord_dt >= TO_DATE('20170301','YYYYMMDD')
AND t1.ord_dt < TO_DATE('20170401','YYYYMMDD')
GROUP BY t1.ord_st;
ord_st|cnt |
------+------+
WAIT | 36000|
COMP |334000|
위 SQL은 t_ord_big의 2017년 3월 데이터를 ord_st 별로 건수를 집계하고 있습니다. 실행해보면 표면적으로는 단 두 건의 데이터가 조회됩니다. 하지만, 내부적으로는 2017년 3월 전체 데이터를 접근하게 됩니다. 2017년 3월에 해당하는 데이터는 370,000 건이 있습니다. 이 수치는 위 SQL에서 GROUP BY를 제거하고 실행해보면 알 수 있습니다. (또는 위 SQL의 ord_st별 건수를 더해서도 알 수 있습니다.)
위 SQL의 튜닝을 위해서는 이 370,000건의 데이터를 어떻게 효율적으로 처리할 수 있을지를 고민해야 합니다. 370,000 건 모두를 인덱스 리프 블록에서 처리하게 할 수도 있으며, 테이블의 데이터 블록에서 처리하게 할 수도 있습니다. 이처럼 절대적으로 읽어야 할 데이터를 어떻게 효율적으로 처리할지 모색하는 것이 바로 SQL 튜닝이라 할 수 있습니다.
내부적으로 접근해야 하는 데이터 건수를 파악하는 것! 이것이 바로 SQL 튜닝의 시작점입니다. 어떤 방법으로 튜닝할까를 고민하기 전에, 절대적으로 읽어야 하는 건수가 몇 건인지 파악하는 노력을 해보기 바랍니다. 이러한 접근은 SQL 튜닝을 더 빠르고 효과적으로 수행하는 데 크게 기여할 것입니다
P.S. 위에서 실제 접근한 데이터 건수는 SQL의 실제 실행계획을 통해서도 알 수 있습니다. 아래는 PostgreSQL의 실행계획입니다. t_ord_big에 대한 인덱스를 이용해 370,000(actual 부분의 rows)건에 접근한 것을 알 수 있습니다.
HashAggregate (actual time=121.000..121.002 rows=2 loops=1)
Group Key: ord_st
Batches: 1 Memory Usage: 24kB
-> Index Scan using t_ord_big_x01 on t_ord_big t1 (actual time=0.017..57.820 rows=370000 loops=1)
Index Cond: ((ord_dt >= to_date('20170301'::text, 'YYYYMMDD'::text)) AND (ord_dt < to_date('20170401'::text, 'YYYYMMDD'::text)))
Planning Time: 0.121 ms
Execution Time: 121.035 ms
다양한 종류의 조인 연산을 보여주고 있으며, 각각의 조인 유형마다 결과 테이블이 어떻게 나타나는지 예를 들어 설명하고 있습니다.
또한, 각 조인 유형에 대한 ANSI SQL과 ORACLE SQL 구문도 제시되어 있습니다.
이미지의 내용을 기반으로 검토해보면:
Inner Join:
두 테이블(TAB1과 TAB2)에 모두 존재하는 키 값을 기준으로 조인되어 있습니다.
결과는 두 테이블에 모두 존재하는 행들만 포함합니다.
Left Outer Join:
TAB1의 모든 행과 TAB2의 일치하는 행들이 조인됩니다.
TAB1에는 있지만 TAB2에는 없는 행의 경우, TAB2 관련 컬럼은 NULL로 표시됩니다.
Right Outer Join:
TAB2의 모든 행과 TAB1의 일치하는 행들이 조인됩니다.
TAB2에는 있지만 TAB1에는 없는 행의 경우, TAB1 관련 컬럼은 NULL로 표시됩니다.
이러한 조인 방식들은 데이터베이스에서 데이터를 합치고, 관계를 분석할 때 중요한 연산입니다.
이 이미지는 SQL을 배우는 사람들에게 매우 유용한 자료로 사용될 수 있을 것 같습니다.
이미지에 표현된 내용은 정확하게 보이며, 조인 연산의 기본적인 개념을 잘 설명하고 있습니다.
이론적으로 정보는 정확해 보이지만, 실제 SQL 구문의 정확성이나 구문에 대한 실습은 해당 SQL 환경에서 직접 실행해보는 것이 가장 좋습니다. SQL의 세부적인 구현은 사용하는 데이터베이스 관리 시스템(DBMS)에 따라 다를 수 있기 때문에, 이론적인 검토 외에 실제 데이터를 사용한 검증도 중요합니다.
본 문서의 내용은 PostgreSQL 버젼에 따라 다를 수 있습니다. 본 문서에서 사용한 버젼은 아래와 같습니다.
AWS RDS PostgreSQL 15.4 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.1 20180712 (Red Hat 7.3.1-12), 64-bit
PostgreSQL의 Bitmap Index Scan
PostgreSQL의 실행계획에는 Index (Range) Scan이 아닌 Bitmap Index Scan이 종종 나타납니다.
설명에 앞서, 오라클의 Bitmap Index와 PostgreSQL의 Bitmap Index Scan를 구분할 필요가 있습니다. 이 두개는 완전히 다른 것입니다.
오라클의 Bitmap Index는 인덱스 자체를 Bitmap 형태로 구성한 것입니다.
반면에 PostgreSQL의 Bitmap Index Scan은 일반적인 B Tree 인덱스를 사용하는 처리 방식 중에 하나입니다. 다시 말해, B Tree 인덱스를 사용해 일반적인 Index Scan을 할 수도 있으며 Bitmap Index Scan을 할 수도 있습니다. Bitmap Index Scan은 인덱스를 통한 테이블 블록의 접근 횟수를 줄이기 위해 Bitmap 처리를 추가 적용한 것을 뜻합니다.
아래 SQL을 실행해 봅니다. 실행계획을 보면 x02(rno) 인덱스에 대해 Bitmap Index Scan이 작동했습니다.
총 실행 시간은 3.482 ms가 걸렸고, 3053의 IO(Buffers: shared ht)가 발생하고 있습니다.
EXPLAIN (ANALYZE,BUFFERS)
SELECT TO_CHAR(t1.ord_dt,'YYYYMM') ym,COUNT(*) cnt
FROM t_ord_big t1
WHERE t1.cus_id = 'CUS_0064'
AND t1.pay_tp = 'BANK'
AND t1.rno = 2
GROUP BY TO_CHAR(t1.ord_dt,'YYYYMM');
GroupAggregate (cost=10374.03..10374.25 rows=11 width=40) (actual time=3.446..3.448 rows=2 loops=1)
Group Key: (to_char(ord_dt, 'YYYYMM'::text))
Buffers: shared hit=3053
-> Sort (cost=10374.03..10374.06 rows=11 width=32) (actual time=3.440..3.442 rows=2 loops=1)
Sort Key: (to_char(ord_dt, 'YYYYMM'::text))
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=3053
-> Bitmap Heap Scan on t_ord_big t1 (cost=35.24..10373.84 rows=11 width=32) (actual time=0.712..3.432 rows=2 loops=1)
Recheck Cond: (rno = 2)
Filter: (((cus_id)::text = 'CUS_0064'::text) AND ((pay_tp)::text = 'BANK'::text))
Rows Removed by Filter: 3045
Heap Blocks: exact=3047
Buffers: shared hit=3053
-> Bitmap Index Scan on t_ord_big_x02 (cost=0.00..35.23 rows=3040 width=0) (actual time=0.282..0.283 rows=3047 loops=1)
Index Cond: (rno = 2)
Buffers: shared hit=6
Planning Time: 0.092 ms
Execution Time: 3.482 ms
Bitmap Index Scan 역시 Index Scan과 마찬가지로 수직적탐색과 수평적탐색, 테이블접근으로 작업이 진행됩니다.
단, 테이블 블록 접근 단계에서, 접근 횟수를 줄일 수 있도록 아래와 같은 알고리즘이 추가되어 있습니다.
인덱스 수평탐색을 하면서 얻은 ctid(실제 레코드 포인터) 정보를 모아서 비트맵으로 변환
ctid 별로 건건이 테이블 블록에 한 번씩 접근하는 것이 아니라,
ctid 를 모아서 비트맵으로 변환한 후에 같은 블록의 데이터는 한 번에 가져오는 방법
이를 통해, 불필요한 중복 접근을 줄일 수 있습니다.
마치 오라클의 TABLE ACCESS BY INDEX ROWID BATCHED 와 유사하다 할 수 있습니다.
Bitmap Index Scan에는 Bitmap Heap Scan 단계가 따라옵니다. 이는 ctid 비트맵을 사용해 Heap 테이블에 접근하는 단계입니다.
이와 같은 Bitmap Index Scan은 인덱스를 사용해 많은 데이터 블록에 접근할 가능성이 높거나, 실제 테이블의 데이터 정렬 순서와 인덱스 리프의 정렬 순서 차이가 클때 유용한 것으로 알려져 있습니다.
PostgreSQL의 pg_stats를 통해 컬럼과 테이블간의 정렬 순서의 상관 관계 통계값을 알 수 있습니다. rno의 상관 계수는 0.012로 낮은 편입니다. 결과적으로 x02 인덱스(rno)의 정렬 순서와 실제 데이터의 정렬 순서 차이가 커서 Bitmap Index Scan을 사용한 것으로 추정할 수 있습니다.
그러나! 100% 완벽한 통계는 없습니다. 아니요. 통계는 100% 완벽할 수 있을거 같습니다. 하지만, 그에 따라 선택한 옵티마이져의 결정이 항상 최선은 아닐 수 있다고 말하는게 맞을거 같습니다.
아래와 같이 힌트를 사용해 일반적인 IndexScan으로 SQL을 실행해봅니다. IO가 3,053으로 기존의 Bitmap Index Scan을 했을때와 동일합니다. 이처럼 IO가 같다면 Bitmap 연산을 추가로 수행하는 Bitmap Inedx Scan이 좀 더 느릴 수 있습니다. 현재 결과에서도 IndexScan의 실행시간이 2.416ms로 Bitmap Index Scan보다 아주 조금 더 빠릅니다.
EXPLAIN (ANALYZE,BUFFERS)
/*+ IndexScan(t1) */
SELECT TO_CHAR(t1.ord_dt,'YYYYMM') ym,COUNT(*) cnt
FROM t_ord_big t1
WHERE t1.cus_id = 'CUS_0064'
AND t1.pay_tp = 'BANK'
AND t1.rno = 2
GROUP BY TO_CHAR(t1.ord_dt,'YYYYMM');
GroupAggregate (cost=12031.20..12031.42 rows=11 width=40) (actual time=2.387..2.389 rows=2 loops=1)
Group Key: (to_char(ord_dt, 'YYYYMM'::text))
Buffers: shared hit=3053
-> Sort (cost=12031.20..12031.23 rows=11 width=32) (actual time=2.381..2.382 rows=2 loops=1)
Sort Key: (to_char(ord_dt, 'YYYYMM'::text))
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=3053
-> Index Scan using t_ord_big_x02 on t_ord_big t1 (cost=0.43..12031.01 rows=11 width=32) (actual time=0.043..2.371 rows=2 loops=1)
Index Cond: (rno = 2)
Filter: (((cus_id)::text = 'CUS_0064'::text) AND ((pay_tp)::text = 'BANK'::text))
Rows Removed by Filter: 3045
Buffers: shared hit=3053
Planning Time: 0.123 ms
Execution Time: 2.416 ms
3.482 ms나 2.416 ms나 인간이 거의 느낄 수 없는 시간 차이이기 때문에 의미가 있다고 할 수는 없습니다.
어쨋든, 옵티마이져가 선택한 방법이 최선이 아닐 수도 있다라고 한 번쯤 의심해볼 필요는 있습니다.
(절대, Bitmap Index Scan보다 Index Scan이 좋다는 일반론적 이야기가 아닙니다. 상황에 따라서는 Bitmap Index Scan이 더 유리할 수 있습니다. 또한 옵티마이져가 제대로 제 할일을 못한다라는 뜻의 이야기도 아닙니다.! 기본적으로 통계가 잘 구성되어 있다면 옵티마이져를 믿는 것이 우선입니다.)
이번에는 SQL을 살짝 바뿨봅니다. rno를 범위 조건으로 조금 더 많은 데이터를 조회해봅니다. 아래 결과를 살펴보면 Bitma Index Scan이 Index Scan보다 훨씬 적은 IO(Bitmap:3,192, IndexScan: 12,202)가 발생하고 실행시간도 근소하지만 더 빠릅니다.
EXPLAIN (ANALYZE,BUFFERS)
SELECT TO_CHAR(t1.ord_dt,'YYYYMM') ym,COUNT(*) cnt
FROM t_ord_big t1
WHERE t1.rno BETWEEN 2 AND 5
GROUP BY TO_CHAR(t1.ord_dt,'YYYYMM');
HashAggregate (cost=33470.11..33474.47 rows=349 width=40) (actual time=9.486..9.489 rows=12 loops=1)
Group Key: to_char(ord_dt, 'YYYYMM'::text)
Batches: 1 Memory Usage: 37kB
Buffers: shared hit=3192
-> Bitmap Heap Scan on t_ord_big t1 (cost=168.78..33409.45 rows=12131 width=32) (actual time=1.140..7.639 rows=12188 loops=1)
Recheck Cond: ((rno >= 2) AND (rno <= 5))
Heap Blocks: exact=3178
Buffers: shared hit=3192
-> Bitmap Index Scan on t_ord_big_x02 (cost=0.00..165.74 rows=12131 width=0) (actual time=0.741..0.741 rows=12188 loops=1)
Index Cond: ((rno >= 2) AND (rno <= 5))
Buffers: shared hit=14
Planning:
Buffers: shared hit=8
Planning Time: 0.104 ms
Execution Time: 9.546 ms
EXPLAIN (ANALYZE,BUFFERS)
/*+ IndexScan(t1) */
SELECT TO_CHAR(t1.ord_dt,'YYYYMM') ym,COUNT(*) cnt
FROM t_ord_big t1
WHERE t1.rno BETWEEN 2 AND 5
GROUP BY TO_CHAR(t1.ord_dt,'YYYYMM');
HashAggregate (cost=45715.02..45719.38 rows=349 width=40) (actual time=10.388..10.392 rows=12 loops=1)
Group Key: to_char(ord_dt, 'YYYYMM'::text)
Batches: 1 Memory Usage: 37kB
Buffers: shared hit=12202
-> Index Scan using t_ord_big_x02 on t_ord_big t1 (cost=0.43..45654.36 rows=12131 width=32) (actual time=0.015..8.493 rows=12188 loops=1)
Index Cond: ((rno >= 2) AND (rno <= 5))
Buffers: shared hit=12202
Planning:
Buffers: shared hit=8
Planning Time: 0.142 ms
Execution Time: 10.420 ms
이처럼 대량의 데이터에 접근해야 한다면, 바꿔말해 인덱스를 사용해 테이블의 데이터 블록에 많은 접근이 발생할 수 있다면, Bitmap 처리를 통해 불필요한 IO를 줄일 수 있습니다. 이것이 바로 Bitmap Index Scan입니다.
본 문서의 내용은 PostgreSQL 버젼에 따라 다를 수 있습니다. 본 문서에서 사용한 버젼은 아래와 같습니다.
AWS RDS PostgreSQL 15.4 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.1 20180712 (Red Hat 7.3.1-12), 64-bit
PostgreSQL의 EXPLAIN OPTION
PostgreSQL은 MySQL에 비해 다양하고 많은 정보를 실행계획에 표현해줍니다. PostgreSQL의 EXPLAIN 명령어 옵션들에 대해 간단히 살펴보겠습니다.
ANALYZE: 실제 쿼리를 수행하고 사용한 실행계획을 보여준다.
ANALYZE는 실제 SQL이 실행되므로, INESRT, UPDATE, DELETE에서는 사용해서는 안된다.
VERBOSE: 쿼리 계획에 추가적인 정보를 포함, 출력 컬럼과 각 노드의 OID
OID: Object Identifier, PG에서 객체를 구분하는 ID
SELECT * FROM pg_class WHERE oid = '테이블_OID';
BUFFERS: 쿼리 실행 중에 사용된 공유 버퍼, 로컬 버퍼, 그리고 쓰기 버퍼에 대한 정보
ANALYZE와 함께 사용해야 의미가 있다.
COSTS: 각 계획 단계의 추정 비용. 기본적으로 활성화되어 있음
COSTS OFF 로 예상 비용 표시 제외 가능
TIMING: 각 계획 단계의 시간 표시
ANALYZE 사용시 자동 활성화
FORMAT: 결과를 다른 형식으로 반환.
TEXT, XML, JSON, YAML입니다.
SQL 튜닝을 위해 가장 활발히 사용할 부분은 ANALYZE와 BUFFERS입니다. COSTS의 경우는 OFF도 가능합니다. 저는 교육 자료를 만들때 주로 아래와 같은 옵션으로 SQL의 실행계획을 추출합니다. (실제 튜닝 중이라면, 통계 구성을 예상할 수 있는 COSTS도 같이 보는게 좋겠죠.)
EXPLAIN (ANALYZE,BUFFERS,COSTS OFF)
SELECT /*+ NestLoop(t1 t2) */
t1.* ,t2.ord_amt
,(SELECT x.rgn_nm FROM m_rgn x WHERE x.rgn_id = t1.rgn_id) rgn_nm
FROM m_cus t1 LEFT OUTER JOIN (
SELECT a.cus_id, sum(a.ord_amt) ord_amt
FROM t_ord a
GROUP BY a.cus_id) t2 on (t2.cus_id = t1.cus_id)
WHERE t1.rgn_id = 'A';
위와 같이 EXPLAIN에 ANALYZE와 BUFFERS 그리고 COSTS OFF를 하면 아래와 같은 실행계획을 확인할 수 있습니다.
Nested Loop Left Join (actual time=1.167..1.440 rows=30 loops=1)
Join Filter: ((t2.cus_id)::text = (t1.cus_id)::text)
Rows Removed by Join Filter: 1354
Buffers: shared hit=122
-> Seq Scan on m_cus t1 (actual time=0.012..0.024 rows=30 loops=1)
Filter: ((rgn_id)::text = 'A'::text)
Rows Removed by Filter: 60
Buffers: shared hit=2
-> Materialize (actual time=0.037..0.041 rows=46 loops=30)
Buffers: shared hit=60
-> Subquery Scan on t2 (actual time=1.106..1.136 rows=89 loops=1)
Buffers: shared hit=60
-> HashAggregate (actual time=1.106..1.127 rows=89 loops=1)
Group Key: a.cus_id
Batches: 1 Memory Usage: 80kB
Buffers: shared hit=60
-> Seq Scan on t_ord a (actual time=0.002..0.229 rows=3047 loops=1)
Buffers: shared hit=60
SubPlan 1
-> Index Scan using m_rgn_pk on m_rgn x (actual time=0.001..0.001 rows=1 loops=30)
Index Cond: ((rgn_id)::text = (t1.rgn_id)::text)
Buffers: shared hit=60
Planning Time: 0.193 ms
Execution Time: 1.483 ms
위 실행계획에서 Buffers 부분이 IO에 대한 항목입니다. shared hit는 모두 메모리에서 처리된 Logical IO입니다. 디스크에서 처리된 Physical IO가 발생하면, Buffers 항목에 read로 별도 표시를 해줍니다.
이와 같은 트리형태의 실행계획과 SQL이 실제 실행된 실행계획, 그리고 각 단계별 rows, loops의 수치와 IO 수치 제공은 SQL 튜닝을 더욱 효율적으로 할 수 있도록 해줍니다. PostgreSQL의 SQL 성능때문에 고민중이라면 이와 같은 실행계획에 익숙해주시기를 권장합니다.
위와 같은 ZB급 데이터의 대다수는 동영상, 게임, 오디오, 신문 기사와 같은 비정형적인 데이터입니다.
하지만, 이처럼 데이터가 늘어난다는 것은 관계형 데이터베이스로 관리하는 정형적인 형태의 데이터도 그만큼 늘어나고 있다고 볼 수 있습니다. 비정형 데이터를 효율적으로 분석하기 위해서는 정형 데이터로 가공이 필요하기 때문입니다.
뿐만아니라, 최근에 활발하게 추진한 마이데이터 관련 사업은 비정형 데이터뿐만 아니라 정형 데이터도 폭발적으로 증가시키고 있습니다. 2020년대 들어서는 이러한 데이터 증가 현상과 함께 클라우드 환경으로의 서버 이전 현상도 활발히 일어나고 있습니다.
‘(정형)데이터 증가’와 ‘클라우드 환경’ 이 두 가지 키워드의 공통 분모에는 여러 가지가 있지만, 그 중의 하나가 바로 비용(Money)입니다.
클라우드 서비스 업체는 다양한 방법으로 비용을 청구합니다. 기본적인 데이터베이스의 디스크 용량과 함께, 디스크에 발생한 IO에 따라서도 비용이 발생합니다. 그러므로 클라우드 환경에서 데이터베이스 비용을 줄이기 위해서는 디스크를 아껴 쓰고 디스크 사용량도 줄여야 합니다.
실제로 클라우드 환경으로 넘어갔던 기업들이 디스크 비용의 부담으로 데이터 조회를 “아껴서” 하라는 난애한 지침을 내리는 경우도 있습니다. 일반적인 개발자나 데이터 분석가 수준에서 비용까지 생각하면 데이터를 핸들링하기는 매우 어려운 일입니다.
상황과 지시가 어떻든 간에, 클라우드 환경의 데이터베이스 비용을 줄이기 위해 우리가 접근할 수 있는 전략 중 하나가 바로 파티셔닝입니다. 어떤 데이터를 조회하든 비용이 발생하지만, 대부분은 빅 테이블에 비용이 집중될 가능성이 높습니다. 그러므로 우리는 빅 테이블의 파티션을 통해 비용 절감의 기회를 만들어 볼 수 있습니다.
1,000 G(Giga)의 테이블이 있다고 가정해보죠. 분석을 위해 최근 데이터 한달만 읽고 싶지만, 해당 테이블에는 일자에 대한 인덱스가 없는 상황이라면 1,000 G 전체를 스캔해야 합니다. 다시 말해, 클라우드 환경에 1,000 G에 대한 IO 비용을 지불해야 합니다. 마찬가지로 일자에 대한 인덱스가 없는 상황에서 매월 과거 한달 데이터를 삭제한다고 가정해보죠. 일자에 대한 인덱스가 없으므로 한 달치데이터 삭제를 위해서도 1,000 G의 데이터에 접근이 발생합니다.
그렇다면 일자에 대한 인덱스를 만들어 보면 어떨까요? 이 경우는 비용(Money)에 도움이 될 수도 있고 안될 수도 있습니다. 읽어야 할 한달 치의 데이터가 매우 많다면 DBMS의 옵티마이져는 인덱스가 아닌 FULL SCAN을 선택할 가능성이 있습니다. DBMS의 옵티마이져는 SQL의 성능과 관련한 비용(Cost)에만 집중을 합니다. 클라우드에 지불할 비용(Money)은 전혀 신경 쓰지 않으니까요. 또한 데이터 분포에 따라서는 인덱스로 한달 데이터를 읽은 경우가 더 많은 비용이 발생할 수도 있습니다. 삭제 역시 마찬가지입니다. 인덱스를 사용할 수도 있지만 FULL SCAN을 택할 수도 있습니다. 추가로 인덱스가 있는 상태에서 테이블 삭제가 발생한다면, 인덱스 삭제에 대한 IO 비용도 같이 발생하지 않을까 생각이 듭니다. 정리하면, 많은 데이터를 처리하기 위한 인덱스는 클라우드 비용(Money) 절약에 직접적으로 도움이 될지는 상황에 따라서 달라질 수 있습니다.
1,000 G 테이블을 월별로 파티션하면 어떨까요? 최근 한달의 데이터를 조회한다면 조회 월에 해당하는 파티션 하나만 전체로 읽으면 됩니다. 파티션 하나가 10 G라면, 10 G에 대한 IO 비용(Money)만 지불하면 됩니다. 삭제는 어떨까요? 파티션은 파티션별로 TRUNCATE나 DROP이 가능합니다. 그러므로 삭제에 대한 IO 비용 없이 데이터 삭제가 가능 할 수도 있습니다. (DBMS나 클라우드 환경에 따라 다를 수는 있습니다.)
이처럼 빅 테이블에 파티션을 지정하는 것만으로 우리는 비용을 아낄 수 있는 기회를 창출할 수 있습니다. 필요하다면, 일반 테이블의 파티션 전환을 설득하기 위해 지난 글에서 설명한 것처럼 용량 산정 작업을 진행해 볼 수 있습니다.
파티션은 클라우드 환경에서의 비용뿐만 아니라 SQL의 성능에도 도움을 줄 수 있으며, 백업 및 복구 시간의 단축에도 이득을 줍니다. 파티션은 빅 테이블의 데이터 이관에도 도움이 됩니다.
하지만 파티션이 이와 같이 장점만 있는 것은 아닙니다. 무엇보다 일반 테이블을 파티션으로 전환하는 것은 매우 어려운 일입니다. “일필휘지(一筆揮之)”하듯, 한 번에 휙 만들어 적용할 수 있는 작업이 절대 아닙니다.
파티션을 적용하면, 이미 서비스되고 있는 파티션 테이블을 사용하는 모든 SQL들의 성능에 영향을 주게 됩니다. 성능이 좋아질 수도 있지만, 반대로 성능이 나빠질 수도 있습니다. 하나의 핵심 SQL이 성능이 나빠지면, 전체 시스템을 위험에 빠뜨릴 수도 있습니다. 파티션 적용은 이러한 위험 상황을 만들 가능성도 가지고 있습니다.
제가 경험한 사이트 역시 파티션을 적용한 후 SQL을 그에 맞게 변경하지 않아 30분만에 끝나던 배치 작업이 하루 종일 걸려도 끝나지 않은 경우가 실제 있었습니다. 또한 파티션 테이블이 추가되면 그만큼 관리할 포인트가 늘어납니다. DBMS를 관리하는 입장에서는 반가운 작업이 아닐 수 있습니다. 그러므로 이미 운영 중이며 데이터가 많이 쌓인 상황에서 파티션은 정말 어려운 작업이며, 섣불리 진행하면 안 되는 작업입니다.
파티션 키와 파티션 방법을 결정하기 위해서는 비즈니스를 이해하고 기존에 개발된 SQL들도 검토해야 합니다. 또한 파티션 구성 방법의 특징을 이해하고 있어야 합니다. 다시 말해, 파티션을 정하려면 비즈니스 담당자, 개발 담당자, 데이터베이스 담당자 모두가 모여 머리를 맞대고 고민해야 합니다.
또한, 앞서 말한 것처럼 위험성에 대해서 서로가 충분히 인지하고 파티션 후의 상황에 대응할 수 있도록 서로 노력해야 합니다.
클라우드 환경이면서 테이블의 데이터가 지속적으로 늘어날 가능성이 높다면 서둘러 파티션을 고민해보기 바랍니다.
하지만, 이미 데이터가 많이 쌓여 있고 대부분의 서비스가 성숙한 상황이라면 파티션에 대해서는 좀 더 보수적으로 접근하기 바랍니다. 비용을 줄이기 위한 노력이 서비스 장애라는 더 큰 어려움을 가져올 수도 있습니다.
본 문서에서 준비한 내용은 여기까지입니다. 이 문서에서는 파티션 키를 정하는 법이나 파티션의 종류에 대해서는 설명하지 않습니다. 또한 이에 따른 SQL의 성능도 설명하지 않습니다. 간단히 설명할 수 있는 부분이 아니기 때문입니다. 파티션과 성능 관련해서는 조시형님의 “친절한 SQL 튜닝”과 “오라클 성능 고도화”를 읽어 보시는 것을 추천합니다.
기업의 데이터는 계속 쌓여가고 늘어납니다. 그것도 쉴 새 없이요. 그리고 최근에는 더 폭발적으로 늘어나고 있습니다. 데이터가 문제없이 쌓이도록 하기 위해서는 필요한 디스크 공간을 미리 산정해야 합니다. 디스크 공간 확보를 위해서는 비용(Money)이 필요하기 때문입니다. 오늘은 빅 테이블의 용량을 산정하는 법에 대해 살펴보겠습니다. 어렵지 않으며, 모두가 알만한 이야기입니다. 리마인드 개념으로 한 번 읽어 보시기 바랍니다.
1,000G(Giga)의 판매 테이블이 있다고 가정하도록 하겠습니다. 해당테이블에는 2021년 1월부터 2023년 12월까지 2년 간의 데이터가 존재합니다. 테이블 용량이 너무 커서 해당 테이블이 내년에는 얼만큼 늘어날지 걱정이 된다고 합니다.
이 상황에서 가장 간단한 용량 산정 방법은, 2년 간의 데이터가 1,000G의 용량을 차지하므로 2024년에는 1,000G의 절반인 500G가 필요하다고 산정하는 것입니다.
여기서는 이처럼 간단한 방법이 아닌, 월별로 데이터를 살펴보고 그에 따른 증가양을 분석해 2024년의 테이블 용량을 산정하려 합니다. 현대의 데이터는 날이 갈수록 쌓이는 양이 늘어나고 있습니다. 데이터의 특징(업무의 특징)에 따라 다르겠지만, 많은 생활들이 디지털화되면서 그에 맞추어 디지털로 입력되는 데이터의 양 역시 늘어나고 있습니다.
그러므로 1000G의 절반을 2024년의 디스크 용량으로 산정하기 보다는 월별로 변경되는 데이터의 양을 조사해 디스크 크기를 산정하는 것이 보다 합리적입니다.
우선 판매 테이블의 년월별 데이터 건수를 조사합니다. 이를 통해 아래와 같은 표를 만들어 낼 수 있습니다.
테이블의 전체 용량은 1,000G이고 테이블의 총 건수는 60.38 억 건입니다. 1월달의 판매 데이터가 1.32 억 건이므로 아래와 같은 계산을 통해 1월달이 차지하는 디스크 용량을 추정해 볼 수 있습니다.
ROUND(1.32 / 60.38 * 1000,2) = 21.86 G
위 식을 각 월별로 모두 적용해 월별로 용량을 추정해볼 수 있습니다. 위의 표에서 노란색 부분이 월별로 용량을 추정한 부분입니다. 각 월별 용량을 모두 합해 보면 1,000G가 되는 것을 알 수 있습니다.
이제, 위 데이터를 근거로 2024년 12월까지의 디스크 용량을 산정하면 됩니다. 이때 다양한 방법을 고려할 수 있습니다.
여기서는 “최근 6개월 간의 용량 증감의 평균 값”을 사용해 용량을 산정할 계획입니다.
(이 기준은 각자가 생각하는 적정한 수준으로 정하면 되겠지요.)
“최근 6개월 간의 용량 증감의 평균 값”을 구하기 위해서는, 먼저 각 월별로 전월 대비 증감한 용량을 구합니다.
그리고 최근 6개월의 증가에 대해서만 평균을 구하면 됩니다. 아래 표의 녹색 부분에 해당합니다.
최근 6개월 간의 용량 증감 평균이 1.02G가 나옵니다.
이제 이 1.02G란 값을 적용해 2024년의 디스크 공간을 산정하면 됩니다. 2024년 1월 용량은 2023년 12월 용량인 56.64에 1.02를 더한, 57.66이 됩니다. 이 계산을 2024년 각 월에 적용해 2024년 디스크 공간을 산정할 수 있습니다.
판매 테이블의 디스크 용량 산정에 대한 최종 결과는 아래 차트와 함께 “최근 6개 월 간의 판매 테이블의 데이터 증가양을 고려했을 때, 2024년 판매 데이터를 위해서는 최소 759G의 디스크 확보가 필요합니다.”라고 마무리할 수 있습니다.
MySQL에는 Index For GroupBy라는 강력한 기능이 있습니다. 다른 DBMS에는 없는 훌륭한 기능입니다. 테스트를 통해 다른 DBMS에 비해 얼마나 좋은 성능을 내는지 살펴보겠습니다.
1. GROUP BY COUNT - ORALE 19C SE
먼저 DBMS의 가장 큰 형님 오라클부터 살펴보겠습니다. 아래와 같이 단순히 GROUP BY와 COUNT를 하는 SQL이 있습니다. 이에 맞게 인덱스도 생성합니다. SQL을 실행해 성능을 측정해보면 17,044의 IO가 발생했습니다.
-- CREATE INDEX T_ORD_BIG_TEST_X ON T_ORD_BIG(ORD_YMD);
SELECT T1.ORD_YMD, COUNT(*)
FROM T_ORD_BIG T1
WHERE T1.ORD_YMD > ' ' -- 인덱스를 강제로 사용하게 하기 위해 조건 사용
GROUP BY T1.ORD_YMD
ORDER BY 1 DESC;
-------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 100 |00:00:03.81 | 17044 |
| 1 | SORT GROUP BY | | 1 | 100 |00:00:03.81 | 17044 |
|* 2 | INDEX FAST FULL SCAN| T_ORD_BIG_TEST_X | 1 | 6094K|00:00:01.54 | 17044 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("T1"."ORD_YMD">' ')
2. GROUP BY COUNT - PostgreSQL 16.1
이번에는 PostgreSQL에서 작업을 해봅니다. 아래와 같습니다. 오라클과 마찬가지로 인덱스 리프를 모두 읽어 GROUP BY를 처리합니다. 그 결과 IO(Buffers) 가 52,401이나 나옵니다.
-- CREATE INDEX t_ord_big_test_x on t_ord_big(ord_ymd);
SELECT t1.ord_ymd, COUNT(*)
FROM t_ord_Big t1
GROUP BY t1.ord_ymd
ORDER BY 1 DESC;
GroupAggregate (actual time=30.175..10685.530 rows=365 loops=1)
Group Key: ord_ymd
Buffers: shared hit=52401
-> Index Only Scan Backward using t_ord_big_test_x on t_ord_big t1
(actual time=0.017..4792.832 rows=61194000 loops=1)
Heap Fetches: 0
Buffers: shared hit=52401
Planning Time: 0.064 ms
Execution Time: 10685.672 ms
3. GROUP BY COUNT - MySQL 8.0.22
이번에는 MySQL입니다. MySQL 역시 GROUP BY와 카운트가 사용된 SQL은 리프 페이지를 모두 스캔해야 하므로 제법 시간이 걸립니다. 77,979 페이지의 IO가 발생했습니다.
SELECT T1.ORD_YMD, COUNT(*)
FROM T_ORD_BIG T1
GROUP BY T1.ORD_YMD
ORDER BY 1 DESC;
-> Group aggregate: count(0) (actual time=28.596..10960.686 rows=349 loops=1)
-> Index scan on T1 using T_ORD_BIG_X05(reverse)
(actual time=1.328..7564.492 rows=6094000 loops=1)
id table ptype key key_len rows Extra
-- ----- ------ ------------- ------- ------- --------------------------------
1 T1 Nindex T_ORD_BIG_X05 35 6145479 Backward index scan; Using index
- Time sec: 7.538511
* Rows read: 6094000
* Buffer pages: 77979
4. ONLY GROUP BY - ORALE 19C SE
다시, 오라클로 돌와옵니다. 이번에는 GROUP BY만 SQL에 존재합니다. COUNT 처리는 하지 않습니다. 이전과 같은 17,044의 IO가 발생했습니다.
SELECT T1.ORD_YMD
FROM T_ORD_BIG T1
WHERE T1.ORD_YMD > ' ' -- 인덱스를 강제로 사용하게 하기 위해 조건 사용
GROUP BY T1.ORD_YMD
ORDER BY 1 DESC;
------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts |A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 100 |00:00:03.67 | 17044 |
| 1 | SORT GROUP BY | | 1 | 100 |00:00:03.67 | 17044 |
|* 2 | INDEX FAST FULL SCAN| T_ORD_BIG_TEST_X | 1 | 6094K|00:00:01.54 | 17044 |
------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("T1"."ORD_YMD">' ')
5. GROUP BY COUNT - PostgreSQL 16.1
PostgreSQL에서 GROUP BY만 있는 SQL을 실행해봅니다. 2번과 마찬가지로 52,401의 IO가 발생합니다.
SELECT t1.ord_ymd
FROM t_ord_Big t1
GROUP BY t1.ord_ymd
ORDER BY 1 DESC;
Group (actual time=0.019..9361.799 rows=365 loops=1)
Group Key: ord_ymd
Buffers: shared hit=52401
-> Index Only Scan Backward using t_ord_big_test_x on t_ord_big t1
(actual time=0.018..4604.412 rows=61194000 loops=1)
Heap Fetches: 0
Buffers: shared hit=52401
Planning Time: 0.060 ms
Execution Time: 9361.961 ms
6. GROUP BY COUNT - MySQL 8.0.22
마지막으로 MySQL에서 COUNT 없이 GROUP BY만 사용해봅니다. 두둥!!! IO가 1,056으로 획기적으로 줄었습니다.
이는 MySQL에만 존재하는 내부적인 알고리즘때문인듯 합니다. 클래식 실행계획의 Extra를 보면 Using index for group-by가 표시되어 있습니다. 또한 Tree 실행계획에는 using index_for_group_by라고 표시되어 있습니다.
SELECT T1.ORD_YMD
FROM T_ORD_BIG T1
GROUP BY T1.ORD_YMD
ORDER BY 1 DESC;
id table type key key_len rows Extra
-- ----- ----- ------------- ------- ---- -----------------------------
1 T1 range T_ORD_BIG_X05 35 351 Using index for group-by; ...
-> Group (computed in earlier step, no aggregates) (actual time=7.000..7.138 rows=349 loops=1)
-> Sort: t1.ORD_YMD DESC (actual time=6.998..7.066 rows=349 loops=1)
-> Table scan on <temporary> (actual time=0.002..0.051 rows=349 loops=1)
-> Temporary table with deduplication (actual time=5.657..5.775 rows=349 loops=1)
-> Index range scan on T1 using index_for_group_by(T_ORD_BIG_X05)
(actual time=0.149..5.239 rows=349 loops=1)
- Time sec: 0.011888
* Rows read: 350
* Buffer pages: 1056
결론
SQL에서 집계함수 없이 GROUP BY만 사용되고 있고, GROUP BY 컬럼이 인덱스로 커버가 되는 상황이라면, MySQL의 성능이 압도적으로 좋습니다. 정확히는 MySQL의 실행계획에 index_for_group_by가 출현해야 합니다. 그러나, 이와 같은 패턴, 이와 같은 상황은 실제 SQL에서 잘 나오지 않습니다. 특히나 SQL이 복잡해질수록 거의 나오기 힘든 패턴입니다.
그러므로 이런 기능 하나로 MySQL이 다른 DBMS보다 좋다라고 할 수는 없습니다. 각 DBMS마다 가지고 있는 장점과 단점이 있습니다. 우리는 이러한 부분을 잘 파악하고 그에 맞게 사용해야 합니다.
어쨋든, MySQL을 운영하고 있다면, 이와 같은 기능이 있음을 잘 기억할 필요가 있습니다. 가끔 업무 요건에 따라, 튜닝을 위해 써먹을 수 있는 그런 기술이니까요.
위와 같이 SQL을 사용한다면 전혀 문제 없습니다. 그런데 실수로(?) 또는 습관적으로 GROUP BY 를 추가하는 경우가 있습니다. 아래와 같이 말이죠. 아래 SQL은 위의 SQL과 완전히 같은 결과를 보여줍니다. 하지만, 성능적으로는 차이가 있습니다.
IO를 보면 45로 기존 대비 10배 이상 증가했습니다. 물론, 따져보면 실제 실행시간은 이전이나 지금이나 거의 차이는 없습니다. 인덱스만 이용해 SQL이 처리되기 때문입니다. 실행계획을 살펴보면, GROUP BY 를 위해 Index range scan이 나온것을 알 수 있습니다.
SELECT MAX(T1.ORD_DT) LAST_ORD_DT
FROM T_ORD_BIG T1
WHERE T1.CUS_ID = 'CUS_0001'
GROUP BY T1.CUS_ID; -- > GROUP BY 를 추가!!!!
Execution Plan:
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
-- ----------- ----- ---------- ----- --------------------------- ------------- ------- ---- ---- -------- -------------------------------------
1 SIMPLE T1 None range T_ORD_BIG_X03,T_ORD_BIG_X04 T_ORD_BIG_X04 163 None 228 100.0 Using where; Using index for group-by
-> Group aggregate (computed in earlier step): max(t1.ORD_DT) (actual time=0.105..0.126 rows=1 loops=1)
-> Filter: (t1.CUS_ID = 'CUS_0001') (cost=159.60 rows=228) (actual time=0.102..0.122 rows=1 loops=1)
-> Index range scan on T1 using index_for_group_by(T_ORD_BIG_X04) (cost=159.60 rows=228) (actual time=0.099..0.119 rows=1 loops=1)
- Time sec: 0.000999
* Rows read: 4
* Buffer pages: 45
PostgreSQL 16.1
PostgreSQL도 다르지 않습니다. 먼저 GROUP BY 없이 마지막 일자를 가져오는 SQL입니다. IO(Buffers) 수치를 보면 4입니다.
SELECT MAX(T1.ORD_DT) LAST_ORD_DT
FROM T_ORD_BIG T1
WHERE T1.CUS_ID = 'CUS_0001';
Result (actual time=0.057..0.059 rows=1 loops=1)
Buffers: shared hit=4
InitPlan 1 (returns $0)
-> Limit (actual time=0.052..0.053 rows=1 loops=1)
Buffers: shared hit=4
-> Index Only Scan Backward using t_ord_big_x04 on t_ord_big t1 (actual time=0.049..0.050 rows=1 loops=1)
Index Cond: ((cus_id = 'CUS_0001'::text) AND (ord_dt IS NOT NULL))
Heap Fetches: 0
Buffers: shared hit=4
Planning Time: 0.298 ms
Execution Time: 0.100 ms
이번에는 같은 결과이지만, GROUP BY를 추가한 SQL입니다. IO(Buffers) 수치가 64로 급등한 것을 알 수 있습니다. 같은 결과이지만, GROUP BY 가 추가되었으므로 내부적으로 GROUP BY 를 처리하기 때문입니다.
SELECT MAX(T1.ORD_DT) LAST_ORD_DT
FROM T_ORD_BIG T1
WHERE T1.CUS_ID = 'CUS_0001'
GROUP BY T1.CUS_ID;
GroupAggregate (actual time=20.337..20.339 rows=1 loops=1)
Buffers: shared hit=64
-> Index Only Scan using t_ord_big_x04 on t_ord_big t1 (actual time=0.037..11.810 rows=66000 loops=1)
Index Cond: (cus_id = 'CUS_0001'::text)
Heap Fetches: 0
Buffers: shared hit=64
Planning Time: 0.132 ms
Execution Time: 20.385 ms
ORACLE 19C SE
내친김에 오라클도 살펴보도록 하겠습니다. 이 부분은 오라클도 별반 다르지 않습니다. 아래는 GROUP BY가 없는 경우로 3블록의 IO가 발생했습니다.
아래는 GROUP BY가 추가된 경우입니다. IO가 260으로 매우 높습니다. 다른 DBMS보다 나쁘지만 이는 의미가 없습니다. 데이터가 실제 저장되어 군집된 상태가 다를 수 있기 때문입니다.
SELECT MAX(T1.ORD_DT) LAST_ORD_DT
FROM T_ORD_BIG T1
WHERE T1.CUS_ID = 'CUS_0001'
GROUP BY T1.CUS_ID;
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.03 | 260 |
| 1 | SORT GROUP BY NOSORT| | 1 | 1 | 1 |00:00:00.03 | 260 |
|* 2 | INDEX RANGE SCAN | T_ORD_BIG_X04 | 1 | 1 | 66000 |00:00:00.12 | 260 |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T1"."CUS_ID"='CUS_0001')
결론
사소한 습관성 GROUP BY를 사용하지 않도록 주의합시다. 실제 시간상으로 성능 차이가 크지는 않지만 DB 내부적인 IO에서는 제법 차이가 있으며, 해당 SQL이 정말 자주 실행된다면 불필요한 연산으로 DB 자원 사용량 증가에도 영향을 줄 수있습니다. 무엇보다 중요한 것은, 결론만 외우는 것이 아니라 실행계획을 통해 이와 같은 차이점을 확인하고 이해하는 것입니다.
위와 같은 인덱스 구성에서 다음과 같은 SQL을 실행합니다. SQL에서는 ORD_DT 조건만 사용하고 있습니다.
아래 SQL의 성능을 위해서는 ORD_DT가 선두 컬럼인 인덱스를 추가해야 하지만, 여기서는 인덱스 추가를 고려하지 않습니다. 현재 인덱스 구성에서 선두 컬럼이 ORD_DT인 인덱스는 존재하지 않습니다. 그러므로 일반적인 Index Scan이나 Index Lookup은 할 수 없습니다. 하지만 MySQL 8에서는 Index Skip Scan을 활용할 수 있으므로, ORD_DT가 두 번째 컬럼으로 위치한 T_ORD_JOIN_X02 인덱스를 사용할 수 있습니다. 아래 SQL의 TREE 형태의 실행계획을 보면 Index for skip scan이 있는 것을 알 수 있습니다. IO를 측정(Buffer pages)해보면 4,224 페이지의 IO 호출이 있었습니다. 실행시간 기준으로 0.94초 정도가 걸렸고요.
-- 1. INDEX 컬럼만 조회, SKIP SCAN 발생, Buffers = 4224
SELECT T1.CUS_ID ,T1.ORD_DT
FROM T_ORD_JOIN T1
WHERE T1.ORD_DT >= STR_TO_DATE('20170301','%Y%m%d')
AND T1.ORD_DT < STR_TO_DATE('20170305','%Y%m%d');
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
-- ----------- ----- ---------- ----- -------------- -------------- ------- ---- ------ -------- --------------------------------------
1 SIMPLE T1 None range T_ORD_JOIN_X02 T_ORD_JOIN_X02 168 None 356310 100.0 Using where; Using index for skip scan
-> Filter: ((t1.ORD_DT >= <cache>(str_to_date('20170301','%Y%m%d'))) and (t1.ORD_DT < <cache>(str_to_date('20170305','%Y%m%d')))) (cost=96850.94 rows=356310)
-> Index range scan on T1 using index_for_skip_scan(T_ORD_JOIN_X02) (cost=96850.94 rows=356310)
* Rows read: 32180
* Buffer pages: 4224
2. SELECT 절에 인덱스 외의 컬럼을 조회 - TABLE FULL SCAN 발생
이제 SQL을 변경해봅니다. 앞에서 실행한 SQL은 T_ORD_JOIN_X02 인덱스에 있는 컬럼만 사용하고 있습니다.
다음과 같이 T1.*로 SQL을 변경해 실행해봅니다. 실행계획을 보면 Table scn(TABLE FULL SCAN)으로 변경이 되었습니다 IO 수치 역시 49,677로 이전 Index Skip Scan보다 열배 이상 늘어났습니다. 실행시간도 3.33초로 증가했습니다. 이처럼 SELECT 절에 인덱스 외의 컬럼이 추가되자 Index Skip Scan이 작동하지 않습니다. 인덱스를 통해 다시 클러스터드 인덱스에 접근하는 부하가 크다고 옵티마이져가 판단했기 때문에 FULL SCAN을 선택했을 것이라 생각이 듭니다.
(현재까지 테스트로는 인덱스에 없는 컬럼이 하나라도 추가되면 FULL SCAN으로 처리됩니다. 다른 테이블(두 번째 컬럼의 카디널리티가 큰 테이블)을 사용해도 마찬가지입니다. 이는 두 번째 컬럼의 통계를 적절히 계산 못하는 상황이 있는거 아닌가란 생각이 듭니다.)
-- 2. INDEX 이외의 컬럼을 사용, TABLE FULL SACN으로 변경됨, Buffers = 49677
SELECT T1.*
FROM T_ORD_JOIN T1
WHERE T1.ORD_DT >= STR_TO_DATE('20170301','%Y%m%d')
AND T1.ORD_DT < STR_TO_DATE('20170305','%Y%m%d')
Execution Plan:
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
-- ----------- ----- ---------- ---- ------------- ---- ------- ---- ------- -------- -----------
1 SIMPLE T1 None ALL None None None None 3207440 11.11 Using where
-> Filter: ((t1.ORD_DT >= <cache>(str_to_date('20170301','%Y%m%d'))) and (t1.ORD_DT < <cache>(str_to_date('20170305','%Y%m%d')))) (cost=341086.14 rows=356311)
-> Table scan on T1 (cost=341086.14 rows=3207440)
* Rows read: 3224000
* Buffer pages: 49677
3. SELECT 절에 PK 컬럼만 조회 - INDEX SKIP SCAN 발생
이번에는 인덱스 컬럼인 CUS_ID, ORD_DT가 아닌 ORD_SEQ를 SELECT 절에 사용해 봅니다. 그러면 다시 Index Skip Scan이 작동합니다. MySQL의 InnoDB는 테이블마다 PK로 클러스터드 인덱스를 만들고, 넌클러스터드 인덱스의 리프 노드에는 클러스터드 인덱스의 키(PK) 값을 저장하기 때문에, 이처럼 PK 컬럼을 SELECT하는 경우는 기존의 X02 인덱스만 사용해서 해결이 가능합니다.
이러한 포인트를 잘 이해했다면, 이 부분을 응용해 T1.* 와 같은 결과를 만들어내면서 Index Skip Scan을 유지할 수 있습니다. (이 부분은 별도 글로 올리도록 하겠습니다.)
-- 3. PK 컬럼(ORD_SEQ)만 SELECT, INDEX SKIP SCAN, Buffers = 4224
SELECT T1.ORD_SEQ
FROM T_ORD_JOIN T1
WHERE T1.ORD_DT >= STR_TO_DATE('20170301','%Y%m%d')
AND T1.ORD_DT < STR_TO_DATE('20170305','%Y%m%d');
id select_type table partitions type possible_keys key key_len ref rows filtered Extra
-- ----------- ----- ---------- ----- -------------- -------------- ------- ---- ------ -------- --------------------------------------
1 SIMPLE T1 None range T_ORD_JOIN_X02 T_ORD_JOIN_X02 168 None 356310 100.0 Using where; Using index for skip scan
-> Filter: ((t1.ORD_DT >= <cache>(str_to_date('20170301','%Y%m%d'))) and (t1.ORD_DT < <cache>(str_to_date('20170305','%Y%m%d')))) (cost=96849.94 rows=356310)
-> Index range scan on T1 using index_for_skip_scan(T_ORD_JOIN_X02) (cost=96849.94 rows=356310)
* Rows read: 32180
* Buffer pages: 4224
준비한 내용은 여기까지입니다. MySQL도 이제 Index Skip Scan이 있다 정도를 알고 가시면 될거 같습니다.^^
MySQL 또는 PostgreSQL의 SQL 튜닝 입문 강의가 필요하신 분은 아래 링크를 참고해주세요.!
Leading(table table[ table...]) - Forces join order as specified. - 지정된 대로 조인 순서를 강제한다 Leading(<join pair>) - Forces join order and directions as specified. A join pair is a pair of tables and/or other join pairs enclosed by parentheses, which can make a nested structure. - 지정된 대로 조인 순서와 방향을 강제한다. 조인 쌍은 괄호로 둘러싸인 테이블 또는 다른 조인 쌍의 쌍이며, 이를 통해 중첩 구조를 만들 수 있다
이처럼 두 가지 사용법이 적혀 있습니다. 하지만 이 설명만 봐서는 잘 이해할 수 없습니다.
Leading 힌트의 용법을 이해하기 위해서는 조인 순서와 조인 방향에 대해 정의할 필요가 있습니다.
조인 순서: 조인을 처리하는 순서
조인 순서가 A, B, C: A와 B를 조인해, (A, B)를 만든 후에 (A, B)와 C를 조인하는 순서로 처리
이처럼 조인 순서만 정의하면, 두 데이터 집합을 조인할 때는 어떤 방향으로 조인할지는 알 수 없다.
예를 들어, A와 B를 조인할 때 어느 테이블을 먼저 처리할지는 알 수 없다.
(A, B)와 C를 조인할 때도, 어느 쪽을 먼저 접근해 처리할지는 알 수 없다.
조인 방향: 두 데이터 집합이 결합(조인)할 때 정해지는 두 데이터 집합 간의 접근 순서
A, B, C의 조인 순서이면서, A에서 B 방향으로 조인, C에서 (A, B) 방향으로 조인
조인 순서와 함께 조인 방향이 정의되었다.
A에서 B 방향으로 조인 처리해서 (A, B) 생성, C에서 (A, B) 데이터 집합 방향으로 조인 처리
A, B, C의 조인 순서이면서, B에서 A 방향으로 조인, (B, A)에서 C 방향으로 조인
B에서 A 방향으로 조인 처리해서 (B, A) 생성, (B, A) 집합에서 C 방향으로 조인 처리
아마 이해가 될 듯하면서도 이해가 안될 수도 있습니다. 조인 순서나 조인 방향이나 얼핏 보기에 비슷하니까요.
아래와 같이 Leading(t1 t2) 로 힌트를 지정합니다. 이처럼 괄호를 하나만 사용하면 조인 순서만 지정됩니다. 이 경우 NL 조인을 한다고 가정하면 t1을 먼저 접근해 t2 방향으로 조인을 처리할 지, t2를 먼저 접근해 t1 방향으로 조인을 처리할지 알 수 없습니다. 이러한 조인 방향은 옵티마이져가 선택합니다. 사실 두 개 테이블만 있는 상황에서는 이 같은 조인은 불필요합니다.
/*+ Leading(t1 t2) */
SELECT t1.cus_id ,SUM(t2.ord_qty) ord_qty
FROM m_cus t1
INNER JOIN t_ord_join t2
ON (t2.cus_id = t1.cus_id)
WHERE t1.cus_gd = 'B'
AND t2.ord_dt >= TO_DATE('20170201','YYYYMMDD')
AND t2.ord_dt < TO_DATE('20170301','YYYYMMDD')
GROUP BY T1.cus_id;
이번에는 Leading 힌트에 괄호를 중첩해서 사용합니다. 이와 같이 정의하면 조인 방향이 정해집니다. 단순한 NL 조인이라면, 앞에 있는 t1이 선행 집합이 되어 t2 방향으로 접근해 조인이 처리됩니다. 그런데, SQL이 HASH 조인으로 풀린다면 주의가 필요합니다. Leading 힌트의 뒤쪽에 있는 t2가 Build가 되고, t1이 Probe가 됩니다.
다시 말해, HASH JOIN에서는 Build가 일반적으로 먼저 만들어진다는 개념과, Leading의 서술에 따른 순서가 반대되므로 이 부분은 외워두기 바랍니다.
/*+ Leading((t1 t2)) */
SELECT t1.cus_id ,SUM(t2.ord_qty) ord_qty
FROM m_cus t1
INNER JOIN t_ord_join t2
ON (t2.cus_id = t1.cus_id)
WHERE t1.cus_gd = 'B'
AND t2.ord_dt >= TO_DATE('20170201','YYYYMMDD')
AND t2.ord_dt < TO_DATE('20170301','YYYYMMDD')
GROUP BY T1.cus_id;
이번에는 세 개 테이블을 조인해봅니다. 아래와 같이 Leading에서 순서만 지정해봅니다. t1, t2, t3, 순서의 조인만 유지합니다. 두 데이터 집합이 조인되는 순간에는 어느쪽을 선행을 할지, HASH 조인이라면 어느쪽을 Build로 할지는 옵티마이져가 알아서 선택합니다.
/*+ Leading(t1 t2 t3) */
SELECT t1.itm_id ,t1.itm_nm ,t2.ord_st ,count(*) ord_qty
FROM m_itm t1
INNER JOIN t_ord_join t2 on (t2.itm_id = t1.itm_id)
INNER JOIN m_cus t3 ON (t3.cus_id = t2.cus_id)
WHERE t1.itm_tp = 'ELEC'
AND t2.ord_dt >= TO_DATE('20170201','YYYYMMDD')
AND t2.ord_dt < TO_DATE('20170301','YYYYMMDD')
AND t3.cus_gd = 'B'
GROUP BY t1.itm_id ,t1.itm_nm ,t2.ord_st;
조인순서와 함께 조인 방향을 모두 지정하고 싶다면 아래와 같이 괄호를 조인이 발생하는 두 데이터 집합간에 추가 중첩합니다. 아래 SQL의 조인되는 순서와 방향을 정리하면 다음과 같습니다.
Leading(((t1 t2) t3)) 괄호가 세 번 중첩, t1과 t2를 묶고, (t1 t2)와 t3를 한 번 더 묶었습니다.
이러한 정의가 틀리지는 않지만, 이 부분에만 포커스를 맞추어서 접근하다 보면 튜닝이 더 어려울 수 있습니다.
SQL 성능 개선의 초심자라면, “SQL을 빠르게 만들자” 보다는, “SQL의 비효율을 찾아 제거해보자”라는 개념으로 접근하는 것이 좀 더 쉽습니다.
그러므로 저는 SQL 튜닝에 대해 다음과 같이 정의합니다. “SQL 튜닝이란 SQL의 비효율을 제거하는 작업이다. 여기에 SQL의 중요도에 따라 추가 최적화를 이끌어 내야 하는 작업이다.” 여기서 SQL의 중요도는 사용 빈도나 업무의 중요성으로 판단할 수 있습니다.
SQL 튜닝 관련해 제가 경험한 몇 가지 사례를 살펴보겠습니다. 안타깝게도 MySQL이나 PostgreSQL 보다는 오라클에서 겪었던 경험이 주를 이룹니다.
제가 경험한 사이트 중에 12시간이 지나도 끝나지 않는 SQL이 있었습니다. 해당 SQL에는 3억 건 이상의 데이터 집합 두 개가 조인하고 있었고, 이 외에도 천 만 건 이상의 여러 테이블이 조인이 되는 한 문장의 배치 SQL이었습니다. 물론 오라클의 병렬 처리도 작동하고 있는 SQL이었습니다. 이러한 배치 SQL은 튜닝이 쉽지 않습니다. 튜닝의 실제 효과를 알기 위해서는 실행을 해야 하는데, 한 번 실행하면 최소 몇 시간은 걸리기 때문입니다. 어려운 상황 속에서도 SQL을 부분별로 나누어서 살펴보다 보니, 조인 전에 매우 많은 IN 조건이 처리되면서 오래 걸리는 것을 확인해습니다. IN 보다 조인이 먼저 처리되도록 SQL을 변경하자 4시간 이내로 SQL이 완료되었니다. 이는 조인을 먼저 하면 결과 건수가 줄어들어 IN 처리할 대상이 그만큼 줄어들어 개선 효과가 있었던 사례입니다. 어느 한 사이트는 사용자들이 비교적 자주 실행하는 SQL인데도 43초가 걸리고 있었습니다. SQL을 살펴보니, 특정 사용자가 자신의 데이터만 조회하는 SQL임에도 불구하고 사용자ID에 대한 조건을 LIKE로 처리하고 있었습니다. 이로 인해 사용자ID에 대한 인덱스를 사용하지 않아 오래 걸리는 케이스였습니다. 이 경우는 힌트로 해결할 수도 있지만, 가장 좋은 것은 프로그램을 변경해 사용자ID에 대한 조건을 같다(=) 조건으로 처리하는 것입니다. 이와 같이 처리하면 DBMS의 옵티마이져가 알아서 사용자ID에 대한 인덱스를 사용하게 됩니다. 이를 통해 43초 걸리던 SQL은 0.02초로 개선이 되었습니다.
또 다른 사이트는 차세대 사이트로서, 고객의 주문을 집계하는 배치에서 성능 저하가 있었습니다. AS-IS에서는 30분이 안 걸리던 집계 처리가 차세대에서는 6시간 이상이 걸리는 상황이 발생한 것입니다. 원인을 살펴보니 차세대로 넘어가면서 관련 테이블을 파티션으로 변경했고, SQL이 파티션의 키 값을 활용하지 못하도록 되어 있어 성능 저하가 발생한 것입니다. SQL을 변경해 파티션 키를 사용할 수 있도록 변경을 해주었고, 원래의 성능으로 돌아갈 수 있었습니다. 지금까지 소개한 사례들은 주로 오라클 환경에서의 경험입니다. MySQL 환경에서의 사례도 있습니다. MySQL 환경에서 업데이트 SQL이 한 시간 이상 걸려 문의가 들어온 적이 있었습니다. SQL은 업데이트 대상을 상관 서브쿼리 방식으로 선별하고 있었고, 실행계획을 확인해 보니, 상관 서브쿼리의 테이블을 FULL SCAN으로 처리하고 있었습니다. SQL을 중지하고 업데이트 대상 선별 방식을 직접적인 조인으로 변경하자 10초만에 업데이트가 완료되었습니다.
지금까지 살펴본 튜닝 사례에서 저는 “SQL을 빠르게 하자”가 아닌, “이 SQL의 비효율이 뭐지?”라는 방향으로 접근을 했습니다. 이와 같은 방향으로 접근해 비효율을 제거하다 보면, SQL은 저절로 빨라지게 됩니다.
사람마다 다를 수 있지만, 저에게 SQL 튜닝은 그 과정 자체가 미지의 세계를 탐험하는 것처럼 매우 흥미롭고 흥분되는 일입니다. 마치 셜록 홈즈가 사람의 겉모습만을 보고 그 사람의 직업과 과거를 맞추는 것처럼, SQL과 실행계획을 통해 문제점을 직관적으로 찾아내는 것은 행복한 흥분을 선사합니다.
StartUP Tuning 강의를 통해 SQL 튜닝의 기본을 습득하고, 그 신나는 세계에 한 발짝 들어와 보기 바란다.
MySQL에서 테이블을 생성할 때, 캐릭터셋(CHARSET)과 콜레이션(COLLATION)을 설정할 수 있습니다.
캐릭터셋과 콜레이션은 테이블뿐만 아니라 컬럼 단위로도 설정이 가능합니다.
이러한 설정을 잘못하면 조인 SQL 자체가 실행이 안될 수도 있으며, 이는 성능 저하로 연결될 수도 있습니다.
캐릭터셋과 콜레이션은 데이터베이스에서 문자 데이터를 저장하고 비교하는 방식을 뜻합니다.
캐릭터셋(Character Set)
데이터베이스에 저장할 수 있는 문자들의 집합
각 문자셋은 다양한 문자를 인코딩하는 코드를 정의합니다. UTF-8, ASCII, LATIN1등이 있습니다.
UTF-8은 국제적으로 널리 사용되는 캐릭터셋입니다. 거의 모든 언어와 이모지까지 지원합니다.
캐릭터셋에 따라 같은 텍스트도 다른 방식으로 저장될 수 있습니다.
콜레이션(Collation)
문자 데이터를 비교하고 정렬할때 사용하는 규칙의 집합입니다.
대소문자 구분, 악센트 구분, 문자의 정렬 순서 등을 정의합니다.
콜레이션에 따라 언어와 문자의 우선 순위가 달라질 수 있습니다.
이러한 캐릭터셋과 콜레이션은 MySQL이 설치되면서 서버 레벨(DBMS)에서 정의가 됩니다.
my.cnf나 my.ini에 기본으로 값이 설정되어 있으며, 변경이 가능합니다.
현재 운영중인 시스템에서 서버레벨에서 이 설정을 변경하는 순간 매우 큰 혼란이 만들어지게 됩니다.
서버 레벨에서 정의한 캐릭터셋과 콜레이션은 데이터베이스를 생성할 때 상속됩니다.
그리고 데이터베이스에 만들어진 캐릭터셋과 콜레이션은 다시 테이블에 상속됩니다.
캐릭터셋과 콜레이션이 이미 상속되어 테이블이 만들어진 상태에서 이와 같은 설정을 변경한다면 어떤 여파가 있을지 상상하기도 힘듭니다. 그러므로 캐릭터셋과 콜레이션은 서비스를 시작하기 전에 정의되어야 합니다. 아니, 개발을 시작하기 전 설계 단계에서부터 정의되어야 맞습니다.
MySQL 관련된 블로그나 자료를 찾다 보면, 테이블을 생성할 때, 캐릭터셋이나 콜레이션을 지정해서 생성하는 스크립트를 볼 수 있습니다. 이러한 스크립트를 카피해서 사용하다 보면, 예상하지 못한 문제에 마주칠 수 있습니다.
먼저, 자신이 접속한 데이터베이스의 캐릭터셋과 콜레이션을 살펴봅니다.
# 사용할 기본 데이터베이스 변경하기
USE MYTUNDB;
# 현재 계정이 사용하는 기본 데이터베이스 확인하기
SHOW VARIABLES LIKE 'character_set%';
-- character_set_database utf8mb4
-- character_set_connection utf8mb4
SHOW VARIABLES LIKE 'collation%';
-- collation_database utf8mb4_0900_ai_ci
-- collation_connection utf8mb4_0900_ai_ci
위와 같이 기본 캐릭터셋과콜레이션이 있음에도 불구하고, 아래와 같이 COLLATE를 기본과 다른 설정으로 생성을 해봅니다. 인터넷을 검색하다 알게된걸 그냥 카피해서 사용한 것이죠. 데이터베이스의 기본 콜레이트는 utf8mb4_0900_ai_ci이지만, 아래 테이블은 utf8mb_unicode_ci 를 사용했습니다.
CREATE TABLE MYTUNDB.T_ORD_TEST
(
ORD_SEQ BIGINT UNSIGNED NOT NULL COMMENT'주문번호',
CUS_ID VARCHAR(40) NOT NULL COMMENT '고객ID',
ORD_DT DATETIME NULL COMMENT '주문일시',
ORD_ST VARCHAR(40) NULL COMMENT '주문상태',
PAY_DT DATETIME NULL COMMENT '결제일시',
PAY_TP VARCHAR(40) NULL COMMENT '결제유형',
ORD_AMT DECIMAL(18,3) NULL COMMENT '주문금액',
PAY_AMT DECIMAL(18,3) NULL COMMENT '결제금액',
PRIMARY KEY(ORD_SEQ)
)
CHARSET=utf8mb4
COLLATE=utf8mb4_unicode_ci
COMMENT '주문테스트';
-- 테스트를 위한 데이터 입력 및 인덱스 생성
INSERT INTO MYTUNDB.T_ORD_TEST SELECT* FROM T_ORD;
CREATE INDEX T_ORD_TEST_X01 ON T_ORD_TEST(CUS_ID);
이제 기존에 원래 있던 테이블과 조인 SQL을 만들어 실행해 봅니다.
SELECT *
FROM MYTUNDB.M_CUS T1
INNER JOIN MYTUNDB.T_ORD_TEST T2 ON (T2.CUS_ID = T1.CUS_ID)
WHERE T1.CUS_ID = 'CUS_0001'
위 SQL을 실행해보면 다음과 같은 에러를 만납니다.
Illegal mix of collations (utf8mb4_unicode_ci,IMPLICIT) and (utf8mb4_0900_ai_ci,IMPLICIT) for operation '='
두 테이블(M_CUS와 T_ORD_TEST)간에 조인 조건으로 사용한 CUS_ID가 테이블별로 다른 콜레이트를 사용하기 때문에 발생한 에러입니다. 두 테이블의 CUS_ID에 대한 콜레이트는 아래 SQL로 확인할 수 있습니다.
SELECT TABLE_NAME, COLUMN_NAME, CHARACTER_SET_NAME, COLLATION_NAME
FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME IN ('M_CUS','T_ORD_TEST') AND COLUMN_NAME = ('CUS_ID')
AND TABLE_SCHEMA = 'MYTUNDB';
TABLE_NAME|COLUMN_NAME|CHARACTER_SET_NAME|COLLATION_NAME |
----------+-----------+------------------+------------------+
m_cus |CUS_ID |utf8mb4 |utf8mb4_0900_ai_ci|
t_ord_test|CUS_ID |utf8mb4 |utf8mb4_unicode_ci|
이와 같이 콜레이트가 다른 상황에서 SQL을 실행하기 위한 임시 방편은 아래와 같이 조인시 콜레이트를 재정의하는 것입니다. 아래는 T1(M_CUS)의 콜레이트를 T2(T_ORD_TEST)와 동일하게 변경한 경우입니다.
EXPLAIN ANALYZE
SELECT *
FROM MYTUNDB.M_CUS T1
INNER JOIN MYTUNDB.T_ORD_TEST T2 ON (T2.CUS_ID = T1.CUS_ID COLLATE utf8mb4_unicode_ci)
WHERE T1.CUS_ID = 'CUS_0001'
;
-> Index lookup on T2 using T_ORD_TEST_X01 (CUS_ID=('CUS_0001' collate utf8mb4_unicode_ci)) (cost=11.55 rows=33) (actual time=0.168..0.183 rows=33 loops=1)
실행계획을 보면, T_ORD_TEST_X01이라는 인덱스를 사용해 결과를 처리하고 있습니다.
인덱스를 사용한다고 성능이 무조건 좋은건 아니지만, 원하는 방향으로 처리가 되고 있습니다.
만약에 콜레이트를 T1쪽이 아닌 T2쪽의 콜레이트를 변경하면 어떻게 될까요? 아래와 같이 T2(T_ORD_TEST)를 FULL SCAN하는 것을 알 수 있습니다.
빅데이터와 No-SQL 기술의 등장은 우리에게 텍스트, 이미지, 비디오, 음성과 같은 다양한 형태의 데이터를 새로운 방식으로 다루게 했습니다. 이전에는 '데이터'라고 하면 대부분의 사람들이 컬럼과 로우로 구성된 테이블 형태의 '관계형 데이터'를 떠올렸습니다. 하지만 지금은 그 경계가 흐려졌습니다.
No-SQL 기술이 주목받을 때, 많은 이들이 관계형 데이터베이스의 중요성이 줄어들 것이라 예상했지만, 그러지 않았습니다. No-SQL은 그 자체로 중요한 기술이지만, 관계형 데이터베이스를 완전히 대체할 수는 없었습니다. 이는 기업의 업무에 필요한 데이터를 다루기에 관계형 구조의 데이터가 효율이 가장 좋기 때문입니다.
그렇다면, 생성형 AI의 선두 주자인 GPT와 같은 기술의 등장은 어떨까요? GPT는 관계형 데이터베이스의 위치에 어떤 영향을 줄까요? 실제로 GPT는 테이블 형태의 데이터를 저장하거나 관리하는 기능에는 한계가 있습니다. 그러나, GPT는 관계형 데이터의 분석 및 해석에 있어 매우 유용한 도구로 활용할 수 있습니다.
기업들이 오랜 시간 동안 쌓아온 관계형 데이터는 이제는 GPT와 같은 기술을 통해 새로운 가치와 인사이트를 제공할 수 있습니다. 따라서 GPT의 등장은 기업들에게 오랜 시간 동안 축적해온 관계형 데이터를 다시 한번 깊게 다뤄볼 기회를 제공하게 될 것입니다.
간단한 예를 살펴보도록 하죠. 아래는 제가 사용하는 샘플 DB에서 월별 제품카테고리별 판매 현황을 추출한 SQL입니다.
(기업의 관계형 데이터를 추출해냈다고 생각하면 되는 것이죠.)
SELECT DATE_FORMAT(T1.ORD_DT,'%Y%m') Order_YearMonth
,T3.ITM_TP ItemCategory
,COUNT(*) OrderQty
,SUM(T1.ORD_AMT) OrderAmount_KRW
FROM MYTUNDB.T_ORD T1
INNER JOIN MYTUNDB.T_ORD_DET T2 ON (T2.ORD_SEQ = T1.ORD_SEQ)
INNER JOIN MYTUNDB.M_ITM T3 ON (T3.ITM_ID = T2.ITM_ID)
GROUP BY DATE_FORMAT(T1.ORD_DT,'%Y%m')
,T3.ITM_TP
ORDER BY Order_YearMonth, ItemCategory;
위 SQL로 추출한 결과를 아래와 같이 첨부하니, GPT-4를 사용하시는 분들은 똑같이 분석을 해보시기 바랍니다.
위 데이터를 GPT-4를 사용해 분석을 요청해 아래와 같은 결론을 얻었습니다. GPT를 통해 더욱 다양한 분석 기법을 요청할 수도 있습니다. 또한 집요하게 물어볼 수록 우리가 쉽게 얻기 어려운 정보도 얻어낼 수 있습니다.
- 제품 유형별로는 '의류' 카테고리에 더 주력하는 것이 좋을 것 같습니다. - 월별 판매 추이를 보면 1월부터 4월까지, 그리고 8월부터 10월까지 판매가 상승하는 추세를 보이므로 이 기간에 판매 활동을 강화하는 것이 좋습니다. - 계절별로는 여름에 판매가 가장 활발하므로 여름 시즌에 특히 주의를 기울이면 좋을 것 같습니다.
예산 상의 한계로 고가의 분석 도구나 전문 분석가를 고용하지 못했던 기업들에게는 GPT와 같은 AI 도구가 저렴하면서도 효과적인 분석 도구로서 큰 기회가 될 수 있습니다.
더불어, 인간이 놓치기 쉬운 데이터의 패턴이나 정보를 GPT를 통해 발견할 수도 있을 것입니다.
그렇지만, 아쉽게도 한계는 존재합니다. 대량의 데이터 처리는 여전히 제한적이며, 특히 실시간 분석에도 한계가 있습니다. 분석 과정에서 예상치 못한 방향으로 진행될 수도 있어, AI의 분석 결과는 반드시 인간이 검증하고 해석해야 합니다.
마지막으로 강조하고 싶은 것은, 관계형 데이터의 중요성이 여전하다는 것입니다. GPT와 같은 혁신적인 기술의 등장에도 불구하고, 관계형 데이터를 다루는 기초적인 학문인 SQL과 관계형 데이터베이스 기술의 중요성은 여전하므로 지속적인 학습과 연구가 필요하다는 것을 잊지 말아야 합니다.