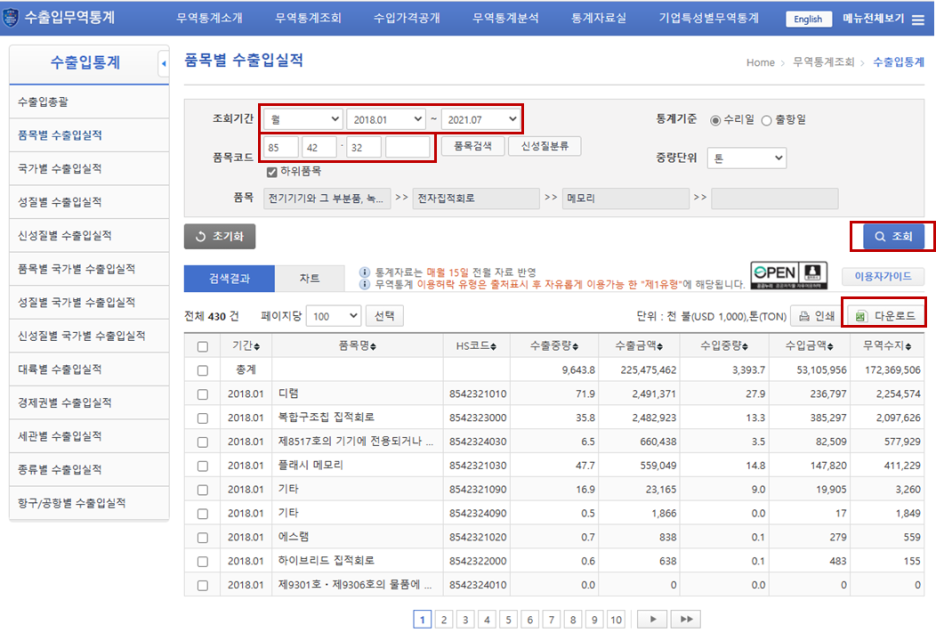
지난 글에서는 메모리 품목 수출입 데이터를 다운로드해서 DB화했습니다.
- https://sweetquant.tistory.com/312
메모리 품목 수출입 데이터 DB화하기
안녕하세요. 오늘은 분석에 필요한, 또는 SQL 연습에 필요한 새로운 데이터를 추가해보겠습니다. 바로, 수출입 통계 데이터입니다. 수출 데이터를 분석하면, 수출이 증가한 업종에 대해 투자
sweetquant.tistory.com
메모리 품목 관련해서 다양한 품목이 있는데, 그 중에 수출금액이 가장큰 품목 세 개만 조회해보겠습니다. 아래와 같이 SQL을 실행합니다.
MySQL에서 Top-N을 추출하기 위해 가장 쉽게 사용할 수 있는 것이 바로 LIMIT입니다. 아래와 같습니다.
SELECT HS_NM
,ROUND(SUM(OUT_AMT)) SUM_OUT_AMT
,MIN(YM) MIN_YM
,MAX(YM) MAX_YM
,ROUND(AVG(OUT_AMT)) AVG_OUT_AMT
FROM DB_DTECH.TRADE_YM
GROUP BY HS_NM
ORDER BY 2 DESC
LIMIT 3;
[결과]
HS_NM SUM_OUT_AMT MIN_YM MAX_YM AVG_OUT_AMT
============================== ============= ======== ======== =============
디램 189563001 201001 202107 1363763
복합구조칩 집적회로 170826060 201001 202107 1228964
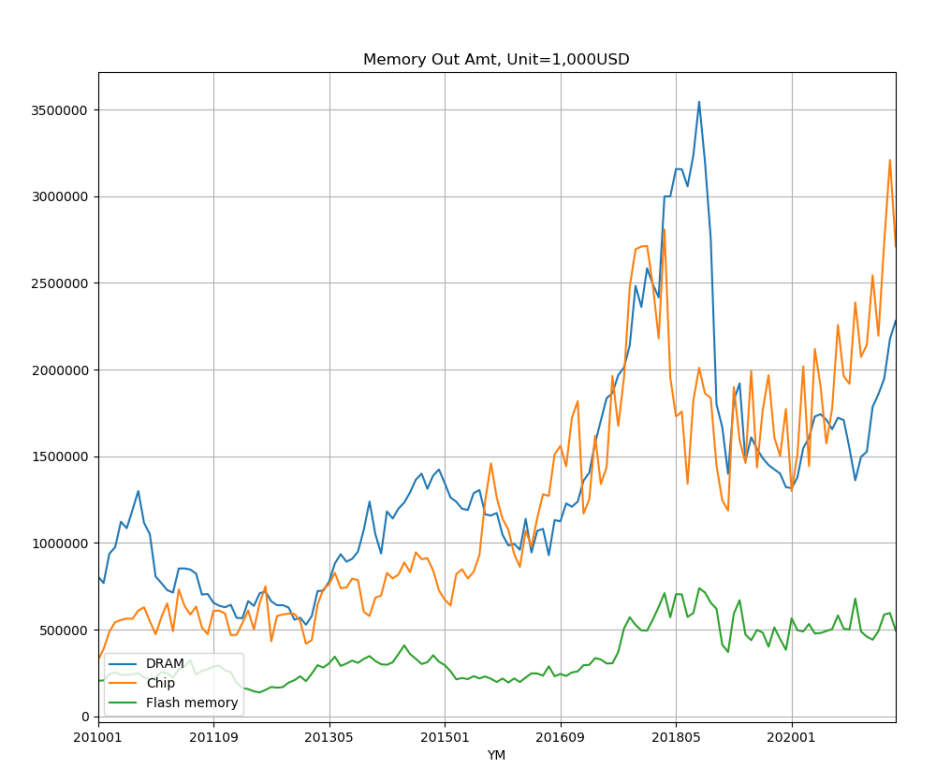
플래시 메모리 49402623 201001 202107 355415위 SQL을 통해 메모리 관련 세부 품목 중에, 디램, 복합구조칩 집적회로, 플래시 메모리가 가장 수출이 많은것을 알 수 있습니다. 디램의 경우, 2010년 1월부터 2021년 7월까지 총 189,563,001 천USD 수출을 했고, 월평균 1,363,763 천USD 만큼 수출했습니다. 현재 환율로 계산하면 월평균 1.5조원 정도 되는거 같습니다. 어마어마한 금액이네요.
이번에는 위에서 찾은 세 개 품목에 대해 월별 수출금액을 구해봅니다. 품목명을 컬럼으로 처리하기 위해 아래와 같이 GROUP BY와 CASE를 사용합니다. 분석 SQL에서 PIVOT을 구혆려면 GROUP BY 와 MAX 또는 SUM이 필수죠.
SELECT T1.YM
,MAX(CASE WHEN T1.HS_NM = '디램' THEN T1.OUT_AMT END) DRAM
,MAX(CASE WHEN T1.HS_NM = '복합구조칩 집적회로' THEN T1.OUT_AMT END) CHIP
,MAX(CASE WHEN T1.HS_NM = '플래시 메모리' THEN T1.OUT_AMT END) FLASH
FROM DB_DTECH.TRADE_YM T1
WHERE T1.HS_NM IN ('디램','복합구조칩 집적회로','플래시 메모리')
GROUP BY T1.YM
ORDER BY T1.YM
[결과]
YM DRAM CHIP FLASH
======== ============= ============= ============
201001 807931.000 322032.000 205735.000
201002 768520.000 388025.000 206517.000
201003 937606.000 487808.000 242982.000
... 생략 ...끝으로, 위의 SQL을 파이썬에서 실행해 결과를 차트로 그려보는겁니다. 간단합니다.
import pymysql
import pandas as pd
import matplotlib.pyplot as plt
# MySQL 연결 처리
myMyConn = pymysql.connect(user='root', password='1qaz2wsx', host='localhost', port=3306,charset='utf8', database='DB_SQLSTK')
myMyCursor = myMyConn.cursor()
# 실행할 SQL 생성
sql = """
SELECT T1.YM
,SUM(CASE WHEN T1.HS_NM = '디램' THEN T1.OUT_AMT END) DRAM
,SUM(CASE WHEN T1.HS_NM = '복합구조칩 집적회로' THEN T1.OUT_AMT END) CHIP
,SUM(CASE WHEN T1.HS_NM = '플래시 메모리' THEN T1.OUT_AMT END) FLASH
FROM DB_DTECH.TRADE_YM T1
WHERE T1.HS_NM IN ('디램','복합구조칩 집적회로','플래시 메모리')
GROUP BY T1.YM
ORDER BY T1.YM
"""
# DataFrame에 SQL 결과 저장
df = pd.read_sql(sql, myMyConn)
# 결과 출력
print(df)
# 차트로 처리할 항목을 Series에 별도로 담는다.
dram = df['DRAM']
chip = df['CHIP']
flash = df['FLASH']
dram.index = df['YM']
plt.figure(figsize=(11,9))
dram.plot(label='DRAM', title= "Memory Out Amt, Unit=1,000USD")
chip.plot(label='Chip')
flash.plot(label='Flash memory')
plt.legend(loc='lower left')
plt.grid(True)
plt.show()아래와 같이 세부 품목별 수출금액을 차트로 볼 수 있습니다.
오늘은 여기까지입니다.~!
감사합니다.
위와 같이 주식 데이터를 마음대로 분석해볼 수 있는 SQL을 공부하고 싶다면 아래 책을 참고해주세요~!
※ 책 소개: https://sweetquant.tistory.com/243
※ 책 미리보기: https://sweetquant.tistory.com/257
※ 완전판 E-Book
▶ 유페이퍼: https://www.upaper.net/ryu1hwan/1142997
▶ 알라딘: https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=273701425
▶ Yes24: http://www.yes24.com/Product/Goods/102264444?OzSrank=1

'데이터분석 > D-Tech 데이터로 하는 재테크' 카테고리의 다른 글
| 셀프 조인 이해하기 (0) | 2021.09.23 |
|---|---|
| 데이터 분석 - 오라클의 CORR 집계함수 (0) | 2021.09.17 |
| 복합구조칩 수출과 상관 관계가 가장 높은 종목은? (0) | 2021.09.08 |
| 메모리 수출과 하이닉스와 삼성전자의 주가 (0) | 2021.09.04 |
| 메모리 품목 수출입 데이터 DB화하기 (0) | 2021.09.03 |
| 수출이 급증한 300215 품목의 정체는? (0) | 2021.09.03 |
| 수출 통계로 투자 업종 찾기 (0) | 2021.09.02 |
| 2021.08.31 종목별 최적의 골든크로스! (0) | 2021.09.01 |