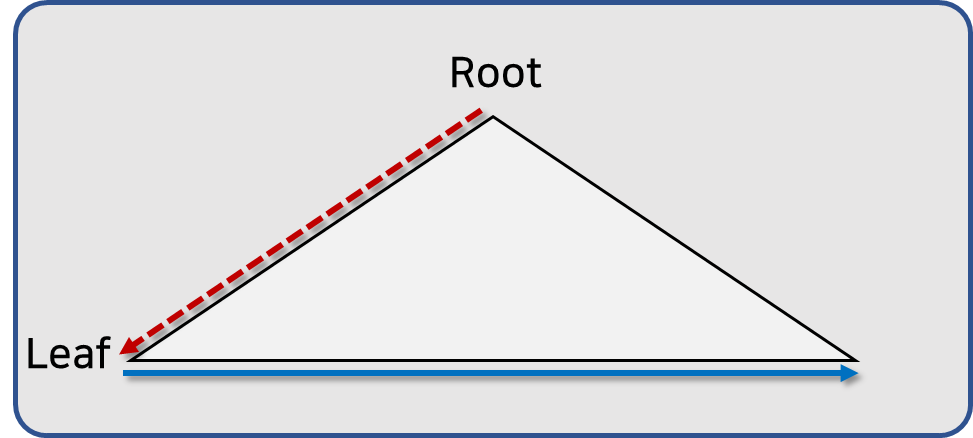
저번 글에서는 인덱스 탐색 과정에 대해 간단하게 설명했습니다.
그리고 인덱스 탐색을 어떻게 표현하지는도 살펴봤습니다.
이번에는 실제 MySQL에서 인덱스 관련된 실행 게획을 어떻게 표현하는지 살펴보도록 하겠습니다.
1. MySQL의 인덱스 실행 계획: EXPLAIN FORMAT = TREE
EXPLAIN FORMAT = TREE로 지정했을 때 인덱스 관련 동작이 어떻게 표현되는지 알아보겠습니다.
이번 글에서는 EXPLAIN FORMAT = TREE 기준을 설명하고, 다음 글에서는 고전적인 실행게획에서 인덱스 관련 동작이 표시되는 방법을 설명할 예정입니다.
아래와 같이 SQL을 실행합니다. 아래 SQL은 ORD_DT에는 범위 조건을 사용했습니다.(범위 조건을 사용해 2017년 1월 4일 하루만 조회합니다.)
앞에서 T_ORD_BIG 테이블의 ORD_DT 컬럼에 대해서는 T_ORD_BIG_X1 인덱스를 생성했습니다. 그러므로 아래 SQL은 해당 인덱스를 사용해 처리가 될 확률이 높습니다. 실행계획을 살펴보면, 가장 아래에 'Index range scan'이 표시되어 있습니다. 그리고 'using T_ORD_BIG_X1'이라고 어떤 인덱스를 사용했는지 친절하게 표시되어 있습니다. MySQL이 버젼이 올라갈수록, 실행계획을 해석하기 좋게 보여주고 있습니다.
EXPLAIN FORMAT = TREE
SELECT COUNT(*)
FROM MYTUNDB.T_ORD_BIG T1
WHERE T1.ORD_DT >= STR_TO_DATE('20170104','%Y%m%d')
AND T1.ORD_DT < STR_TO_DATE('20170105','%Y%m%d');
-> Aggregate: count(0)
-> Filter: ((mytundb.t1.ORD_DT >= <cache>(str_to_date('20170104','%Y%m%d'))) and (mytundb.t1.ORD_DT < <cache>(str_to_date('20170105','%Y%m%d')))) (cost=182.54 rows=900)
-> Index range scan on T1 using T_ORD_BIG_X1 (cost=182.54 rows=900)
이번에는 ORD_DT에 범위 조건이 아닌, 같다(=) 조건을 사용한 SQL을 실행해봅니다. (위 SQL과 똑같이 2017년 1월 4일 하루만 조회합니다.) 아래와 같슽니다. 실행계획을 살펴보면 'Index range scan'이 사라지고, 'Index lookup'이 표시되었습니다.
EXPLAIN FORMAT = TREE
SELECT COUNT(*)
FROM MYTUNDB.T_ORD_BIG T1
WHERE T1.ORD_DT = STR_TO_DATE('20170104','%Y%m%d');
-> Aggregate: count(0)
-> Index lookup on T1 using T_ORD_BIG_X1 (ORD_DT=str_to_date('20170104','%Y%m%d')) (cost=92.53 rows=900)
'Index lookup' 역시 'Index range scan' 처럼 수직점 탐색과 수평적 탐색이 발생합니다. 그러므로 결국 실제 작동하는 내용은 Index range scan과 같다고 보시면 됩니다.
MySQL은 인덱스를 사용하는 상황에서, 사용된 조건이 범위(>=, <=, BETWEEN) 조건이면 Index range scan을, 같다(=) 조건이면 Index lookup으로 실행계획을 표시해줍니다.
이번에는 아래와 같이 SQL을 실행합니다. WHERE 절에서 ORD_DT 컬럼을 DATE_FORMAT 처리했기 때문에 인덱스를 '효율적'으로 사용 못하는 경우입니다.(인덱스를 사용은 하지만 비효율적인 방법으로 사용하게 됩니다.) 실행계획을 보면 'Index scan'이라고 표시되어 있습니다. 이 부분만 보면, '인덱스를 탔네'라고 생각할 수 있습니다. 하지만, 아래 경우는 인덱스의 리프 노드를 모두 읽어서 조건을 처리한 경우입니다.
EXPLAIN FORMAT = TREE
SELECT COUNT(*)
FROM MYTUNDB.T_ORD_BIG T1
WHERE DATE_FORMAT(T1.ORD_DT,'%Y%m%d') = '20170104'
-> Aggregate: count(0)
-> Filter: (date_format(mytundb.t1.ORD_DT,'%Y%m%d') = '20170104') (cost=31559.80 rows=301158)
-> Index scan on T1 using T_ORD_BIG_X1 (cost=31559.80 rows=301158)
방금 살펴본, SQL 세 개를 EXPLAIN ANALYZE를 사용해 각각 실행해봅니다. 아래와 같은 실제 실행 계획을 확인할 수 있습니다.
1. 범위 조건 ANALYZE
-> Aggregate: count(0) (actual time=0.462..0.462 rows=1 loops=1)
-> Filter: ((mytundb.t1.ORD_DT >= <cache>(str_to_date('20170104','%Y%m%d'))) and (mytundb.t1.ORD_DT < <cache>(str_to_date('20170105','%Y%m%d')))) (cost=180.64 rows=900) (actual time=0.034..0.407 rows=900 loops=1)
-> Index range scan on T1 using T_ORD_BIG_X1 (cost=180.64 rows=900) (actual time=0.032..0.241 rows=900 loops=1)
2. 같다(=) 조건 ANALYZE
-> Aggregate: count(0) (actual time=0.383..0.383 rows=1 loops=1)
-> Index lookup on T1 using T_ORD_BIG_X1 (ORD_DT=str_to_date('20170104','%Y%m%d')) (cost=90.63 rows=900) (actual time=0.042..0.316 rows=900 loops=1)
3. 컬럼변경(DATE_FORMAT) ANALYZE
-> Aggregate: count(0) (actual time=200.378..200.378 rows=1 loops=1)
-> Filter: (date_format(mytundb.t1.ORD_DT,'%Y%m%d') = '20170104') (cost=31559.80 rows=301158) (actual time=1.075..200.319 rows=900 loops=1)
-> Index scan on T1 using T_ORD_BIG_X1 (cost=31559.80 rows=301158) (actual time=0.108..85.289 rows=304700 loops=1)위 내용을 보면 '1. 범위 조건' 보다 '2. 같다(=) 조건'이 아주 아주 약간 더 빠릅니다.(각 실행계획 가장 위의 actual time) 거의 사람이 차이를 느낄 수 없는 속도일듯합니다. 실제 실행해 보면 1번과 2번 모두 0.000초 정도입니다. 다만, '1. 범위 조건'의 경우는 Filter 라는 단계가 실행계획 중간에 끼어 들어옵니다. '3. 컬럼 변경'의 경우만 0.2초 정도의 시간이 걸립니다.
정리하면 아래와 같습니다.
- 범위 조건을 인덱스로 처리하면, 실행 계획에 Index range scan 으로 표시된다.
- 같다 조건을 인덱스로 처리하면, 실행 계획에 Index lookup 으로 표시된다.
- Index range scan과 Index lookup은 수직적 탐색과 수평적 탐색이 발생하는 같은 작업이라고 볼 수 있습니다.
- Index scan은 인덱스 리프 노드를 순차적으로 모두 읽는 작업이다.
- 당연히, Index scan은 Index range scan이나 Index lookup 보다 성능이 좋지 못할 수 있다.
- Index scan은 오라클의 Index full scan이다.
- Index scan이 나왔다고 인덱스를 '효율적'으로 사용했다고 착각하지 말자.!

이정도일거 같습니다. 감사합니다.


'SQL > MySQL' 카테고리의 다른 글
| [MySQL튜닝]힌트-해시 조인 (0) | 2023.01.02 |
|---|---|
| [MySQL튜닝]힌트-조인순서 (0) | 2022.12.14 |
| [MySQL튜닝]넌클러스터드에서 클러스터드로 (0) | 2022.11.16 |
| [MySQL튜닝]MySQL의 인덱스 실행 계획 #2 (0) | 2022.11.15 |
| [MySQL튜닝]인덱스 탐색 (0) | 2022.11.01 |
| [MySQL튜닝]Non Clustered vs. Clustered #2 (0) | 2022.10.26 |
| [MySQL튜닝]Non Clustered vs. Clustered #1 (0) | 2022.10.26 |
| [MySQL튜닝]B Tree 인덱스 (0) | 2022.10.24 |